 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAMLOCK: HArdware-Model LOgically Combined attacK
Oct 22, 2025The growing use of third-party hardware accelerators (e.g., FPGAs, ASICs) for deep neural networks (DNNs) introduces new security vulnerabilities. Conventional model-level backdoor attacks, which only poison a model's weights to misclassify inputs with a specific trigger, are often detectable because the entire attack logic is embedded within the model (i.e., software), creating a traceable layer-by-layer activation path. This paper introduces the HArdware-Model Logically Combined Attack (HAMLOCK), a far stealthier threat that distributes the attack logic across the hardware-software boundary. The software (model) is now only minimally altered by tuning the activations of few neurons to produce uniquely high activation values when a trigger is present. A malicious hardware Trojan detects those unique activations by monitoring the corresponding neurons' most significant bit or the 8-bit exponents and triggers another hardware Trojan to directly manipulate the final output logits for misclassification. This decoupled design is highly stealthy, as the model itself contains no complete backdoor activation path as in conventional attacks and hence, appears fully benign. Empirically, across benchmarks like MNIST, CIFAR10, GTSRB, and ImageNet, HAMLOCK achieves a near-perfect attack success rate with a negligible clean accuracy drop. More importantly, HAMLOCK circumvents the state-of-the-art model-level defenses without any adaptive optimization. The hardware Trojan is also undetectable, incurring area and power overheads as low as 0.01%, which is easily masked by process and environmental noise. Our findings expose a critical vulnerability at the hardware-software interface, demanding new cross-layer defenses against this emerging threat.
Adversarial Hubness in Multi-Modal Retrieval
Dec 18, 2024Hubness is a phenomenon in high-dimensional vector spaces where a single point from the natural distribution is unusually close to many other points. This is a well-known problem in information retrieval that causes some items to accidentally (and incorrectly) appear relevant to many queries. In this paper, we investigate how attackers can exploit hubness to turn any image or audio input in a multi-modal retrieval system into an adversarial hub. Adversarial hubs can be used to inject universal adversarial content (e.g., spam) that will be retrieved in response to thousands of different queries, as well as for targeted attacks on queries related to specific, attacker-chosen concepts. We present a method for creating adversarial hubs and evaluate the resulting hubs on benchmark multi-modal retrieval datasets and an image-to-image retrieval system based on a tutorial from Pinecone, a popular vector database. For example, in text-caption-to-image retrieval, a single adversarial hub is retrieved as the top-1 most relevant image for more than 21,000 out of 25,000 test queries (by contrast, the most common natural hub is the top-1 response to only 102 queries). We also investigate whether techniques for mitigating natural hubness are an effective defense against adversarial hubs, and show that they are not effective against hubs that target queries related to specific concepts.
Understanding Variation in Subpopulation Susceptibility to Poisoning Attacks
Nov 20, 2023Machine learning is susceptible to poisoning attacks, in which an attacker controls a small fraction of the training data and chooses that data with the goal of inducing some behavior unintended by the model developer in the trained model. We consider a realistic setting in which the adversary with the ability to insert a limited number of data points attempts to control the model's behavior on a specific subpopulation. Inspired by previous observations on disparate effectiveness of random label-flipping attacks on different subpopulations, we investigate the properties that can impact the effectiveness of state-of-the-art poisoning attacks against different subpopulations. For a family of 2-dimensional synthetic datasets, we empirically find that dataset separability plays a dominant role in subpopulation vulnerability for less separable datasets. However, well-separated datasets exhibit more dependence on individual subpopulation properties. We further discover that a crucial subpopulation property is captured by the difference in loss on the clean dataset between the clean model and a target model that misclassifies the subpopulation, and a subpopulation is much easier to attack if the loss difference is small. This property also generalizes to high-dimensional benchmark datasets. For the Adult benchmark dataset, we show that we can find semantically-meaningful subpopulation properties that are related to the susceptibilities of a selected group of subpopulations. The results in this paper are accompanied by a fully interactive web-based visualization of subpopulation poisoning attacks found at https://uvasrg.github.io/visualizing-poisoning
