 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Demand Scenario Generation for Testing Automated Driving Systems
May 20, 2025The safety and reliability of Automated Driving Systems (ADS) are paramount, necessitating rigorous testing methodologies to uncover potential failures before deployment. Traditional testing approaches often prioritize either natural scenario sampling or safety-critical scenario generation, resulting in overly simplistic or unrealistic hazardous tests. In practice, the demand for natural scenarios (e.g., when evaluating the ADS's reliability in real-world conditions), critical scenarios (e.g., when evaluating safety in critical situations), or somewhere in between (e.g., when testing the ADS in regions with less civilized drivers) varies depending on the testing objectives. To address this issue, we propose the On-demand Scenario Generation (OSG) Framework, which generates diverse scenarios with varying risk levels. Achieving the goal of OSG is challenging due to the complexity of quantifying the criticalness and naturalness stemming from intricate vehicle-environment interactions, as well as the need to maintain scenario diversity across various risk levels. OSG learns from real-world traffic datasets and employs a Risk Intensity Regulator to quantitatively control the risk level. It also leverages an improved heuristic search method to ensure scenario diversity. We evaluate OSG on the Carla simulators using various ADSs. We verify OSG's ability to generate scenarios with different risk levels and demonstrate its necessity by comparing accident types across risk levels. With the help of OSG, we are now able to systematically and objectively compare the performance of different ADSs based on different risk levels.
Adversarial Safety-Critical Scenario Generation using Naturalistic Human Driving Priors
Aug 07, 2024
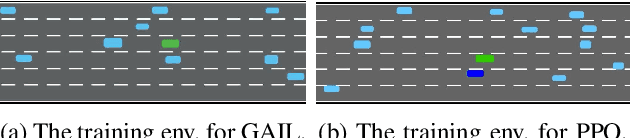
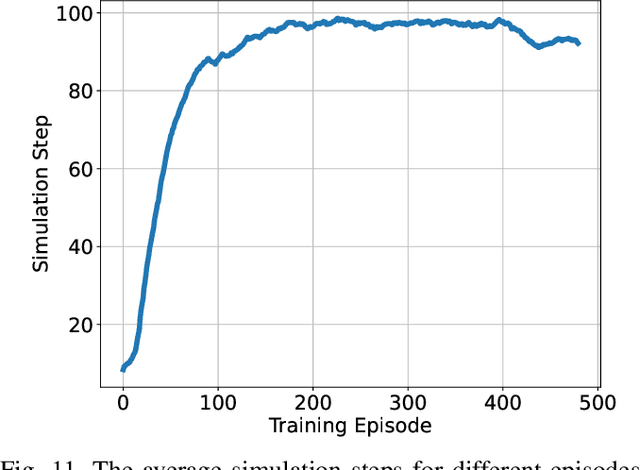
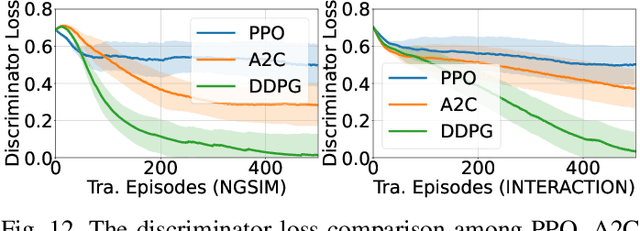
Evaluating the decision-making system is indispensable in developing autonomous vehicles, while realistic and challenging safety-critical test scenarios play a crucial role. Obtaining these scenarios is non-trivial, thanks to the long-tailed distribution, sparsity, and rarity in real-world data sets. To tackle this problem, in this paper, we introduce a natural adversarial scenario generation solution using naturalistic human driving priors and reinforcement learning techniques. By doing this, we can obtain large-scale test scenarios that are both diverse and realistic. Specifically, we build a simulation environment that mimics natural traffic interaction scenarios. Informed by this environment, we implement a two-stage procedure. The first stage incorporates conventional rule-based models, e.g., IDM~(Intelligent Driver Model) and MOBIL~(Minimizing Overall Braking Induced by Lane changes) model, to coarsely and discretely capture and calibrate key control parameters from the real-world dataset. Next, we leverage GAIL~(Generative Adversarial Imitation Learning) to represent driver behaviors continuously. The derived GAIL can be further used to design a PPO~(Proximal Policy Optimization)-based actor-critic network framework to fine-tune the reward function, and then optimizes our natural adversarial scenario generation solution. Extensive experiments have been conducted in the NGSIM dataset including the trajectory of 3,000 vehicles. Essential traffic parameters were measured in comparison with the baseline model, e.g., the collision rate, accelerations, steering, and the number of lane changes. Our findings demonstrate that the proposed model can generate realistic safety-critical test scenarios covering both naturalness and adversariality, which can be a cornerstone for the development of autonomous vehicles.
* Published in IEEE Transactions on Intelligent Vehicles, 2023
Plant Disease Recognition Datasets in the Age of Deep Learning: Challenges and Opportunities
Dec 13, 2023Plant disease recognition has witnessed a significant improvement with deep learning in recent years. Although plant disease datasets are essential and many relevant datasets are public available, two fundamental questions exist. First, how to differentiate datasets and further choose suitable public datasets for specific applications? Second, what kinds of characteristics of datasets are desired to achieve promising performance in real-world applications? To address the questions, this study explicitly propose an informative taxonomy to describe potential plant disease datasets. We further provide several directions for future, such as creating challenge-oriented datasets and the ultimate objective deploying deep learning in real-world applications with satisfactory performance. In addition, existing related public RGB image datasets are summarized. We believe that this study will contributing making better datasets and that this study will contribute beyond plant disease recognition such as plant species recognition. To facilitate the community, our project is public https://github.com/xml94/PPDRD with the information of relevant public datasets.
