 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECG-R1: Protocol-Guided and Modality-Agnostic MLLM for Reliable ECG Interpretation
Feb 04, 2026Electrocardiography (ECG) serves as an indispensable diagnostic tool in clinical practice, yet existing multimodal large language models (MLLMs) remain unreliable for ECG interpretation, often producing plausible but clinically incorrect analyses. To address this, we propose ECG-R1, the first reasoning MLLM designed for reliable ECG interpretation via three innovations. First, we construct the interpretation corpus using \textit{Protocol-Guided Instruction Data Generation}, grounding interpretation in measurable ECG features and monograph-defined quantitative thresholds and diagnostic logic. Second, we present a modality-decoupled architecture with \textit{Interleaved Modality Dropout} to improve robustness and cross-modal consistency when either the ECG signal or ECG image is missing. Third, we present \textit{Reinforcement Learning with ECG Diagnostic Evidence Rewards} to strengthen evidence-grounded ECG interpretation. Additionally, we systematically evaluate the ECG interpretation capabilities of proprietary, open-source, and medical MLLMs, and provide the first quantitative evidence that severe hallucinations are widespread, suggesting that the public should not directly trust these outputs without independent verification. Code and data are publicly available at \href{https://github.com/PKUDigitalHealth/ECG-R1}{here}, and an online platform can be accessed at \href{http://ai.heartvoice.com.cn/ECG-R1/}{here}.
R1-SyntheticVL: Is Synthetic Data from Generative Models Ready for Multimodal Large Language Model?
Feb 03, 2026In this work, we aim to develop effective data synthesis techniques that autonomously synthesize multimodal training data for enhancing MLLMs in solving complex real-world tasks. To this end, we propose Collective Adversarial Data Synthesis (CADS), a novel and general approach to synthesize high-quality, diverse and challenging multimodal data for MLLMs. The core idea of CADS is to leverage collective intelligence to ensure high-quality and diverse generation, while exploring adversarial learning to synthesize challenging samples for effectively driving model improvement. Specifically, CADS operates with two cyclic phases, i.e., Collective Adversarial Data Generation (CAD-Generate) and Collective Adversarial Data Judgment (CAD-Judge). CAD-Generate leverages collective knowledge to jointly generate new and diverse multimodal data, while CAD-Judge collaboratively assesses the quality of synthesized data. In addition, CADS introduces an Adversarial Context Optimization mechanism to optimize the generation context to encourage challenging and high-value data generation. With CADS, we construct MMSynthetic-20K and train our model R1-SyntheticVL, which demonstrates superior performance on various benchmarks.
GEM: Empowering MLLM for Grounded ECG Understanding with Time Series and Images
Mar 08, 2025While recent multimodal large language models (MLLMs) have advanced automated ECG interpretation, they still face two key limitations: (1) insufficient multimodal synergy between time series signals and visual ECG representations, and (2) limited explainability in linking diagnoses to granular waveform evidence. We introduce GEM, the first MLLM unifying ECG time series, 12-lead ECG images and text for grounded and clinician-aligned ECG interpretation. GEM enables feature-grounded analysis, evidence-driven reasoning, and a clinician-like diagnostic process through three core innovations: a dual-encoder framework extracting complementary time series and image features, cross-modal alignment for effective multimodal understanding, and knowledge-guided instruction generation for generating high-granularity grounding data (ECG-Grounding) linking diagnoses to measurable parameters ($e.g.$, QRS/PR Intervals). Additionally, we propose the Grounded ECG Understanding task, a clinically motivated benchmark designed to comprehensively assess the MLLM's capability in grounded ECG understanding. Experimental results on both existing and our proposed benchmarks show GEM significantly improves predictive performance (CSN $7.4\% \uparrow$), explainability ($22.7\% \uparrow$), and grounding ($24.8\% \uparrow$), making it more suitable for real-world clinical applications. GitHub repository: https://github.com/lanxiang1017/GEM.git
BadSFL: Backdoor Attack against Scaffold Federated Learning
Nov 26, 2024



Federated learning (FL) enables the training of deep learning models on distributed clients to preserve data privacy. However, this learning paradigm is vulnerable to backdoor attacks, where malicious clients can upload poisoned local models to embed backdoors into the global model, leading to attacker-desired predictions. Existing backdoor attacks mainly focus on FL with independently and identically distributed (IID) scenarios, while real-world FL training data are typically non-IID. Current strategies for non-IID backdoor attacks suffer from limitations in maintaining effectiveness and durability. To address these challenges, we propose a novel backdoor attack method, BadSFL, specifically designed for the FL framework using the scaffold aggregation algorithm in non-IID settings. BadSFL leverages a Generative Adversarial Network (GAN) based on the global model to complement the training set, achieving high accuracy on both backdoor and benign samples. It utilizes a specific feature as the backdoor trigger to ensure stealthiness, and exploits the Scaffold's control variate to predict the global model's convergence direction, ensuring the backdoor's persistence. Extensive experiments on three benchmark datasets demonstrate the high effectiveness, stealthiness, and durability of BadSFL. Notably, our attack remains effective over 60 rounds in the global model and up to 3 times longer than existing baseline attacks after stopping the injection of malicious updates.
Language Modeling on Tabular Data: A Survey of Foundations, Techniques and Evolution
Aug 20, 2024



