 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaWeb: Model-Based Reinforcement Learning of Web Agents
Jan 29, 2026The development of autonomous web agents, powered by Large Language Models (LLMs) and reinforcement learning (RL), represents a significant step towards general-purpose AI assistants. However, training these agents is severely hampered by the challenges of interacting with the live internet, which is inefficient, costly, and fraught with risks. Model-based reinforcement learning (MBRL) offers a promising solution by learning a world model of the environment to enable simulated interaction. This paper introduces DynaWeb, a novel MBRL framework that trains web agents through interacting with a web world model trained to predict naturalistic web page representations given agent actions. This model serves as a synthetic web environment where an agent policy can dream by generating vast quantities of rollout action trajectories for efficient online reinforcement learning. Beyond free policy rollouts, DynaWeb incorporates real expert trajectories from training data, which are randomly interleaved with on-policy rollouts during training to improve stability and sample efficiency. Experiments conducted on the challenging WebArena and WebVoyager benchmarks demonstrate that DynaWeb consistently and significantly improves the performance of state-of-the-art open-source web agent models. Our findings establish the viability of training web agents through imagination, offering a scalable and efficient way to scale up online agentic RL.
WorldPrediction: A Benchmark for High-level World Modeling and Long-horizon Procedural Planning
Jun 04, 2025Humans are known to have an internal "world model" that enables us to carry out action planning based on world states. AI agents need to have such a world model for action planning as well. It is not clear how current AI models, especially generative models, are able to learn such world models and carry out procedural planning in diverse environments. We introduce WorldPrediction, a video-based benchmark for evaluating world modeling and procedural planning capabilities of different AI models. In contrast to prior benchmarks that focus primarily on low-level world modeling and robotic motion planning, WorldPrediction is the first benchmark that emphasizes actions with temporal and semantic abstraction. Given initial and final world states, the task is to distinguish the proper action (WorldPrediction-WM) or the properly ordered sequence of actions (WorldPrediction-PP) from a set of counterfactual distractors. This discriminative task setup enable us to evaluate different types of world models and planners and realize a thorough comparison across different hypothesis. The benchmark represents states and actions using visual observations. In order to prevent models from exploiting low-level continuity cues in background scenes, we provide "action equivalents" - identical actions observed in different contexts - as candidates for selection. This benchmark is grounded in a formal framework of partially observable semi-MDP, ensuring better reliability and robustness of the evaluation. We conduct extensive human filtering and validation on our benchmark and show that current frontier models barely achieve 57% accuracy on WorldPrediction-WM and 38% on WorldPrediction-PP whereas humans are able to solve both tasks perfectly.
HalluLens: LLM Hallucination Benchmark
Apr 24, 2025



Large language models (LLMs) often generate responses that deviate from user input or training data, a phenomenon known as "hallucination." These hallucinations undermine user trust and hinder the adoption of generative AI systems. Addressing hallucinations is essential for the advancement of LLMs. This paper introduces a comprehensive hallucination benchmark, incorporating both new extrinsic and existing intrinsic evaluation tasks, built upon clear taxonomy of hallucination. A major challenge in benchmarking hallucinations is the lack of a unified framework due to inconsistent definitions and categorizations. We disentangle LLM hallucination from "factuality," proposing a clear taxonomy that distinguishes between extrinsic and intrinsic hallucinations, to promote consistency and facilitate research. Extrinsic hallucinations, where the generated content is not consistent with the training data, are increasingly important as LLMs evolve. Our benchmark includes dynamic test set generation to mitigate data leakage and ensure robustness against such leakage. We also analyze existing benchmarks, highlighting their limitations and saturation. The work aims to: (1) establish a clear taxonomy of hallucinations, (2) introduce new extrinsic hallucination tasks, with data that can be dynamically regenerated to prevent saturation by leakage, (3) provide a comprehensive analysis of existing benchmarks, distinguishing them from factuality evaluations.
Calibrating Verbal Uncertainty as a Linear Feature to Reduce Hallucinations
Mar 18, 2025



