 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Retrieval and Classification of Real-Time Multi-Source Hurricane Evacuation Notices
Jan 07, 2024For an approaching disaster, the tracking of time-sensitive critical information such as hurricane evacuation notices is challenging in the United States. These notices are issued and distributed rapidly by numerous local authorities that may spread across multiple states. They often undergo frequent updates and are distributed through diverse online portals lacking standard formats. In this study, we developed an approach to timely detect and track the locally issued hurricane evacuation notices. The text data were collected mainly with a spatially targeted web scraping method. They were manually labeled and then classified using natural language processing techniques with deep learning models. The classification of mandatory evacuation notices achieved a high accuracy (recall = 96%). We used Hurricane Ian (2022) to illustrate how real-time evacuation notices extracted from local government sources could be redistributed with a Web GIS system. Our method applied to future hurricanes provides live data for situation awareness to higher-level government agencies and news media. The archived data helps scholars to study government responses toward weather warnings and individual behaviors influenced by evacuation history. The framework may be applied to other types of disasters for rapid and targeted retrieval, classification, redistribution, and archiving of real-time government orders and notifications.
Representation Learning for Continuous Action Spaces is Beneficial for Efficient Policy Learning
Nov 23, 2022


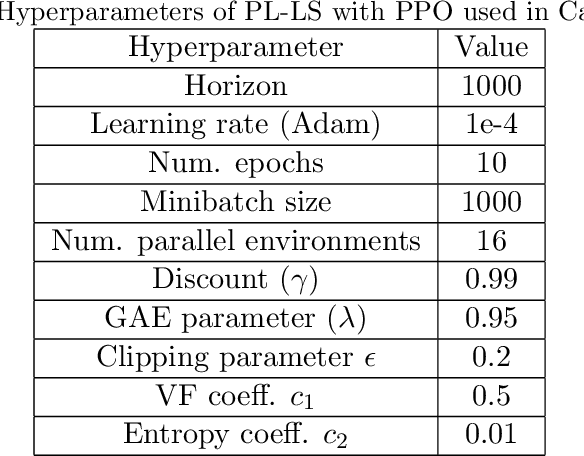
Deep reinforcement learning (DRL) breaks through the bottlenecks of traditional reinforcement learning (RL) with the help of the perception capability of deep learning and has been widely applied in real-world problems.While model-free RL, as a class of efficient DRL methods, performs the learning of state representations simultaneously with policy learning in an end-to-end manner when facing large-scale continuous state and action spaces. However, training such a large policy model requires a large number of trajectory samples and training time. On the other hand, the learned policy often fails to generalize to large-scale action spaces, especially for the continuous action spaces. To address this issue, in this paper we propose an efficient policy learning method in latent state and action spaces. More specifically, we extend the idea of state representations to action representations for better policy generalization capability. Meanwhile, we divide the whole learning task into learning with the large-scale representation models in an unsupervised manner and learning with the small-scale policy model in the RL manner.The small policy model facilitates policy learning, while not sacrificing generalization and expressiveness via the large representation model. Finally,the effectiveness of the proposed method is demonstrated by MountainCar,CarRacing and Cheetah experiments.
