 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction100M: A Large-scale Video Action Dataset
Jan 15, 2026Inferring physical actions from visual observations is a fundamental capability for advancing machine intelligence in the physical world. Achieving this requires large-scale, open-vocabulary video action datasets that span broad domains. We introduce Action100M, a large-scale dataset constructed from 1.2M Internet instructional videos (14.6 years of duration), yielding O(100 million) temporally localized segments with open-vocabulary action supervision and rich captions. Action100M is generated by a fully automated pipeline that (i) performs hierarchical temporal segmentation using V-JEPA 2 embeddings, (ii) produces multi-level frame and segment captions organized as a Tree-of-Captions, and (iii) aggregates evidence with a reasoning model (GPT-OSS-120B) under a multi-round Self-Refine procedure to output structured annotations (brief/detailed action, actor, brief/detailed caption). Training VL-JEPA on Action100M demonstrates consistent data-scaling improvements and strong zero-shot performance across diverse action recognition benchmarks, establishing Action100M as a new foundation for scalable research in video understanding and world modeling.
VL-JEPA: Joint Embedding Predictive Architecture for Vision-language
Dec 11, 2025We introduce VL-JEPA, a vision-language model built on a Joint Embedding Predictive Architecture (JEPA). Instead of autoregressively generating tokens as in classical VLMs, VL-JEPA predicts continuous embeddings of the target texts. By learning in an abstract representation space, the model focuses on task-relevant semantics while abstracting away surface-level linguistic variability. In a strictly controlled comparison against standard token-space VLM training with the same vision encoder and training data, VL-JEPA achieves stronger performance while having 50% fewer trainable parameters. At inference time, a lightweight text decoder is invoked only when needed to translate VL-JEPA predicted embeddings into text. We show that VL-JEPA natively supports selective decoding that reduces the number of decoding operations by 2.85x while maintaining similar performance compared to non-adaptive uniform decoding. Beyond generation, the VL-JEPA's embedding space naturally supports open-vocabulary classification, text-to-video retrieval, and discriminative VQA without any architecture modification. On eight video classification and eight video retrieval datasets, the average performance VL-JEPA surpasses that of CLIP, SigLIP2, and Perception Encoder. At the same time, the model achieves comparable performance as classical VLMs (InstructBLIP, QwenVL) on four VQA datasets: GQA, TallyQA, POPE and POPEv2, despite only having 1.6B parameters.
WorldPrediction: A Benchmark for High-level World Modeling and Long-horizon Procedural Planning
Jun 04, 2025Humans are known to have an internal "world model" that enables us to carry out action planning based on world states. AI agents need to have such a world model for action planning as well. It is not clear how current AI models, especially generative models, are able to learn such world models and carry out procedural planning in diverse environments. We introduce WorldPrediction, a video-based benchmark for evaluating world modeling and procedural planning capabilities of different AI models. In contrast to prior benchmarks that focus primarily on low-level world modeling and robotic motion planning, WorldPrediction is the first benchmark that emphasizes actions with temporal and semantic abstraction. Given initial and final world states, the task is to distinguish the proper action (WorldPrediction-WM) or the properly ordered sequence of actions (WorldPrediction-PP) from a set of counterfactual distractors. This discriminative task setup enable us to evaluate different types of world models and planners and realize a thorough comparison across different hypothesis. The benchmark represents states and actions using visual observations. In order to prevent models from exploiting low-level continuity cues in background scenes, we provide "action equivalents" - identical actions observed in different contexts - as candidates for selection. This benchmark is grounded in a formal framework of partially observable semi-MDP, ensuring better reliability and robustness of the evaluation. We conduct extensive human filtering and validation on our benchmark and show that current frontier models barely achieve 57% accuracy on WorldPrediction-WM and 38% on WorldPrediction-PP whereas humans are able to solve both tasks perfectly.