LLMs often adopt an assertive language style also when making false claims. Such ``overconfident hallucinations'' mislead users and erode trust. Achieving the ability to express in language the actual degree of uncertainty around a claim is therefore of great importance. We find that ``verbal uncertainty'' is governed by a single linear feature in the representation space of LLMs, and show that this has only moderate correlation with the actual ``semantic uncertainty'' of the model. We apply this insight and show that (1) the mismatch between semantic and verbal uncertainty is a better predictor of hallucinations than semantic uncertainty alone and (2) we can intervene on verbal uncertainty at inference time and reduce hallucinations on short-form answers, achieving an average relative reduction of 32%.
Delusions of Large Language Models
Mar 09, 2025Large Language Models often generate factually incorrect but plausible outputs, known as hallucinations. We identify a more insidious phenomenon, LLM delusion, defined as high belief hallucinations, incorrect outputs with abnormally high confidence, making them harder to detect and mitigate. Unlike ordinary hallucinations, delusions persist with low uncertainty, posing significant challenges to model reliability. Through empirical analysis across different model families and sizes on several Question Answering tasks, we show that delusions are prevalent and distinct from hallucinations. LLMs exhibit lower honesty with delusions, which are harder to override via finetuning or self reflection. We link delusion formation with training dynamics and dataset noise and explore mitigation strategies such as retrieval augmented generation and multi agent debating to mitigate delusions. By systematically investigating the nature, prevalence, and mitigation of LLM delusions, our study provides insights into the underlying causes of this phenomenon and outlines future directions for improving model reliability.
Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA
Oct 28, 2024



Large language models (LLMs) are expensive to deploy. Parameter sharing offers a possible path towards reducing their size and cost, but its effectiveness in modern LLMs remains fairly limited. In this work, we revisit "layer tying" as form of parameter sharing in Transformers, and introduce novel methods for converting existing LLMs into smaller "Recursive Transformers" that share parameters across layers, with minimal loss of performance. Here, our Recursive Transformers are efficiently initialized from standard pretrained Transformers, but only use a single block of unique layers that is then repeated multiple times in a loop. We further improve performance by introducing Relaxed Recursive Transformers that add flexibility to the layer tying constraint via depth-wise low-rank adaptation (LoRA) modules, yet still preserve the compactness of the overall model. We show that our recursive models (e.g., recursive Gemma 1B) outperform both similar-sized vanilla pretrained models (such as TinyLlama 1.1B and Pythia 1B) and knowledge distillation baselines -- and can even recover most of the performance of the original "full-size" model (e.g., Gemma 2B with no shared parameters). Finally, we propose Continuous Depth-wise Batching, a promising new inference paradigm enabled by the Recursive Transformer when paired with early exiting. In a theoretical analysis, we show that this has the potential to lead to significant (2-3x) gains in inference throughput.
ANAH-v2: Scaling Analytical Hallucination Annotation of Large Language Models
Jul 05, 2024



Large language models (LLMs) exhibit hallucinations in long-form question-answering tasks across various domains and wide applications. Current hallucination detection and mitigation datasets are limited in domains and sizes, which struggle to scale due to prohibitive labor costs and insufficient reliability of existing hallucination annotators. To facilitate the scalable oversight of LLM hallucinations, this paper introduces an iterative self-training framework that simultaneously and progressively scales up the hallucination annotation dataset and improves the accuracy of the hallucination annotator. Based on the Expectation Maximization (EM) algorithm, in each iteration, the framework first applies a hallucination annotation pipeline to annotate a scaled dataset and then trains a more accurate hallucination annotator on the dataset. This new hallucination annotator is adopted in the hallucination annotation pipeline used for the next iteration. Extensive experimental results demonstrate that the finally obtained hallucination annotator with only 7B parameters surpasses the performance of GPT-4 and obtains new state-of-the-art hallucination detection results on HaluEval and HalluQA by zero-shot inference. Such an annotator can not only evaluate the hallucination levels of various LLMs on the large-scale dataset but also help to mitigate the hallucination of LLMs generations, with the Natural Language Inference (NLI) metric increasing from 25% to 37% on HaluEval.
LLM Internal States Reveal Hallucination Risk Faced With a Query
Jul 03, 2024The hallucination problem of Large Language Models (LLMs) significantly limits their reliability and trustworthiness. Humans have a self-awareness process that allows us to recognize what we don't know when faced with queries. Inspired by this, our paper investigates whether LLMs can estimate their own hallucination risk before response generation. We analyze the internal mechanisms of LLMs broadly both in terms of training data sources and across 15 diverse Natural Language Generation (NLG) tasks, spanning over 700 datasets. Our empirical analysis reveals two key insights: (1) LLM internal states indicate whether they have seen the query in training data or not; and (2) LLM internal states show they are likely to hallucinate or not regarding the query. Our study explores particular neurons, activation layers, and tokens that play a crucial role in the LLM perception of uncertainty and hallucination risk. By a probing estimator, we leverage LLM self-assessment, achieving an average hallucination estimation accuracy of 84.32\% at run time.
Efficient Document Ranking with Learnable Late Interactions
Jun 25, 2024



