 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Verifiable Attention for LLM Inference
Jun 15, 2026Computation integrity of remote large language model (LLM) serving can be questionable. For conventional deep neural networks (DNNs), the existing TEE-shielded DNN partitioning (TSDP) approach uses Trusted Execution Environment (TEE) to compute non-linear components and verify the integrity of linear components offloaded to an untrusted GPU. However, directly applying TSDP to Transformer-based LLMs incurs significant TEE computation and TEE-GPU communication overhead. This paper presents Communication-efficient TEE-GPU Attention (\textsc{VeriAttn}) for accelerating verifiable LLM inference. \textsc{VeriAttn} offloads both linear and non-linear computations of attention to the GPU, while TEE performs verification. Moreover, for prefill, \textsc{VeriAttn} uses a two-level pipeline to overlap data movement, TEE pre-/post-processing, and GPU computation. For decoding, when the key-value cache exceeds available GPU memory, \textsc{VeriAttn} partitions attention across TEE and GPU to reduce repeated key-value transfers. Evaluation on an Intel TDX platform shows that \textsc{VeriAttn} achieves 2.60-3.38$\times$ and 3.86-5.42$\times$ acceleration over TSDP for 6k-token prompts and 10k-token outputs during prefill and decoding, respectively.
Agora: Toward Autonomous Bug Detection in Production-Level Consensus Protocols with LLM Agents
May 28, 2026Consensus protocols form the backbone of distributed systems and blockchains, where implementation bugs can cause data corruption and financial losses. While LLM-based approaches show promise in code analysis, they struggle with deep protocol-level logic bugs involving complex state-dependent behaviors across multiple execution stages. We present Agora, a domain-aware multi-agent framework that integrates hypothesis-driven testing with LLM capabilities for systematic protocol verification. Agora employs specialized agents that collaboratively explore protocol state spaces, synthesize attack scenarios using domain-specific constraints, and validate findings through iterative refinement. This explicit role separation enables reasoning about global protocol invariants beyond single-function code analysis. We evaluate Agora on four consensus implementations (Raft, EPaxos, HotStuff, BullShark) using four state-of-the-art LLMs. Agora discovers 15 previously unknown protocol-level logic bugs that violate safety properties, while existing LLM-based agents fail to detect any such protocol-level logic bugs. Our results demonstrate that domain-aware multi-agent collaboration is essential for detecting deep logic bugs in complex protocols.
HGP-Mamba: Integrating Histology and Generated Protein Features for Mamba-based Multimodal Survival Risk Prediction
Mar 17, 2026Recent advances in multimodal learning have significantly improved cancer survival risk prediction. However, the joint prognostic potential of protein markers and histopathology images remains underexplored, largely due to the high cost and limited availability of protein expression profiling. To address this challenge, we propose HGP-Mamba, a Mamba-based multimodal framework that efficiently integrates histological with generated protein features for survival risk prediction. Specifically, we introduce a protein feature extractor (PFE) that leverages pretrained foundation models to derive high-throughput protein embeddings directly from Whole Slide Images (WSIs), enabling data-efficient incorporation of molecular information. Together with histology embeddings that capture morphological patterns, we further introduce the Local Interaction-aware Mamba (LiAM) for fine-grained feature interaction and the Global Interaction-enhanced Mamba (GiEM) to promote holistic modality fusion at the slide level, thus capture complex cross-modal dependencies. Experiments on four public cancer datasets demonstrate that HGP-Mamba achieves state-of-the-art performance while maintaining superior computational efficiency compared with existing methods. Our source code is publicly available at <a href="https://github.com/Daijing-ai/HGP-Mamba.git">this https URL</a>.