SoK: Pitfalls in Evaluating Black-Box Attacks
Oct 26, 2023
Numerous works study black-box attacks on image classifiers. However, these works make different assumptions on the adversary's knowledge and current literature lacks a cohesive organization centered around the threat model. To systematize knowledge in this area, we propose a taxonomy over the threat space spanning the axes of feedback granularity, the access of interactive queries, and the quality and quantity of the auxiliary data available to the attacker. Our new taxonomy provides three key insights. 1) Despite extensive literature, numerous under-explored threat spaces exist, which cannot be trivially solved by adapting techniques from well-explored settings. We demonstrate this by establishing a new state-of-the-art in the less-studied setting of access to top-k confidence scores by adapting techniques from well-explored settings of accessing the complete confidence vector, but show how it still falls short of the more restrictive setting that only obtains the prediction label, highlighting the need for more research. 2) Identification the threat model of different attacks uncovers stronger baselines that challenge prior state-of-the-art claims. We demonstrate this by enhancing an initially weaker baseline (under interactive query access) via surrogate models, effectively overturning claims in the respective paper. 3) Our taxonomy reveals interactions between attacker knowledge that connect well to related areas, such as model inversion and extraction attacks. We discuss how advances in other areas can enable potentially stronger black-box attacks. Finally, we emphasize the need for a more realistic assessment of attack success by factoring in local attack runtime. This approach reveals the potential for certain attacks to achieve notably higher success rates and the need to evaluate attacks in diverse and harder settings, highlighting the need for better selection criteria.
When Can Linear Learners be Robust to Indiscriminate Poisoning Attacks?
Jul 03, 2023



We study indiscriminate poisoning for linear learners where an adversary injects a few crafted examples into the training data with the goal of forcing the induced model to incur higher test error. Inspired by the observation that linear learners on some datasets are able to resist the best known attacks even without any defenses, we further investigate whether datasets can be inherently robust to indiscriminate poisoning attacks for linear learners. For theoretical Gaussian distributions, we rigorously characterize the behavior of an optimal poisoning attack, defined as the poisoning strategy that attains the maximum risk of the induced model at a given poisoning budget. Our results prove that linear learners can indeed be robust to indiscriminate poisoning if the class-wise data distributions are well-separated with low variance and the size of the constraint set containing all permissible poisoning points is also small. These findings largely explain the drastic variation in empirical attack performance of the state-of-the-art poisoning attacks on linear learners across benchmark datasets, making an important initial step towards understanding the underlying reasons some learning tasks are vulnerable to data poisoning attacks.
Manipulating Transfer Learning for Property Inference
Mar 21, 2023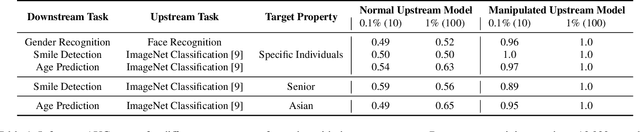
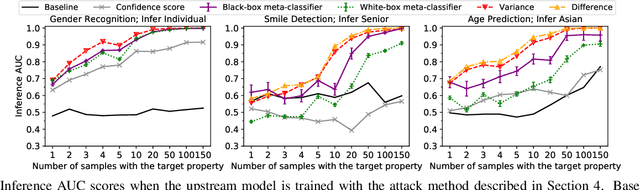
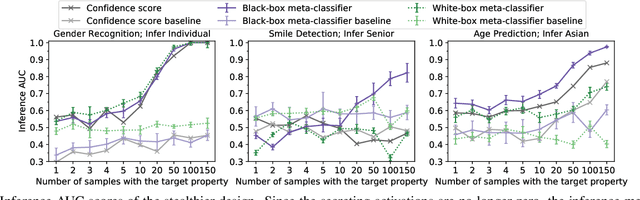
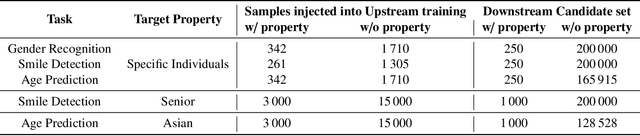
Transfer learning is a popular method for tuning pretrained (upstream) models for different downstream tasks using limited data and computational resources. We study how an adversary with control over an upstream model used in transfer learning can conduct property inference attacks on a victim's tuned downstream model. For example, to infer the presence of images of a specific individual in the downstream training set. We demonstrate attacks in which an adversary can manipulate the upstream model to conduct highly effective and specific property inference attacks (AUC score $> 0.9$), without incurring significant performance loss on the main task. The main idea of the manipulation is to make the upstream model generate activations (intermediate features) with different distributions for samples with and without a target property, thus enabling the adversary to distinguish easily between downstream models trained with and without training examples that have the target property. Our code is available at https://github.com/yulongt23/Transfer-Inference.