Cost-aware Generalized $α$-investing for Multiple Hypothesis Testing
Oct 31, 2022
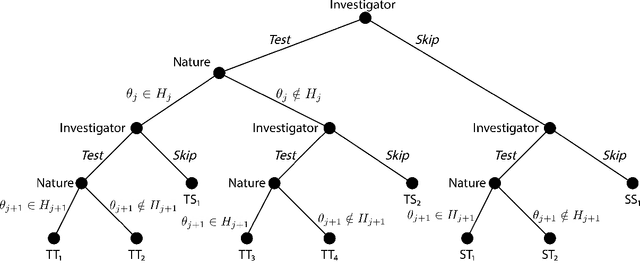
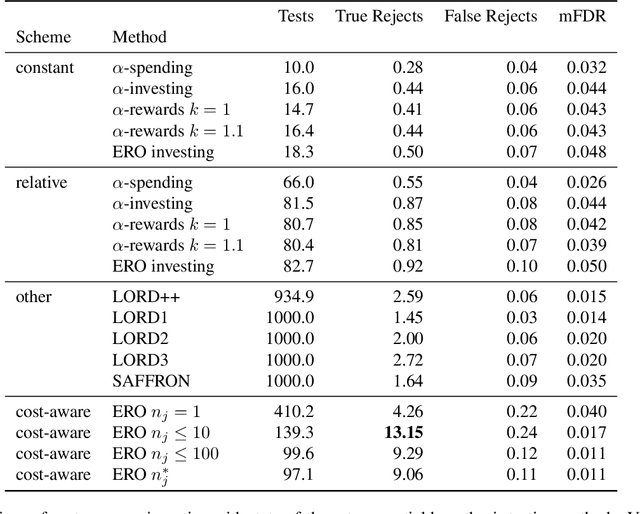
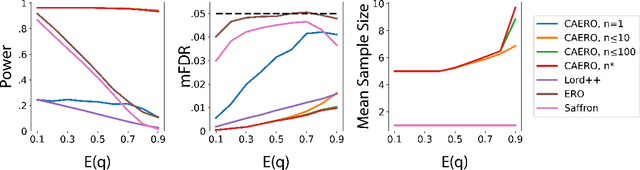
We consider the problem of sequential multiple hypothesis testing with nontrivial data collection cost. This problem appears, for example, when conducting biological experiments to identify differentially expressed genes in a disease process. This work builds on the generalized $\alpha$-investing framework that enables control of the false discovery rate in a sequential testing setting. We make a theoretical analysis of the long term asymptotic behavior of $\alpha$-wealth which motivates a consideration of sample size in the $\alpha$-investing decision rule. Using the game theoretic principle of indifference, we construct a decision rule that optimizes the expected return (ERO) of $\alpha$-wealth and provides an optimal sample size for the test. We show empirical results that a cost-aware ERO decision rule correctly rejects more false null hypotheses than other methods. We extend cost-aware ERO investing to finite-horizon testing which enables the decision rule to hedge against the risk of unproductive tests. Finally, empirical tests on a real data set from a biological experiment show that cost-aware ERO produces actionable decisions as to which tests to conduct and if so at what sample size.
Exploiting Dynamic and Fine-grained Semantic Scope for Extreme Multi-label Text Classification
May 24, 2022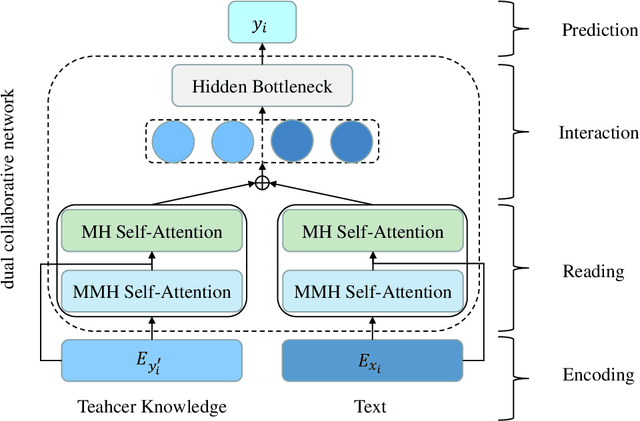

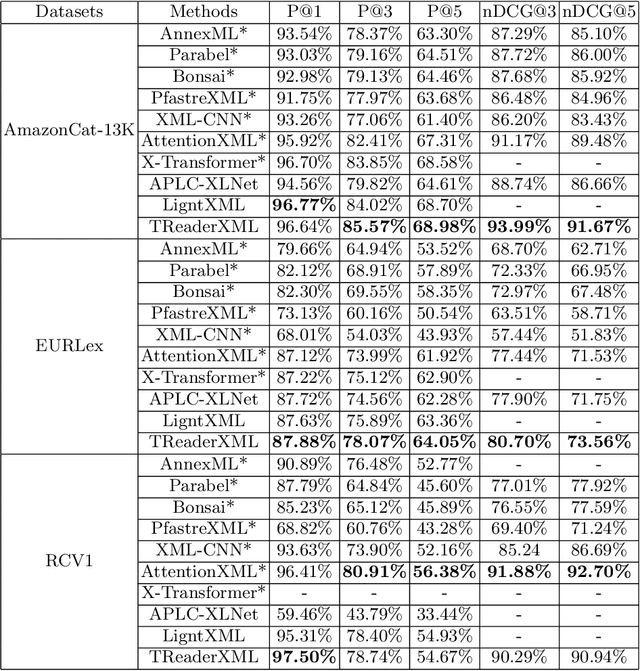
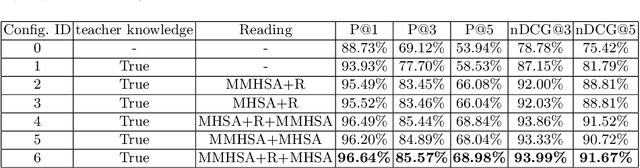
Extreme multi-label text classification (XMTC) refers to the problem of tagging a given text with the most relevant subset of labels from a large label set. A majority of labels only have a few training instances due to large label dimensionality in XMTC. To solve this data sparsity issue, most existing XMTC methods take advantage of fixed label clusters obtained in early stage to balance performance on tail labels and head labels. However, such label clusters provide static and coarse-grained semantic scope for every text, which ignores distinct characteristics of different texts and has difficulties modelling accurate semantics scope for texts with tail labels. In this paper, we propose a novel framework TReaderXML for XMTC, which adopts dynamic and