Embracing Limited and Imperfect Data: A Review on Plant Stress Recognition Using Deep Learning
May 19, 2023Plant stress recognition has witnessed significant improvements in recent years with the advent of deep learning. A large-scale and annotated training dataset is required to achieve decent performance; however, collecting it is frequently difficult and expensive. Therefore, deploying current deep learning-based methods in real-world applications may suffer primarily from limited and imperfect data. Embracing them is a promising strategy that has not received sufficient attention. From this perspective, a systematic survey was conducted in this study, with the ultimate objective of monitoring plant growth by implementing deep learning, which frees humans and potentially reduces the resultant losses from plant stress. We believe that our paper has highlighted the importance of embracing this limited and imperfect data and enhanced its relevant understanding.
Exploiting Dynamic and Fine-grained Semantic Scope for Extreme Multi-label Text Classification
May 24, 2022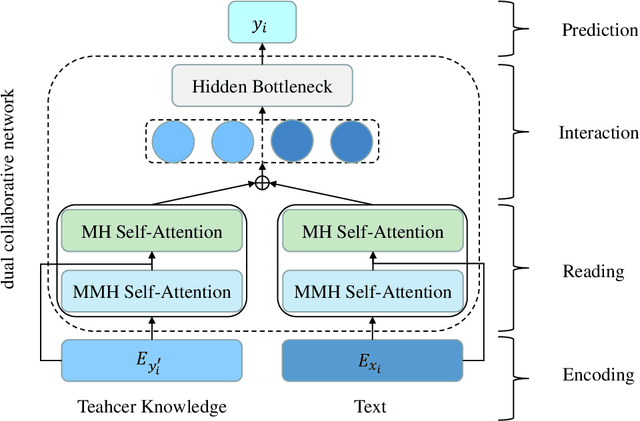

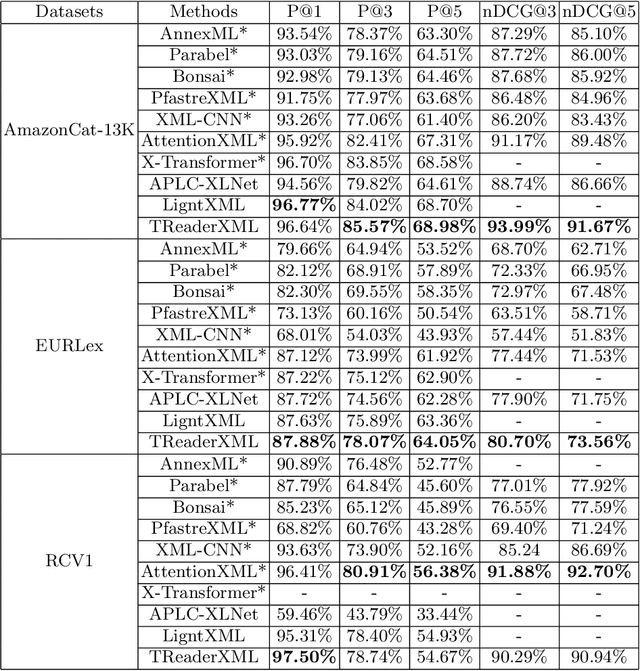
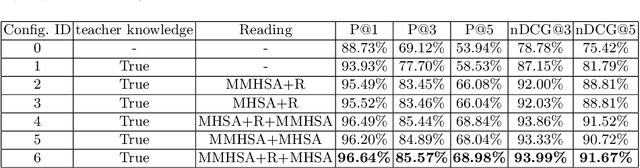
Extreme multi-label text classification (XMTC) refers to the problem of tagging a given text with the most relevant subset of labels from a large label set. A majority of labels only have a few training instances due to large label dimensionality in XMTC. To solve this data sparsity issue, most existing XMTC methods take advantage of fixed label clusters obtained in early stage to balance performance on tail labels and head labels. However, such label clusters provide static and coarse-grained semantic scope for every text, which ignores distinct characteristics of different texts and has difficulties modelling accurate semantics scope for texts with tail labels. In this paper, we propose a novel framework TReaderXML for XMTC, which adopts dynamic and fine-grained semantic scope from teacher knowledge for individual text to optimize text conditional prior category semantic ranges. TReaderXML dynamically obtains teacher knowledge for each text by similar texts and hierarchical label information in training sets to release the ability of distinctly fine-grained label-oriented semantic scope. Then, TReaderXML benefits from a novel dual cooperative network that firstly learns features of a text and its corresponding label-oriented semantic scope by parallel Encoding Module and Reading Module, secondly embeds two parts by Interaction Module to regularize the text's representation by dynamic and fine-grained label-oriented semantic scope, and finally find target labels by Prediction Module. Experimental results on three XMTC benchmark datasets show that our method achieves new state-of-the-art results and especially performs well for severely imbalanced and sparse datasets.