Stealthy Backdoors as Compression Artifacts
Apr 30, 2021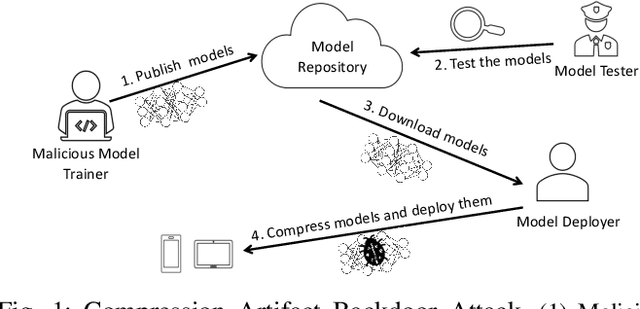
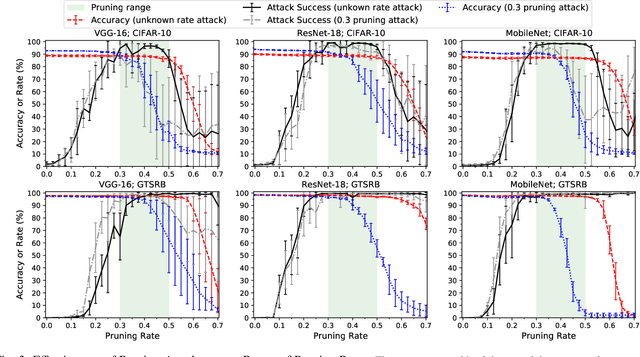

In a backdoor attack on a machine learning model, an adversary produces a model that performs well on normal inputs but outputs targeted misclassifications on inputs containing a small trigger pattern. Model compression is a widely-used approach for reducing the size of deep learning models without much accuracy loss, enabling resource-hungry models to be compressed for use on resource-constrained devices. In this paper, we study the risk that model compression could provide an opportunity for adversaries to inject stealthy backdoors. We design stealthy backdoor attacks such that the full-sized model released by adversaries appears to be free from backdoors (even when tested using state-of-the-art techniques), but when the model is compressed it exhibits highly effective backdoors. We show this can be done for two common model compression techniques -- model pruning and model quantization. Our findings demonstrate how an adversary may be able to hide a backdoor as a compression artifact, and show the importance of performing security tests on the models that will actually be deployed not their precompressed version.
Model-Targeted Poisoning Attacks: Provable Convergence and Certified Bounds
Jun 30, 2020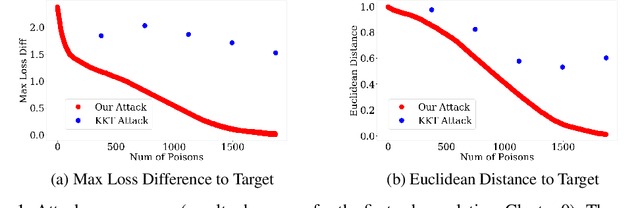



Machine learning systems that rely on training data collected from untrusted sources are vulnerable to poisoning attacks, in which adversaries controlling some of the collected data are able to induce a corrupted model. In this paper, we consider poisoning attacks where there is an adversary who has a particular target classifier in mind and hopes to induce a classifier close to that target by adding as few poisoning points as possible. We propose an efficient poisoning attack based on online convex optimization. Unlike previous model-targeted poisoning attacks, our attack comes with provable convergence to any achievable target classifier. The distance from the induced classifier to the target classifier is inversely proportional to the square root of the number of poisoning points. We also provide a certified lower bound on the minimum number of poisoning points needed to achieve a given target classifier. We report on experiments showing our attack has performance that is similar to or better than the state-of-the-art attacks in terms of attack success rate and distance to the target model, while providing the advantages of provable convergence, and the efficiency benefits associated with being an online attack that can determine near-optimal poisoning points incrementally.