fine-grained semantic scope from teacher knowledge for individual text to optimize text conditional prior category semantic ranges. TReaderXML dynamically obtains teacher knowledge for each text by similar texts and hierarchical label information in training sets to release the ability of distinctly fine-grained label-oriented semantic scope. Then, TReaderXML benefits from a novel dual cooperative network that firstly learns features of a text and its corresponding label-oriented semantic scope by parallel Encoding Module and Reading Module, secondly embeds two parts by Interaction Module to regularize the text's representation by dynamic and fine-grained label-oriented semantic scope, and finally find target labels by Prediction Module. Experimental results on three XMTC benchmark datasets show that our method achieves new state-of-the-art results and especially performs well for severely imbalanced and sparse datasets.
Deep Bayesian Unsupervised Lifelong Learning
Jun 13, 2021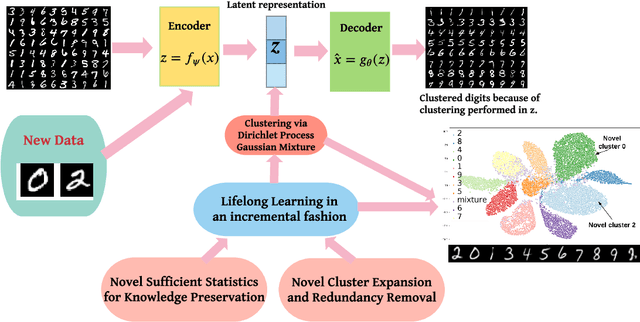

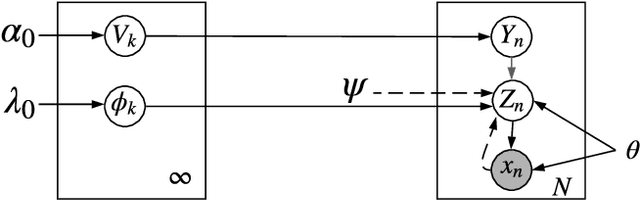
Lifelong Learning (LL) refers to the ability to continually learn and solve new problems with incremental available information over time while retaining previous knowledge. Much attention has been given lately to Supervised Lifelong Learning (SLL) with a stream of labelled data. In contrast, we focus on resolving challenges in Unsupervised Lifelong Learning (ULL) with streaming unlabelled data when the data distribution and the unknown class labels evolve over time. Bayesian framework is natural to incorporate past knowledge and sequentially update the belief with new data. We develop a fully Bayesian inference framework for ULL with a novel end-to-end Deep Bayesian Unsupervised Lifelong Learning (DBULL) algorithm, which can progressively discover new clusters without forgetting the past with unlabelled data while learning latent representations. To efficiently maintain past knowledge, we develop a novel knowledge preservation mechanism via sufficient statistics of the latent representation for raw data. To detect the potential new clusters on the fly, we develop an automatic cluster discovery and redundancy removal strategy in our inference inspired by Nonparametric Bayesian statistics techniques. We demonstrate the effectiveness of our approach using image and text corpora benchmark datasets in both LL and batch settings.
