 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhance the after-discharge mortality rate prediction via learning from the medical notes
May 05, 2026With the increase of the Electronic Health Records (EHR) data, more and more researchers are developing machine learning models to learn from the medical notes. These unstructured text data pose significant challenges on the learning process as the quality of data is low. These data are often messy, repetitive and redundant. We have shown these notes data to be informative by conducting the after-discharge mortality rate prediction task. The AUC-ROC for models using the medical note information is generally 0.1 higher than those without the medical notes. Furthermore, we propose the Deep Neural Network(DNN) model with 'pooling' mechanism to enhance the mortality prediction. Based on the experimental results, we demonstrate that the proposed model outperforms the traditional machine learning models like the tree-based models. The proposed method learns from the most informative medical notes and improves the prediction accuracy significantly. The AUC-ROC for the proposed model is 2% to 14% higher than the traditional ones in 15-days, 30-days, 60-days, 365-days after-discharge mortality prediction tasks. Moreover, we can discover some interesting knowledge through the traditional and proposed models. These knowledge are inspiring but also consistent with the previous findings. The models are able to reveal the relationships between the informative keywords and documents from the medical notes and the severity of the patients.
Robust Reward Modeling for Large Language Models via Causal Decomposition
Apr 16, 2026Reward models are central to aligning large language models, yet they often overfit to spurious cues such as response length and overly agreeable tone. Most prior work weakens these cues directly by penalizing or controlling specific artifacts, but it does not explicitly encourage the model to ground preferences in the prompt's intent. We learn a decoder that maps a candidate answer to the latent intent embedding of the input. The reconstruction error is used as a signal to regularize the reward model training. We provide theoretical evidence that this signal emphasizes prompt-dependent information while suppressing prompt-independent shortcuts. Across math, helpfulness, and safety benchmarks, the decoder selects shorter and less sycophantic candidates with 0.877 accuracy. Incorporating this signal into RM training in Gemma-2-2B-it and Gemma-2-9B-it increases RewardBench accuracy from 0.832 to 0.868. For Best-of-N selection, our framework increases length-controlled win rates while producing shorter outputs, and remains robust to lengthening and mild off-topic drift in controlled rewrite tests.
Provably Safe Trajectory Generation for Manipulators Under Motion and Environmental Uncertainties
Mar 10, 2026Robot manipulators operating in uncertain and non-convex environments present significant challenges for safe and optimal motion planning. Existing methods often struggle to provide efficient and formally certified collision risk guarantees, particularly when dealing with complex geometries and non-Gaussian uncertainties. This article proposes a novel risk-bounded motion planning framework to address this unmet need. Our approach integrates a rigid manipulator deep stochastic Koopman operator (RM-DeSKO) model to robustly predict the robot's state distribution under motion uncertainty. We then introduce an efficient, hierarchical verification method that combines parallelizable physics simulations with sum-of-squares (SOS) programming as a filter for fine-grained, formal certification of collision risk. This method is embedded within a Model Predictive Path Integral (MPPI) controller that uniquely utilizes binary collision information from SOS decomposition to improve its policy. The effectiveness of the proposed framework is validated on two typical robot manipulators through extensive simulations and real-world experiments, including a challenging human-robot collaboration scenario, demonstrating sim-to-real transfer of the learned model and its ability to generate safe and efficient trajectories in complex, uncertain settings.
DeNuC: Decoupling Nuclei Detection and Classification in Histopathology
Mar 04, 2026Pathology Foundation Models (FMs) have shown strong performance across a wide range of pathology image representation and diagnostic tasks. However, FMs do not exhibit the expected performance advantage over traditional specialized models in Nuclei Detection and Classification (NDC). In this work, we reveal that jointly optimizing nuclei detection and classification leads to severe representation degradation in FMs. Moreover, we identify that the substantial intrinsic disparity in task difficulty between nuclei detection and nuclei classification renders joint NDC optimization unnecessarily computationally burdensome for the detection stage. To address these challenges, we propose DeNuC, a simple yet effective method designed to break through existing bottlenecks by Decoupling Nuclei detection and Classification. DeNuC employs a lightweight model for accurate nuclei localization, subsequently leveraging a pathology FM to encode input images and query nucleus-specific features based on the detected coordinates for classification. Extensive experiments on three widely used benchmarks demonstrate that DeNuC effectively unlocks the representational potential of FMs for NDC and significantly outperforms state-of-the-art methods. Notably, DeNuC improves F1 scores by 4.2% and 3.6% (or higher) on the BRCAM2C and PUMA datasets, respectively, while using only 16% (or fewer) trainable parameters compared to other methods. Code is available at https://github.com/ZijiangY1116/DeNuC.
