 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBARE: Towards Bias-Aware and Reasoning-Enhanced One-Tower Visual Grounding
Jan 04, 2026Visual Grounding (VG), which aims to locate a specific region referred to by expressions, is a fundamental yet challenging task in the multimodal understanding fields. While recent grounding transfer works have advanced the field through one-tower architectures, they still suffer from two primary limitations: (1) over-entangled multimodal representations that exacerbate deceptive modality biases, and (2) insufficient semantic reasoning that hinders the comprehension of referential cues. In this paper, we propose BARE, a bias-aware and reasoning-enhanced framework for one-tower visual grounding. BARE introduces a mechanism that preserves modality-specific features and constructs referential semantics through three novel modules: (i) language salience modulator, (ii) visual bias correction and (iii) referential relationship enhancement, which jointly mitigate multimodal distractions and enhance referential comprehension. Extensive experimental results on five benchmarks demonstrate that BARE not only achieves state-of-the-art performance but also delivers superior computational efficiency compared to existing approaches. The code is publicly accessible at https://github.com/Marloweeee/BARE.
Multi-modal cross-domain mixed fusion model with dual disentanglement for fault diagnosis under unseen working conditions
Dec 31, 2025Intelligent fault diagnosis has become an indispensable technique for ensuring machinery reliability. However, existing methods suffer significant performance decline in real-world scenarios where models are tested under unseen working conditions, while domain adaptation approaches are limited to their reliance on target domain samples. Moreover, most existing studies rely on single-modal sensing signals, overlooking the complementary nature of multi-modal information for improving model generalization. To address these limitations, this paper proposes a multi-modal cross-domain mixed fusion model with dual disentanglement for fault diagnosis. A dual disentanglement framework is developed to decouple modality-invariant and modality-specific features, as well as domain-invariant and domain-specific representations, enabling both comprehensive multi-modal representation learning and robust domain generalization. A cross-domain mixed fusion strategy is designed to randomly mix modality information across domains for modality and domain diversity augmentation. Furthermore, a triple-modal fusion mechanism is introduced to adaptively integrate multi-modal heterogeneous information. Extensive experiments are conducted on induction motor fault diagnosis under both unseen constant and time-varying working conditions. The results demonstrate that the proposed method consistently outperforms advanced methods and comprehensive ablation studies further verify the effectiveness of each proposed component and multi-modal fusion. The code is available at: https://github.com/xiapc1996/MMDG.
EMFusion: Conditional Diffusion Framework for Trustworthy Frequency Selective EMF Forecasting in Wireless Networks
Dec 17, 2025The rapid growth in wireless infrastructure has increased the need to accurately estimate and forecast electromagnetic field (EMF) levels to ensure ongoing compliance, assess potential health impacts, and support efficient network planning. While existing studies rely on univariate forecasting of wideband aggregate EMF data, frequency-selective multivariate forecasting is needed to capture the inter-operator and inter-frequency variations essential for proactive network planning. To this end, this paper introduces EMFusion, a conditional multivariate diffusion-based probabilistic forecasting framework that integrates diverse contextual factors (e.g., time of day, season, and holidays) while providing explicit uncertainty estimates. The proposed architecture features a residual U-Net backbone enhanced by a cross-attention mechanism that dynamically integrates external conditions to guide the generation process. Furthermore, EMFusion integrates an imputation-based sampling strategy that treats forecasting as a structural inpainting task, ensuring temporal coherence even with irregular measurements. Unlike standard point forecasters, EMFusion generates calibrated probabilistic prediction intervals directly from the learned conditional distribution, providing explicit uncertainty quantification essential for trustworthy decision-making. Numerical experiments conducted on frequency-selective EMF datasets demonstrate that EMFusion with the contextual information of working hours outperforms the baseline models with or without conditions. The EMFusion outperforms the best baseline by 23.85% in continuous ranked probability score (CRPS), 13.93% in normalized root mean square error, and reduces prediction CRPS error by 22.47%.
MFogHub: Bridging Multi-Regional and Multi-Satellite Data for Global Marine Fog Detection and Forecasting
May 15, 2025Deep learning approaches for marine fog detection and forecasting have outperformed traditional methods, demonstrating significant scientific and practical importance. However, the limited availability of open-source datasets remains a major challenge. Existing datasets, often focused on a single region or satellite, restrict the ability to evaluate model performance across diverse conditions and hinder the exploration of intrinsic marine fog characteristics. To address these limitations, we introduce \textbf{MFogHub}, the first multi-regional and multi-satellite dataset to integrate annotated marine fog observations from 15 coastal fog-prone regions and six geostationary satellites, comprising over 68,000 high-resolution samples. By encompassing diverse regions and satellite perspectives, MFogHub facilitates rigorous evaluation of both detection and forecasting methods under varying conditions. Extensive experiments with 16 baseline models demonstrate that MFogHub can reveal generalization fluctuations due to regional and satellite discrepancy, while also serving as a valuable resource for the development of targeted and scalable fog prediction techniques. Through MFogHub, we aim to advance both the practical monitoring and scientific understanding of marine fog dynamics on a global scale. The dataset and code are at \href{https://github.com/kaka0910/MFogHub}{https://github.com/kaka0910/MFogHub}.