Scalable Attack on Graph Data by Injecting Vicious Nodes
Apr 22, 2020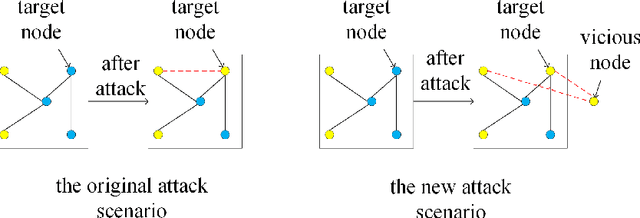
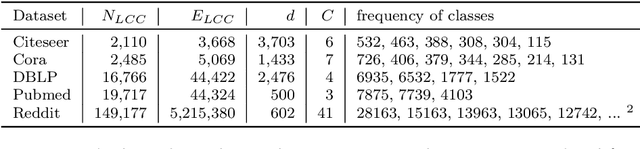

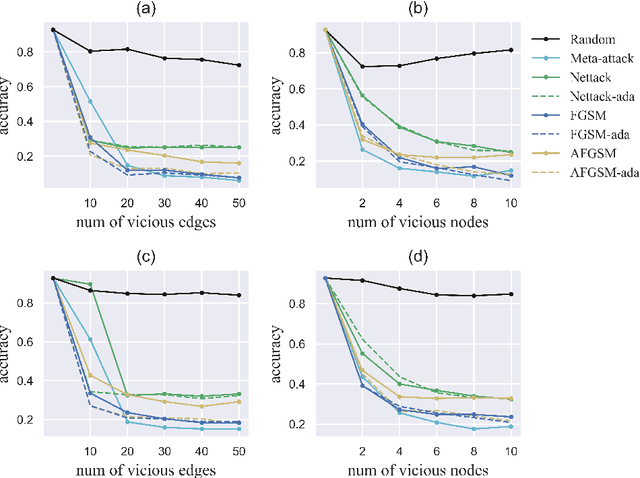
Recent studies have shown that graph convolution networks (GCNs) are vulnerable to carefully designed attacks, which aim to cause misclassification of a specific node on the graph with unnoticeable perturbations. However, a vast majority of existing works cannot handle large-scale graphs because of their high time complexity. Additionally, existing works mainly focus on manipulating existing nodes on the graph, while in practice, attackers usually do not have the privilege to modify information of existing nodes. In this paper, we develop a more scalable framework named Approximate Fast Gradient Sign Method (AFGSM) which considers a more practical attack scenario where adversaries can only inject new vicious nodes to the graph while having no control over the original graph. Methodologically, we provide an approximation strategy to linearize the model we attack and then derive an approximate closed-from solution with a lower time cost. To have a fair comparison with existing attack methods that manipulate the original graph, we adapt them to the new attack scenario by injecting vicious nodes. Empirical experimental results show that our proposed attack method can significantly reduce the classification accuracy of GCNs and is much faster than existing methods without jeopardizing the attack performance.
Query-limited Black-box Attacks to Classifiers
Dec 23, 2017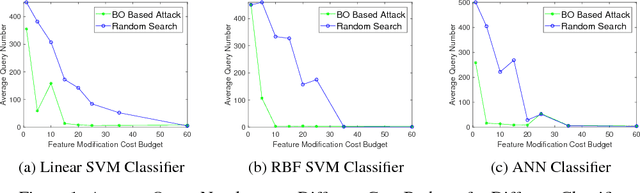
We study black-box attacks on machine learning classifiers where each query to the model incurs some cost or risk of detection to the adversary. We focus explicitly on minimizing the number of queries as a major objective. Specifically, we consider the problem of attacking machine learning classifiers subject to a budget of feature modification cost while minimizing the number of queries, where each query returns only a class and confidence score. We describe an approach that uses Bayesian optimization to minimize the number of queries, and find that the number of queries can be reduced to approximately one tenth of the number needed through a random strategy for scenarios where the feature modification cost budget is low.