FAVLA: A Force-Adaptive Fast-Slow VLA model for Contact-Rich Robotic Manipulation
Feb 27, 2026Force/torque feedback can substantially improve Vision-Language-Action (VLA) models on contact-rich manipulation, but most existing approaches fuse all modalities at a single operating frequency. This design ignores the mismatched sampling rates of real robot sensors, forcing downsampling of the high-frequency contact cues needed for reactive correction. Combined with common VLM-action-expert (AE) pipelines that execute action chunks largely open loop between expensive VLM updates, unified-frequency fusion often yields delayed responses to impacts, stick-slip, and force spikes. We propose FAVLA, a force-adaptive fast-slow VLA that decouples slow perception planning from fast contact-aware control. FAVLA runs a slow VLM at a fixed low frequency to encode modalities to produce latent representations and to predict near-future force variation. A fast AE then executes at a variable high frequency, conditioning on the latest force sequence data to generate reactive actions. We further introduce a force adapter that injects high-frequency force features into multiple AE layers, and adaptively schedules the AE's execution frequency based on the VLM's predicted force variation. Extensive experiments on contact-rich tasks demonstrate that FAVLA significantly outperforms baselines, achieving superior reactivity and success rates, especially with a smaller contact force during manipulation.
Long-only cryptocurrency portfolio management by ranking the assets: a neural network approach
Dec 09, 2025This paper will propose a novel machine learning based portfolio management method in the context of the cryptocurrency market. Previous researchers mainly focus on the prediction of the movement for specific cryptocurrency such as the bitcoin(BTC) and then trade according to the prediction. In contrast to the previous work that treats the cryptocurrencies independently, this paper manages a group of cryptocurrencies by analyzing the relative relationship. Specifically, in each time step, we utilize the neural network to predict the rank of the future return of the managed cryptocurrencies and place weights accordingly. By incorporating such cross-sectional information, the proposed methods is shown to profitable based on the backtesting experiments on the real daily cryptocurrency market data from May, 2020 to Nov, 2023. During this 3.5 years, the market experiences the full cycle of bullish, bearish and stagnant market conditions. Despite under such complex market conditions, the proposed method outperforms the existing methods and achieves a Sharpe ratio of 1.01 and annualized return of 64.26%. Additionally, the proposed method is shown to be robust to the increase of transaction fee.