HalluJudge: A Reference-Free Hallucination Detection for Context Misalignment in Code Review Automation
Jan 27, 2026Large Language models (LLMs) have shown strong capabilities in code review automation, such as review comment generation, yet they suffer from hallucinations -- where the generated review comments are ungrounded in the actual code -- poses a significant challenge to the adoption of LLMs in code review workflows. To address this, we explore effective and scalable methods for a hallucination detection in LLM-generated code review comments without the reference. In this work, we design HalluJudge that aims to assess the grounding of generated review comments based on the context alignment. HalluJudge includes four key strategies ranging from direct assessment to structured multi-branch reasoning (e.g., Tree-of-Thoughts). We conduct a comprehensive evaluation of these assessment strategies across Atlassian's enterprise-scale software projects to examine the effectiveness and cost-efficiency of HalluJudge. Furthermore, we analyze the alignment between HalluJudge's judgment and developer preference of the actual LLM-generated code review comments in the real-world production. Our results show that the hallucination assessment in HalluJudge is cost-effective with an F1 score of 0.85 and an average cost of $0.009. On average, 67% of the HalluJudge assessments are aligned with the developer preference of the actual LLM-generated review comments in the online production. Our results suggest that HalluJudge can serve as a practical safeguard to reduce developers' exposure to hallucinated comments, fostering trust in AI-assisted code reviews.
AgenticSCR: An Autonomous Agentic Secure Code Review for Immature Vulnerabilities Detection
Jan 27, 2026Secure code review is critical at the pre-commit stage, where vulnerabilities must be caught early under tight latency and limited-context constraints. Existing SAST-based checks are noisy and often miss immature, context-dependent vulnerabilities, while standalone Large Language Models (LLMs) are constrained by context windows and lack explicit tool use. Agentic AI, which combine LLMs with autonomous decision-making, tool invocation, and code navigation, offer a promising alternative, but their effectiveness for pre-commit secure code review is not yet well understood. In this work, we introduce AgenticSCR, an agentic AI for secure code review for detecting immature vulnerabilities during the pre-commit stage, augmented by security-focused semantic memories. Using our own curated benchmark of immature vulnerabilities, tailored to the pre-commit secure code review, we empirically evaluate how accurate is our AgenticSCR for localizing, detecting, and explaining immature vulnerabilities. Our results show that AgenticSCR achieves at least 153% relatively higher percentage of correct code review comments than the static LLM-based baseline, and also substantially surpasses SAST tools. Moreover, AgenticSCR generates more correct comments in four out of five vulnerability types, consistently and significantly outperforming all other baselines. These findings highlight the importance of Agentic Secure Code Review, paving the way towards an emerging research area of immature vulnerability detection.
RovoDev Code Reviewer: A Large-Scale Online Evaluation of LLM-based Code Review Automation at Atlassian
Jan 03, 2026Large Language Models (LLMs)-powered code review automation has the potential to transform code review workflows. Despite the advances of LLM-powered code review comment generation approaches, several practical challenges remain for designing enterprise-grade code review automation tools. In particular, this paper aims at answering the practical question: how can we design a review-guided, context-aware, quality-checked code review comment generation without fine-tuning? In this paper, we present RovoDev Code Reviewer, an enterprise-grade LLM-based code review automation tool designed and deployed at scale within Atlassian's development ecosystem with seamless integration into Atlassian's Bitbucket. Through the offline, online, user feedback evaluations over a one-year period, we conclude that RovoDev Code Reviewer is (1) effective in generating code review comments that could lead to code resolution for 38.70% (i.e., comments that triggered code changes in the subsequent commits); and (2) offers the promise of accelerating feedback cycles (i.e., decreasing the PR cycle time by 30.8%), alleviating reviewer workload (i.e., reducing the number of human-written comments by 35.6%), and improving overall software quality (i.e., finding errors with actionable suggestions).