Identification of 27 abnormalities from multi-lead ECG signals: An ensembled Se-ResNet framework with Sign Loss function
Jan 12, 2021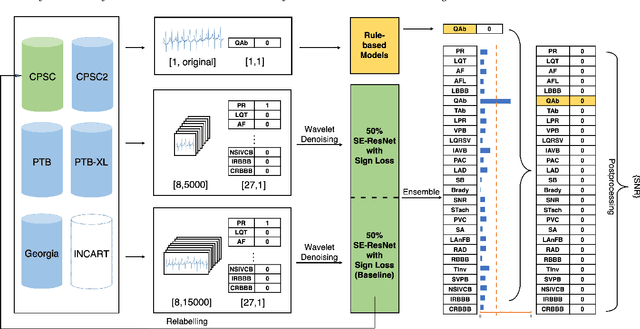
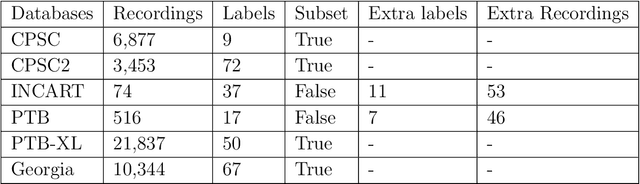
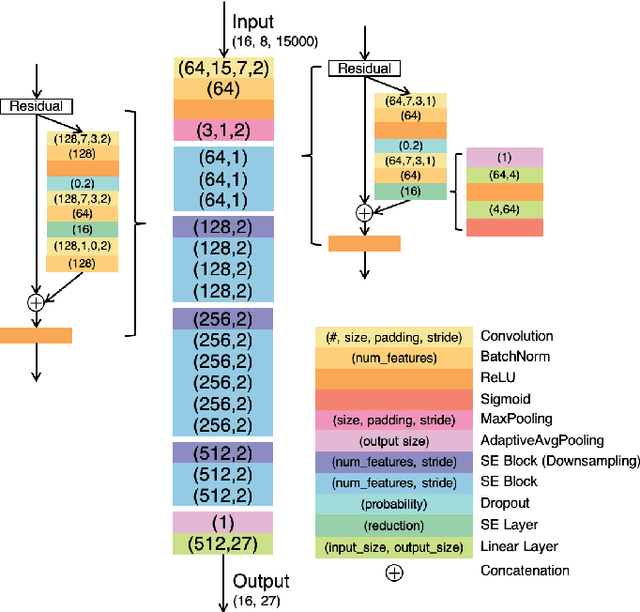
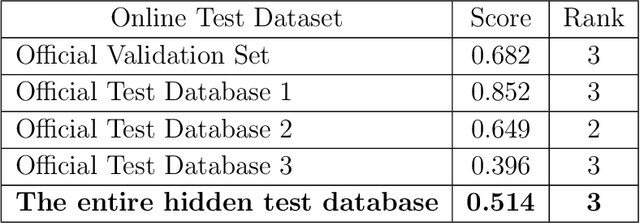
Cardiovascular disease is a major threat to health and one of the primary causes of death globally. The 12-lead ECG is a cheap and commonly accessible tool to identify cardiac abnormalities. Early and accurate diagnosis will allow early treatment and intervention to prevent severe complications of cardiovascular disease. In the PhysioNet/Computing in Cardiology Challenge 2020, our objective is to develop an algorithm that automatically identifies 27 ECG abnormalities from 12-lead ECG recordings.