MUSE: Multi-Scale Dense Self-Distillation for Nucleus Detection and Classification
Nov 07, 2025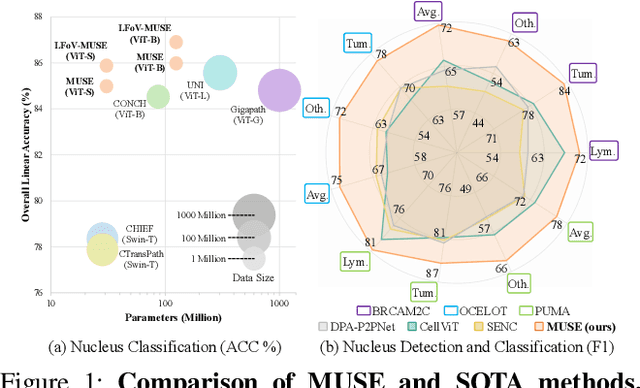
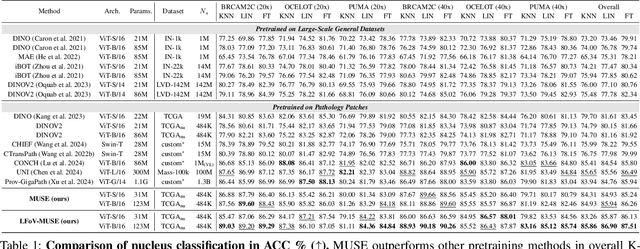
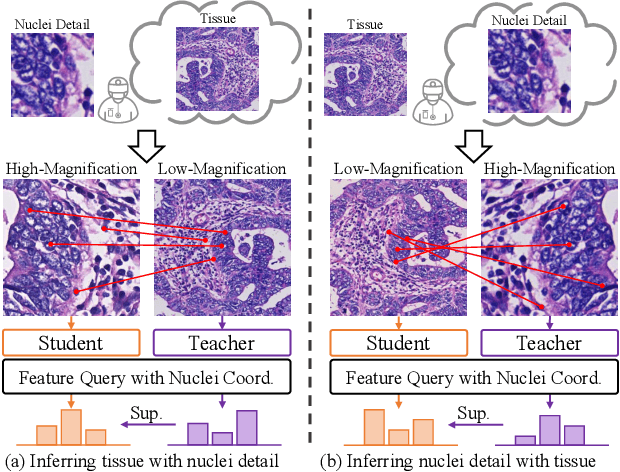
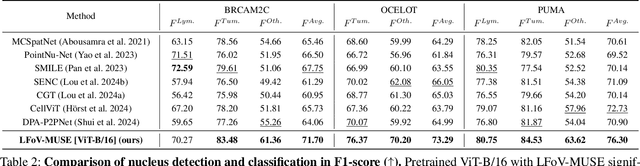
Nucleus detection and classification (NDC) in histopathology analysis is a fundamental task that underpins a wide range of high-level pathology applications. However, existing methods heavily rely on labor-intensive nucleus-level annotations and struggle to fully exploit large-scale unlabeled data for learning discriminative nucleus representations. In this work, we propose MUSE (MUlti-scale denSE self-distillation), a novel self-supervised learning method tailored for NDC. At its core is NuLo (Nucleus-based Local self-distillation), a coordinate-guided mechanism that enables flexible local self-distillation based on predicted nucleus positions. By removing the need for strict spatial alignment between augmented views, NuLo allows critical cross-scale alignment, thus unlocking the capacity of models for fine-grained nucleus-level representation. To support MUSE, we design a simple yet effective encoder-decoder architecture and a large field-of-view semi-supervised fine-tuning strategy that together maximize the value of unlabeled pathology images. Extensive experiments on three widely used benchmarks demonstrate that MUSE effectively addresses the core challenges of histopathological NDC. The resulting models not only surpass state-of-the-art supervised baselines but also outperform generic pathology foundation models.