SALM: Spatial Audio Language Model with Structured Embeddings for Understanding and Editing
Jul 22, 2025Spatial audio understanding is essential for accurately perceiving and interpreting acoustic environments. However, existing audio-language models struggle with processing spatial audio and perceiving spatial acoustic scenes. We introduce the Spatial Audio Language Model (SALM), a novel framework that bridges spatial audio and language via multi-modal contrastive learning. SALM consists of a text encoder and a dual-branch audio encoder, decomposing spatial sound into semantic and spatial components through structured audio embeddings. Key features of SALM include seamless alignment of spatial and text representations, separate and joint extraction of spatial and semantic information, zero-shot direction classification and robust support for spatial audio editing. Experimental results demonstrate that SALM effectively captures and aligns cross-modal representations. Furthermore, it supports advanced editing capabilities, such as altering directional audio using text-based embeddings.
MFogHub: Bridging Multi-Regional and Multi-Satellite Data for Global Marine Fog Detection and Forecasting
May 15, 2025Deep learning approaches for marine fog detection and forecasting have outperformed traditional methods, demonstrating significant scientific and practical importance. However, the limited availability of open-source datasets remains a major challenge. Existing datasets, often focused on a single region or satellite, restrict the ability to evaluate model performance across diverse conditions and hinder the exploration of intrinsic marine fog characteristics. To address these limitations, we introduce \textbf{MFogHub}, the first multi-regional and multi-satellite dataset to integrate annotated marine fog observations from 15 coastal fog-prone regions and six geostationary satellites, comprising over 68,000 high-resolution samples. By encompassing diverse regions and satellite perspectives, MFogHub facilitates rigorous evaluation of both detection and forecasting methods under varying conditions. Extensive experiments with 16 baseline models demonstrate that MFogHub can reveal generalization fluctuations due to regional and satellite discrepancy, while also serving as a valuable resource for the development of targeted and scalable fog prediction techniques. Through MFogHub, we aim to advance both the practical monitoring and scientific understanding of marine fog dynamics on a global scale. The dataset and code are at \href{https://github.com/kaka0910/MFogHub}{https://github.com/kaka0910/MFogHub}.
Enhancing Multi-task Learning Capability of Medical Generalist Foundation Model via Image-centric Multi-annotation Data
Apr 14, 2025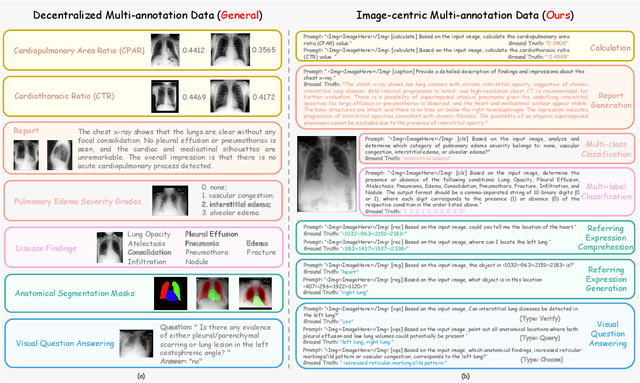
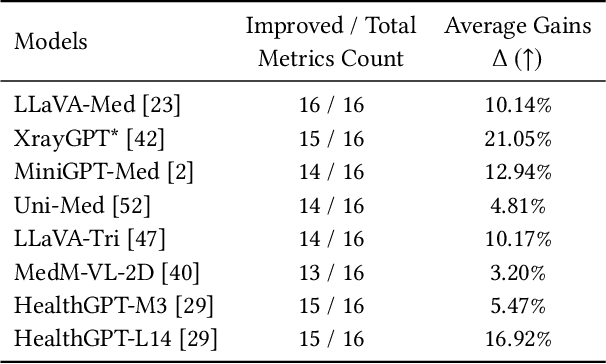
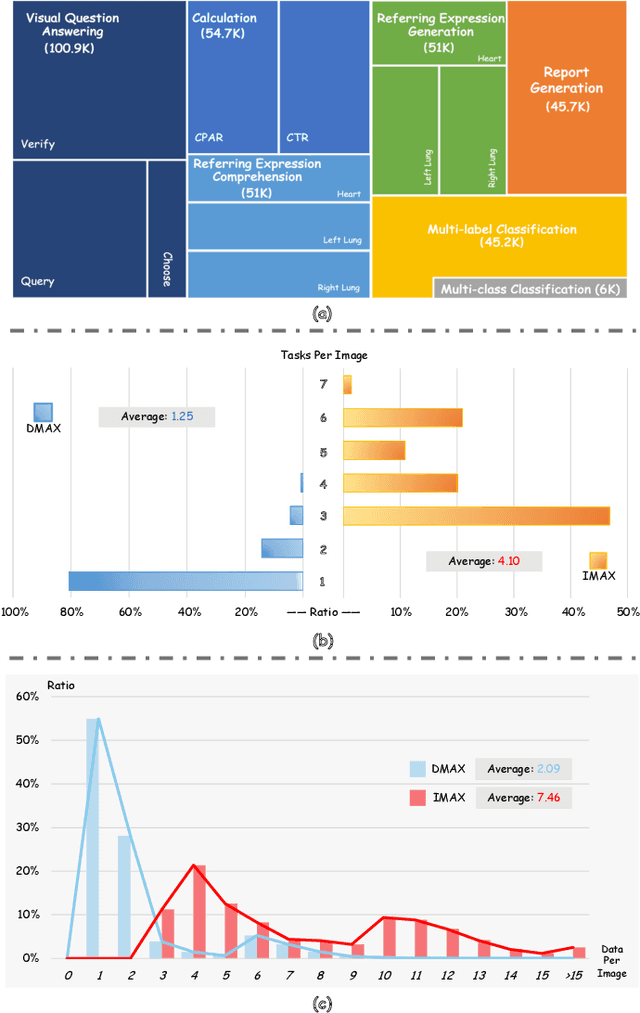