A Computer Vision Application for Assessing Facial Acne Severity from Selfie Images
Jul 31, 2019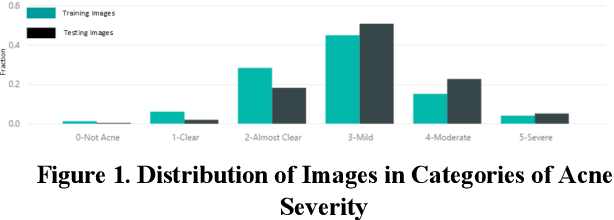

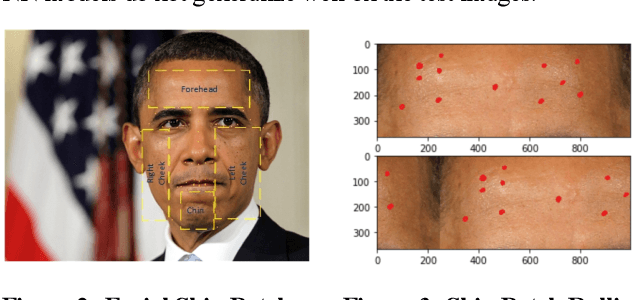
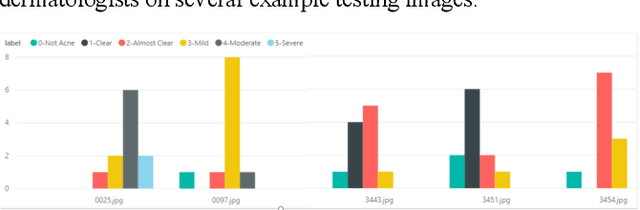
We worked with Nestle SHIELD (Skin Health, Innovation, Education, and Longevity Development, NSH) to develop a deep learning model that is able to assess acne severity from selfie images as accurate as dermatologists. The model was deployed as a mobile application, providing patients an easy way to assess and track the progress of their acne treatment. NSH acquired 4,700 selfie images for this study and recruited 11 internal dermatologists to label them in five categories: 1-Clear, 2- Almost Clear, 3-Mild, 4-Moderate, 5-Severe. Using OpenCV to detect facial landmarks we cut specific skin patches from the selfie images in order to minimize irrelevant background. We then applied a transfer learning approach by extracting features from the patches using a ResNet 152 pre-trained model, followed by a fully connected layer trained to approximate the desired severity rating. To address the problem of spatial sensitivity of CNN models, we introduce a new image rolling data augmentation approach, effectively causing acne lesions appeared in more locations in the training images. Our results demonstrate that this approach improved the generalization of the CNN model, outperforming more than half of the panel of human dermatologists on test images. To our knowledge, this is the first deep learning-based solution for acne assessment using selfie images.
Adaptive Nonparametric Variational Autoencoder
Jun 07, 2019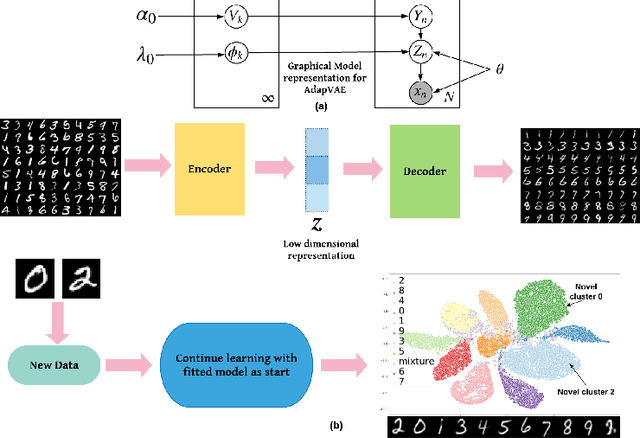



Clustering is used to find structure in unlabeled data by grouping similar objects together. Cluster analysis depends on the definition of similarity in the feature space. In this paper, we propose an Adaptive Nonparametric Variational Autoencoder (AdapVAE) to perform end-to-end feature learning from raw data jointly with cluster membership learning through a Nonparametric Bayesian modeling framework with deep neural networks. It has the advantage of avoiding pre-definition of similarity or feature engineering. Our model relaxes the constraint of fixing the number of clusters in advance by assigning a Dirichlet Process prior on the latent representation in a low-dimensional feature space. It can adaptively detect novel clusters when new data arrives based on a learned model from historical data in an online unsupervised learning setting. We develop a joint online variational inference algorithm to learn feature representations and cluster assignments via iteratively optimizing the evidence lower bound (ELBO). Our experimental results demonstrate the capacity of our modelling framework to learn the number of clusters automatically using data, the flexibility to detect novel clusters with emerging data adaptively, the ability of high quality reconstruction and generation of samples without supervised information and the improvement over state-of-the-art end-to-end clustering methods in terms of accuracy on both image and text corpora benchmark datasets.