Tabular data, a prevalent data type across various domains, presents unique challenges due to its heterogeneous nature and complex structural relationships. Achieving high predictive performance and robustness in tabular data analysis holds significant promise for numerous applications. Influenced by recent advancements in natural language processing, particularly transformer architectures, new methods for tabular data modeling have emerged. Early techniques concentrated on pre-training transformers from scratch, often encountering scalability issues. Subsequently, methods leveraging pre-trained language models like BERT have been developed, which require less data and yield enhanced performance. The recent advent of large language models, such as GPT and LLaMA, has further revolutionized the field, facilitating more advanced and diverse applications with minimal fine-tuning. Despite the growing interest, a comprehensive survey of language modeling techniques for tabular data remains absent. This paper fills this gap by providing a systematic review of the development of language modeling for tabular data, encompassing: (1) a categorization of different tabular data structures and data types; (2) a review of key datasets used in model training and tasks used for evaluation; (3) a summary of modeling techniques including widely-adopted data processing methods, popular architectures, and training objectives; (4) the evolution from adapting traditional Pre-training/Pre-trained language models to the utilization of large language models; (5) an identification of persistent challenges and potential future research directions in language modeling for tabular data analysis. GitHub page associated with this survey is available at: https://github.com/lanxiang1017/Language-Modeling-on-Tabular-Data-Survey.git.
Avoiding Feature Suppression in Contrastive Learning: Learning What Has Not Been Learned Before
Feb 19, 2024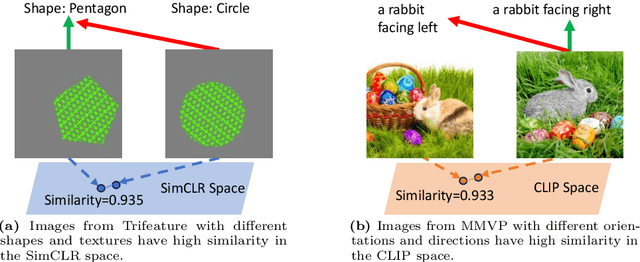



Self-Supervised contrastive learning has emerged as a powerful method for obtaining high-quality representations from unlabeled data. However, feature suppression has recently been identified in standard contrastive learning ($e.g.$, SimCLR, CLIP): in a single end-to-end training stage, the contrastive model captures only parts of the shared information across contrasting views, while ignore the other potentially useful information. With feature suppression, contrastive models often fail to learn sufficient representations capable for various downstream tasks. To mitigate the feature suppression problem and ensure the contrastive model to learn comprehensive representations, we develop a novel Multistage Contrastive Learning (MCL) framework. Unlike standard contrastive learning that often result in feature suppression, MCL progressively learn new features that have not been explored in the previous stage, while maintaining the well-learned features. Extensive experiments conducted on various publicly available benchmarks validate the effectiveness of our proposed framework. In addition, we demonstrate that the proposed MCL can be adapted to a variety of popular contrastive learning backbones and boost their performance by learning features that could not be gained from standard contrastive learning procedures.
A Survey of Large Language Models for Healthcare: from Data, Technology, and Applications to Accountability and Ethics
Oct 09, 2023