The emergence of medical generalist foundation models has revolutionized conventional task-specific model development paradigms, aiming to better handle multiple tasks through joint training on large-scale medical datasets. However, recent advances prioritize simple data scaling or architectural component enhancement, while neglecting to re-examine multi-task learning from a data-centric perspective. Critically, simply aggregating existing data resources leads to decentralized image-task alignment, which fails to cultivate comprehensive image understanding or align with clinical needs for multi-dimensional image interpretation. In this paper, we introduce the image-centric multi-annotation X-ray dataset (IMAX), the first attempt to enhance the multi-task learning capabilities of medical multi-modal large language models (MLLMs) from the data construction level. To be specific, IMAX is featured from the following attributes: 1) High-quality data curation. A comprehensive collection of more than 354K entries applicable to seven different medical tasks. 2) Image-centric dense annotation. Each X-ray image is associated with an average of 4.10 tasks and 7.46 training entries, ensuring multi-task representation richness per image. Compared to the general decentralized multi-annotation X-ray dataset (DMAX), IMAX consistently demonstrates significant multi-task average performance gains ranging from 3.20% to 21.05% across seven open-source state-of-the-art medical MLLMs. Moreover, we investigate differences in statistical patterns exhibited by IMAX and DMAX training processes, exploring potential correlations between optimization dynamics and multi-task performance. Finally, leveraging the core concept of IMAX data construction, we propose an optimized DMAX-based training strategy to alleviate the dilemma of obtaining high-quality IMAX data in practical scenarios.
Code Readability in the Age of Large Language Models: An Industrial Case Study from Atlassian
Jan 20, 2025Programmers spend a significant amount of time reading code during the software development process. This trend is amplified by the emergence of large language models (LLMs) that automatically generate code. However, little is known about the readability of the LLM-generated code and whether it is still important from practitioners' perspectives in this new era. In this paper, we conduct a survey to explore the practitioners' perspectives on code readability in the age of LLMs and investigate the readability of our LLM-based software development agents framework, HULA, by comparing its generated code with human-written code in real-world scenarios. Overall, the findings underscore that (1) readability remains a critical aspect of software development; (2) the readability of our LLM-generated code is comparable to human-written code, fostering the establishment of appropriate trust and driving the broad adoption of our LLM-powered software development platform.