Analysis of high-dimensional Continuous Time Markov Chains using the Local Bouncy Particle Sampler
Jun 03, 2019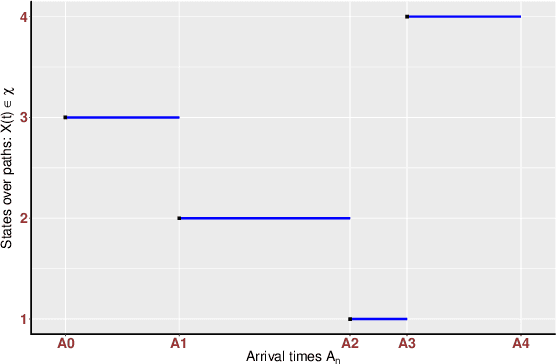

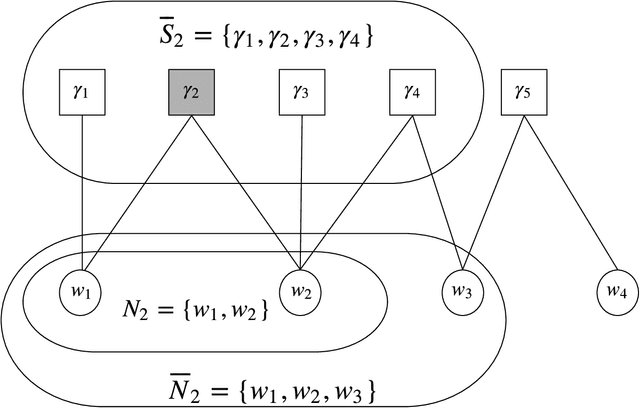

Sampling the parameters of high-dimensional Continuous Time Markov Chains (CTMC) is a challenging problem with important applications in many fields of applied statistics. In this work a recently proposed type of non-reversible rejection-free Markov Chain Monte Carlo (MCMC) sampler, the Bouncy Particle Sampler (BPS), is brought to bear to this problem. BPS has demonstrated its favorable computational efficiency compared with state-of-the-art MCMC algorithms, however to date applications to real-data scenario were scarce. An important aspect of the practical implementation of BPS is the simulation of event times. Default implementations use conservative thinning bounds. Such bounds can slow down the algorithm and limit the computational performance. Our paper develops an algorithm with an exact analytical solution to the random event times in the context of CTMCs. Our local version of BPS algorithm takes advantage of the sparse structure in the target factor graph and we also provide a framework for assessing the computational complexity of local BPS algorithms.
Deep-gKnock: nonlinear group-feature selection with deep neural network
May 27, 2019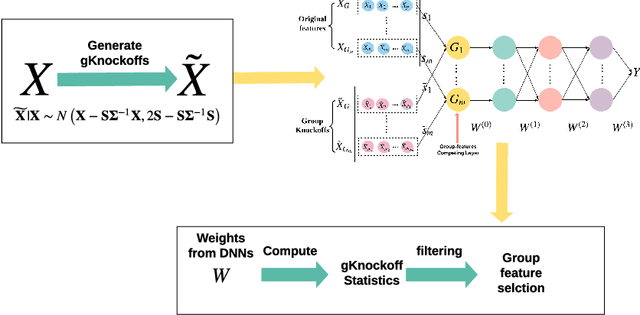

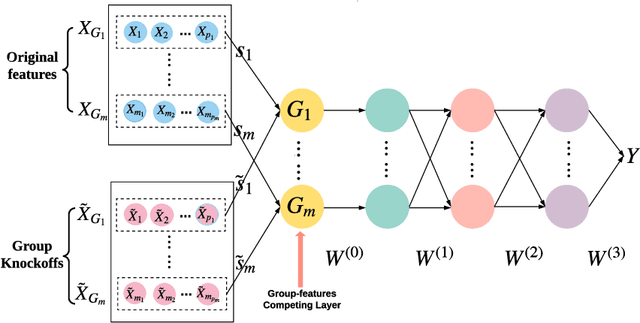
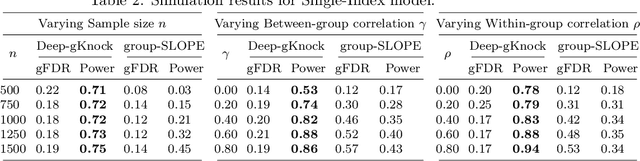
Feature selection is central to contemporary high-dimensional data analysis. Grouping structure among features arises naturally in various scientific problems. Many methods have been proposed to incorporate the grouping structure information into feature selection. However, these methods are normally restricted to a linear regression setting. To relax the linear constraint, we combine the deep neural networks (DNNs) with the recent Knockoffs technique, which has been successful in an individual feature selection context. We propose Deep-gKnock (Deep group-feature selection using Knockoffs) as a methodology for model interpretation and dimension reduction. Deep-gKnock performs model-free group-feature selection by controlling group-wise False Discovery Rate (gFDR). Our method improves the interpretability and reproducibility of DNNs. Experimental results on both synthetic and real data demonstrate that our method achieves superior power and accurate gFDR control compared with state-of-the-art methods.