M4Fog: A Global Multi-Regional, Multi-Modal, and Multi-Stage Dataset for Marine Fog Detection and Forecasting to Bridge Ocean and Atmosphere
Jun 19, 2024Marine fog poses a significant hazard to global shipping, necessitating effective detection and forecasting to reduce economic losses. In recent years, several machine learning (ML) methods have demonstrated superior detection accuracy compared to traditional meteorological methods. However, most of these works are developed on proprietary datasets, and the few publicly accessible datasets are often limited to simplistic toy scenarios for research purposes. To advance the field, we have collected nearly a decade's worth of multi-modal data related to continuous marine fog stages from four series of geostationary meteorological satellites, along with meteorological observations and numerical analysis, covering 15 marine regions globally where maritime fog frequently occurs. Through pixel-level manual annotation by meteorological experts, we present the most comprehensive marine fog detection and forecasting dataset to date, named M4Fog, to bridge ocean and atmosphere. The dataset comprises 68,000 "super data cubes" along four dimensions: elements, latitude, longitude and time, with a temporal resolution of half an hour and a spatial resolution of 1 kilometer. Considering practical applications, we have defined and explored three meaningful tracks with multi-metric evaluation systems: static or dynamic marine fog detection, and spatio-temporal forecasting for cloud images. Extensive benchmarking and experiments demonstrate the rationality and effectiveness of the construction concept for proposed M4Fog. The data and codes are available to whole researchers through cloud platforms to develop ML-driven marine fog solutions and mitigate adverse impacts on human activities.
Prototypical Contrastive Language Image Pretraining
Jun 22, 2022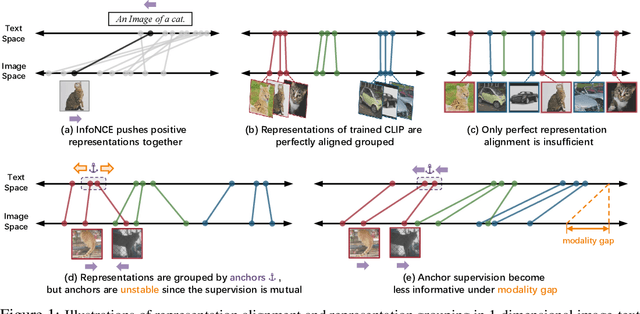
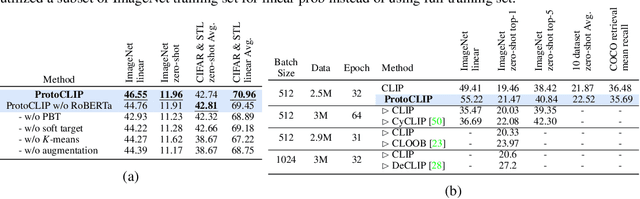

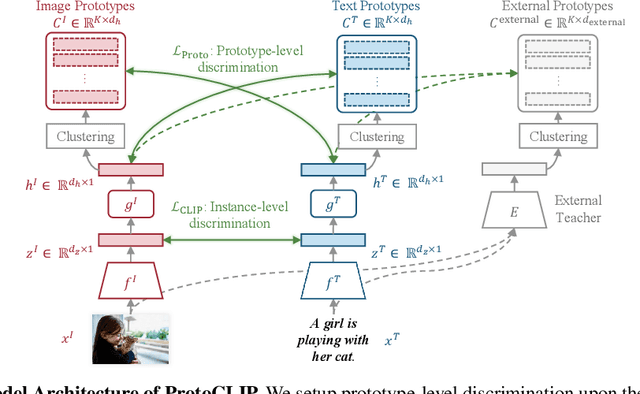
Contrastive Language Image Pretraining (CLIP) received widespread attention since its learned representations can be transferred well to various downstream tasks. During CLIP training, the InfoNCE objective aims to align positive image-text pairs and separate negative ones. In this paper, we show a representation grouping effect during this process: the InfoNCE objective indirectly groups semantically similar representations together via randomly emerged within-modal anchors. We introduce Prototypical Contrastive Language Image Pretraining (ProtoCLIP) to enhance such grouping by boosting its efficiency and increasing its robustness against modality gap. Specifically, ProtoCLIP sets up prototype-level discrimination between image and text spaces, which efficiently transfers higher-level structural knowledge. We further propose Prototypical Back Translation (PBT) to decouple representation grouping from representation alignment, resulting in effective learning of meaningful representations under large modality gap. PBT also enables us to introduce additional external teachers with richer prior knowledge. ProtoCLIP is trained with an online episodic training strategy, which makes it can be scaled up to unlimited amounts of data. Combining the above novel designs, we train our ProtoCLIP on Conceptual Captions and achieved an +5.81% ImageNet linear probing improvement and an +2.01% ImageNet zero-shot classification improvement. Codes are available at https://github.com/megvii-research/protoclip.