Chain-of-Talkers (CoTalk): Fast Human Annotation of Dense Image Captions
May 28, 2025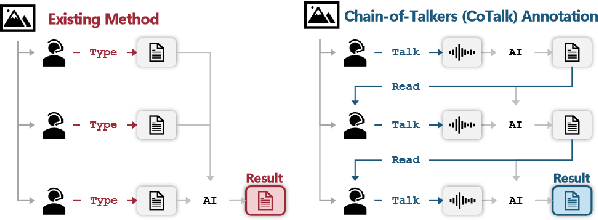

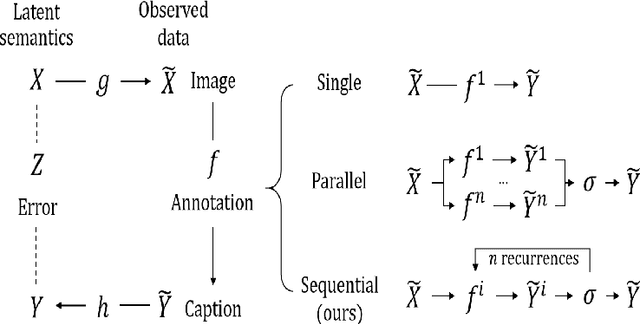
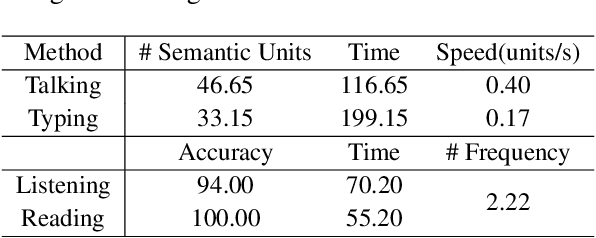
While densely annotated image captions significantly facilitate the learning of robust vision-language alignment, methodologies for systematically optimizing human annotation efforts remain underexplored. We introduce Chain-of-Talkers (CoTalk), an AI-in-the-loop methodology designed to maximize the number of annotated samples and improve their comprehensiveness under fixed budget constraints (e.g., total human annotation time). The framework is built upon two key insights. First, sequential annotation reduces redundant workload compared to conventional parallel annotation, as subsequent annotators only need to annotate the ``residual'' -- the missing visual information that previous annotations have not covered. Second, humans process textual input faster by reading while outputting annotations with much higher throughput via talking; thus a multimodal interface enables optimized efficiency. We evaluate our framework from two aspects: intrinsic evaluations that assess the comprehensiveness of semantic units, obtained by parsing detailed captions into object-attribute trees and analyzing their effective connections; extrinsic evaluation measures the practical usage of the annotated captions in facilitating vision-language alignment. Experiments with eight participants show our Chain-of-Talkers (CoTalk) improves annotation speed (0.42 vs. 0.30 units/sec) and retrieval performance (41.13\% vs. 40.52\%) over the parallel method.