The utilization of large language models (LLMs) in the Healthcare domain has generated both excitement and concern due to their ability to effectively respond to freetext queries with certain professional knowledge. This survey outlines the capabilities of the currently developed LLMs for Healthcare and explicates their development process, with the aim of providing an overview of the development roadmap from traditional Pretrained Language Models (PLMs) to LLMs. Specifically, we first explore the potential of LLMs to enhance the efficiency and effectiveness of various Healthcare applications highlighting both the strengths and limitations. Secondly, we conduct a comparison between the previous PLMs and the latest LLMs, as well as comparing various LLMs with each other. Then we summarize related Healthcare training data, training methods, optimization strategies, and usage. Finally, the unique concerns associated with deploying LLMs in Healthcare settings are investigated, particularly regarding fairness, accountability, transparency and ethics. Our survey provide a comprehensive investigation from perspectives of both computer science and Healthcare specialty. Besides the discussion about Healthcare concerns, we supports the computer science community by compiling a collection of open source resources, such as accessible datasets, the latest methodologies, code implementations, and evaluation benchmarks in the Github. Summarily, we contend that a significant paradigm shift is underway, transitioning from PLMs to LLMs. This shift encompasses a move from discriminative AI approaches to generative AI approaches, as well as a shift from model-centered methodologies to datacentered methodologies.
Medical Intervention Duration Estimation Using Language-enhanced Transformer Encoder with Medical Prompts
Mar 30, 2023In recent years, estimating the duration of medical intervention based on electronic health records (EHRs) has gained significant attention in the filed of clinical decision support. However, current models largely focus on structured data, leaving out information from the unstructured clinical free-text data. To address this, we present a novel language-enhanced transformer-based framework, which projects all relevant clinical data modalities (continuous, categorical, binary, and free-text features) into a harmonized language latent space using a pre-trained sentence encoder with the help of medical prompts. The proposed method enables the integration of information from different modalities within the cell transformer encoder and leads to more accurate duration estimation for medical intervention. Our experimental results on both US-based (length of stay in ICU estimation) and Asian (surgical duration prediction) medical datasets demonstrate the effectiveness of our proposed framework, which outperforms tailored baseline approaches and exhibits robustness to data corruption in EHRs.
Towards Better Time Series Contrastive Learning: A Dynamic Bad Pair Mining Approach
Feb 07, 2023Not all positive pairs are beneficial to time series contrastive learning. In this paper, we study two types of bad positive pairs that impair the quality of time series representation learned through contrastive learning ($i.e.$, noisy positive pair and faulty positive pair). We show that, with the presence of noisy positive pairs, the model tends to simply learn the pattern of noise (Noisy Alignment). Meanwhile, when faulty positive pairs arise, the model spends considerable efforts aligning non-representative patterns (Faulty Alignment). To address this problem, we propose a Dynamic Bad Pair Mining (DBPM) algorithm, which reliably identifies and suppresses bad positive pairs in time series contrastive learning. DBPM utilizes a memory module to track the training behavior of each positive pair along training process. This allows us to identify potential bad positive pairs at each epoch based on their historical training behaviors. The identified bad pairs are then down-weighted using a transformation module. Our experimental results show that DBPM effectively mitigates the negative impacts of bad pairs, and can be easily used as a plug-in to boost performance of state-of-the-art methods. Codes will be made publicly available.
Intra-Inter Subject Self-supervised Learning for Multivariate Cardiac Signals
Sep 18, 2021

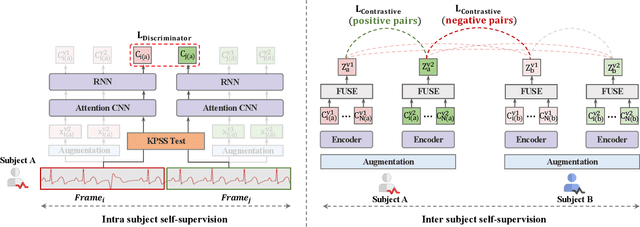
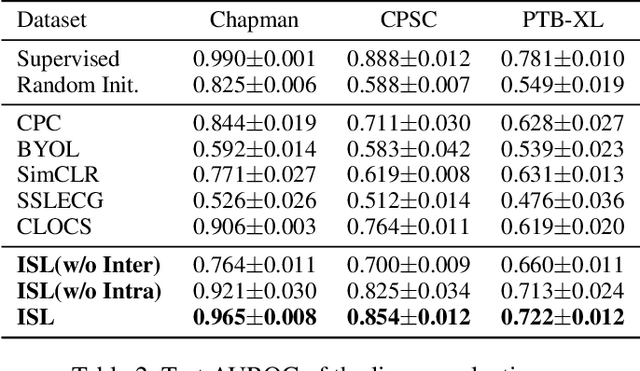
Learning information-rich and generalizable representations effectively from unlabeled multivariate cardiac signals to identify abnormal heart rhythms (cardiac arrhythmias) is valuable in real-world clinical settings but often challenging due to its complex temporal dynamics. Cardiac arrhythmias can vary significantly in temporal patterns even for the same patient ($i.e.$, intra subject difference). Meanwhile, the same type of cardiac arrhythmia can show different temporal patterns among different patients due to different cardiac structures ($i.e.$, inter subject difference). In this paper, we address the challenges by proposing an Intra-inter Subject self-supervised Learning (ISL) model that is customized for multivariate cardiac signals. Our proposed ISL model integrates medical knowledge into self-supervision to effectively learn from intra-inter subject differences. In intra subject self-supervision, ISL model first extracts heartbeat-level features from each subject using a channel-wise attentional CNN-RNN encoder. Then a stationarity test module is employed to capture the temporal dependencies between heartbeats. In inter subject self-supervision, we design a set of data augmentations according to the clinical characteristics of cardiac signals and perform contrastive learning among subjects to learn distinctive representations for various types of patients. Extensive experiments on three real-world datasets were conducted. In a semi-supervised transfer learning scenario, our pre-trained ISL model leads about 10% improvement over supervised training when only 1% labeled data is available, suggesting strong generalizability and robustness of the model.