Neural Proteomics Fields for Super-resolved Spatial Proteomics Prediction
Aug 24, 2025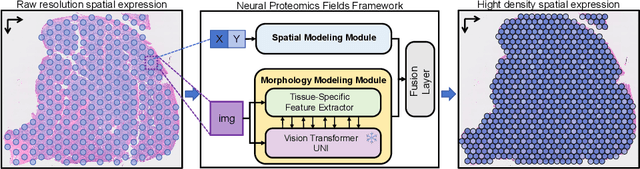
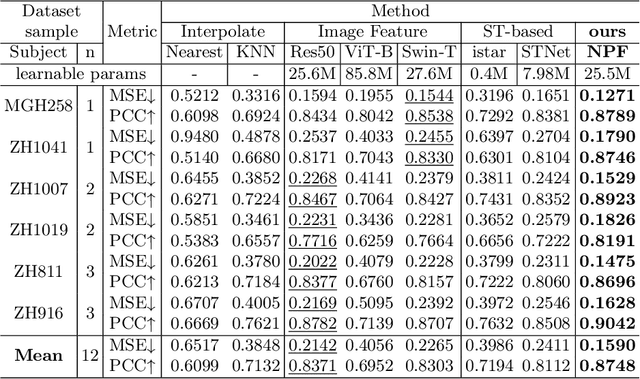
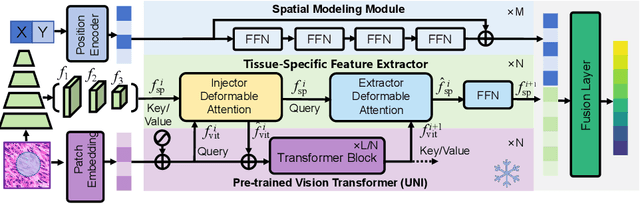

Spatial proteomics maps protein distributions in tissues, providing transformative insights for life sciences. However, current sequencing-based technologies suffer from low spatial resolution, and substantial inter-tissue variability in protein expression further compromises the performance of existing molecular data prediction methods. In this work, we introduce the novel task of spatial super-resolution for sequencing-based spatial proteomics (seq-SP) and, to the best of our knowledge, propose the first deep learning model for this task--Neural Proteomics Fields (NPF). NPF formulates seq-SP as a protein reconstruction problem in continuous space by training a dedicated network for each tissue. The model comprises a Spatial Modeling Module, which learns tissue-specific protein spatial distributions, and a Morphology Modeling Module, which extracts tissue-specific morphological features. Furthermore, to facilitate rigorous evaluation, we establish an open-source benchmark dataset, Pseudo-Visium SP, for this task. Experimental results demonstrate that NPF achieves state-of-the-art performance with fewer learnable parameters, underscoring its potential for advancing spatial proteomics research. Our code and dataset are publicly available at https://github.com/Bokai-Zhao/NPF.
On-Demand Scenario Generation for Testing Automated Driving Systems
May 20, 2025The safety and reliability of Automated Driving Systems (ADS) are paramount, necessitating rigorous testing methodologies to uncover potential failures before deployment. Traditional testing approaches often prioritize either natural scenario sampling or safety-critical scenario generation, resulting in overly simplistic or unrealistic hazardous tests. In practice, the demand for natural scenarios (e.g., when evaluating the ADS's reliability in real-world conditions), critical scenarios (e.g., when evaluating safety in critical situations), or somewhere in between (e.g., when testing the ADS in regions with less civilized drivers) varies depending on the testing objectives. To address this issue, we propose the On-demand Scenario Generation (OSG) Framework, which generates diverse scenarios with varying risk levels. Achieving the goal of OSG is challenging due to the complexity of quantifying the criticalness and naturalness stemming from intricate vehicle-environment interactions, as well as the need to maintain scenario diversity across various risk levels. OSG learns from real-world traffic datasets and employs a Risk Intensity Regulator to quantitatively control the risk level. It also leverages an improved heuristic search method to ensure scenario diversity. We evaluate OSG on the Carla simulators using various ADSs. We verify OSG's ability to generate scenarios with different risk levels and demonstrate its necessity by comparing accident types across risk levels. With the help of OSG, we are now able to systematically and objectively compare the performance of different ADSs based on different risk levels.
MAD-UV: The 1st INTERSPEECH Mice Autism Detection via Ultrasound Vocalization Challenge
Jan 08, 2025


The Mice Autism Detection via Ultrasound Vocalization (MAD-UV) Challenge introduces the first INTERSPEECH challenge focused on detecting autism spectrum disorder (ASD) in mice through their vocalizations. Participants are tasked with developing models to automatically classify mice as either wild-type or ASD models based on recordings with a high sampling rate. Our baseline system employs a simple CNN-based classification using three different spectrogram features. Results demonstrate the feasibility of automated ASD detection, with the considered audible-range features achieving the best performance (UAR of 0.600 for segment-level and 0.625 for subject-level classification). This challenge bridges speech technology and biomedical research, offering opportunities to advance our understanding of ASD models through machine learning approaches. The findings suggest promising directions for vocalization analysis and highlight the potential value of audible and ultrasound vocalizations in ASD detection.