RemoteSAM: Towards Segment Anything for Earth Observation
May 23, 2025
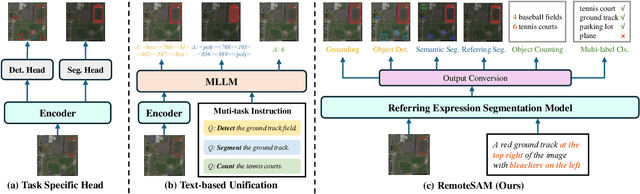
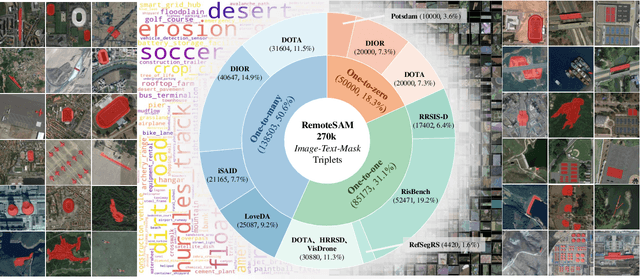
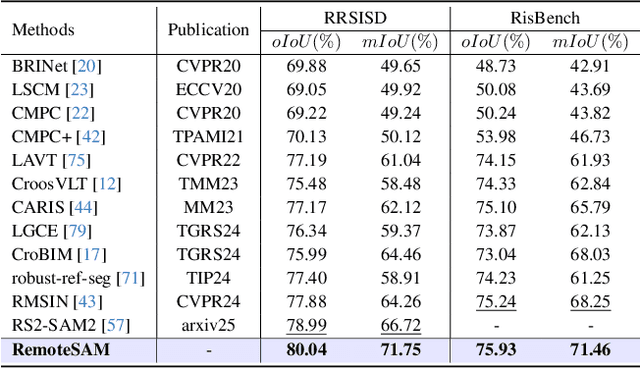
We aim to develop a robust yet flexible visual foundation model for Earth observation. It should possess strong capabilities in recognizing and localizing diverse visual targets while providing compatibility with various input-output interfaces required across different task scenarios. Current systems cannot meet these requirements, as they typically utilize task-specific architecture trained on narrow data domains with limited semantic coverage. Our study addresses these limitations from two aspects: data and modeling. We first introduce an automatic data engine that enjoys significantly better scalability compared to previous human annotation or rule-based approaches. It has enabled us to create the largest dataset of its kind to date, comprising 270K image-text-mask triplets covering an unprecedented range of diverse semantic categories and attribute specifications. Based on this data foundation, we further propose a task unification paradigm that centers around referring expression segmentation. It effectively handles a wide range of vision-centric perception tasks, including classification, detection, segmentation, grounding, etc, using a single model without any task-specific heads. Combining these innovations on data and modeling, we present RemoteSAM, a foundation model that establishes new SoTA on several earth observation perception benchmarks, outperforming other foundation models such as Falcon, GeoChat, and LHRS-Bot with significantly higher efficiency. Models and data are publicly available at https://github.com/1e12Leon/RemoteSAM.
Prompting DirectSAM for Semantic Contour Extraction in Remote Sensing Images
Oct 08, 2024
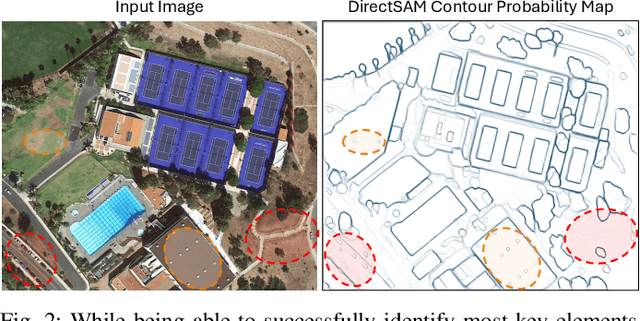


The Direct Segment Anything Model (DirectSAM) excels in class-agnostic contour extraction. In this paper, we explore its use by applying it to optical remote sensing imagery, where semantic contour extraction-such as identifying buildings, road networks, and coastlines-holds significant practical value. Those applications are currently handled via training specialized small models separately on small datasets in each domain. We introduce a foundation model derived from DirectSAM, termed DirectSAM-RS, which not only inherits the strong segmentation capability acquired from natural images, but also benefits from a large-scale dataset we created for remote sensing semantic contour extraction. This dataset comprises over 34k image-text-contour triplets, making it at least 30 times larger than individual dataset. DirectSAM-RS integrates a prompter module: a text encoder and cross-attention layers attached to the DirectSAM architecture, which allows flexible conditioning on target class labels or referring expressions. We evaluate the DirectSAM-RS in both zero-shot and fine-tuning setting, and demonstrate that it achieves state-of-the-art performance across several downstream benchmarks.
Making Large Vision Language Models to be Good Few-shot Learners
Aug 21, 2024



Few-shot classification (FSC) is a fundamental yet challenging task in computer vision that involves recognizing novel classes from limited data. While previous methods have focused on enhancing visual features or incorporating additional modalities, Large Vision Language Models (LVLMs) offer a promising alternative due to their rich knowledge and strong visual perception. However, LVLMs risk learning specific response formats rather than effectively extracting useful information from support data in FSC tasks. In this paper, we investigate LVLMs' performance in FSC and identify key issues such as insufficient learning and the presence of severe positional biases. To tackle the above challenges, we adopt the meta-learning strategy to teach models "learn to learn". By constructing a rich set of meta-tasks for instruction fine-tuning, LVLMs enhance the ability to extract information from few-shot support data for classification. Additionally, we further boost LVLM's few-shot learning capabilities through label augmentation and candidate selection in the fine-tuning and inference stage, respectively. Label augmentation is implemented via a character perturbation strategy to ensure the model focuses on support information. Candidate selection leverages attribute descriptions to filter out unreliable candidates and simplify the task. Extensive experiments demonstrate that our approach achieves superior performance on both general and fine-grained datasets. Furthermore, our candidate selection strategy has been proven beneficial for training-free LVLMs.
LLM Internal States Reveal Hallucination Risk Faced With a Query
Jul 03, 2024The hallucination problem of Large Language Models (LLMs) significantly limits their reliability and trustworthiness. Humans have a self-awareness process that allows us to recognize what we don't know when faced with queries. Inspired by this, our paper investigates whether LLMs can estimate their own hallucination risk before response generation. We analyze the internal mechanisms of LLMs broadly both in terms of training data sources and across 15 diverse Natural Language Generation (NLG) tasks, spanning over 700 datasets. Our empirical analysis reveals two key insights: (1) LLM internal states indicate whether they have seen the query in training data or not; and (2) LLM internal states show they are likely to hallucinate or not regarding the query. Our study explores particular neurons, activation layers, and tokens that play a crucial role in the LLM perception of uncertainty and hallucination risk. By a probing estimator, we leverage LLM self-assessment, achieving an average hallucination estimation accuracy of 84.32\% at run time.
The Pyramid of Captions
May 01, 2024We introduce a formal information-theoretic framework for image captioning by regarding it as a representation learning task. Our framework defines three key objectives: task sufficiency, minimal redundancy, and human interpretability. Building upon this foundation, we propose a novel Pyramid of Captions (PoCa) method, which constructs caption pyramids by generating localized captions for zoomed-in image patches and integrating them with global caption information using large language models. This approach leverages intuition that the detailed examination of local patches can reduce error risks and address inaccuracies in global captions, either by correcting the hallucination or adding missing details. Based on our theoretical framework, we formalize this intuition and provide formal proof demonstrating the effectiveness of PoCa under certain assumptions. Empirical tests with various image captioning models and large language models show that PoCa consistently yields more informative and semantically aligned captions, maintaining brevity and interpretability.
High-Dimension Human Value Representation in Large Language Models
Apr 11, 2024



The widespread application of Large Language Models (LLMs) across various tasks and fields has necessitated the alignment of these models with human values and preferences. Given various approaches of human value alignment, ranging from Reinforcement Learning with Human Feedback (RLHF), to constitutional learning, etc. there is an urgent need to understand the scope and nature of human values injected into these models before their release. There is also a need for model alignment without a costly large scale human annotation effort. We propose UniVaR, a high-dimensional representation of human value distributions in LLMs, orthogonal to model architecture and training data. Trained from the value-relevant output of eight multilingual LLMs and tested on the output from four multilingual LLMs, namely LlaMA2, ChatGPT, JAIS and Yi, we show that UniVaR is a powerful tool to compare the distribution of human values embedded in different LLMs with different langauge sources. Through UniVaR, we explore how different LLMs prioritize various values in different languages and cultures, shedding light on the complex interplay between human values and language modeling.