Cross-Encoder (CE) and Dual-Encoder (DE) models are two fundamental approaches for query-document relevance in information retrieval. To predict relevance, CE models use joint query-document embeddings, while DE models maintain factorized query and document embeddings; usually, the former has higher quality while the latter benefits from lower latency. Recently, late-interaction models have been proposed to realize more favorable latency-quality tradeoffs, by using a DE structure followed by a lightweight scorer based on query and document token embeddings. However, these lightweight scorers are often hand-crafted, and there is no understanding of their approximation power; further, such scorers require access to individual document token embeddings, which imposes an increased latency and storage burden. In this paper, we propose novel learnable late-interaction models (LITE) that resolve these issues. Theoretically, we prove that LITE is a universal approximator of continuous scoring functions, even for relatively small embedding dimension. Empirically, LITE outperforms previous late-interaction models such as ColBERT on both in-domain and zero-shot re-ranking tasks. For instance, experiments on MS MARCO passage re-ranking show that LITE not only yields a model with better generalization, but also lowers latency and requires 0.25x storage compared to ColBERT.
ANAH: Analytical Annotation of Hallucinations in Large Language Models
May 30, 2024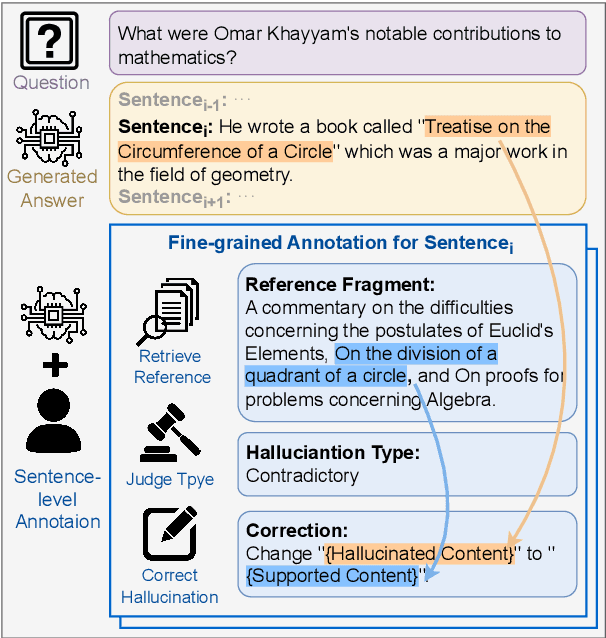
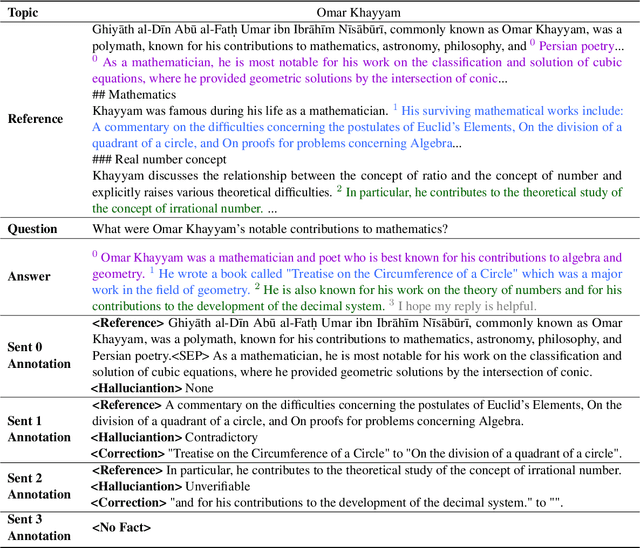
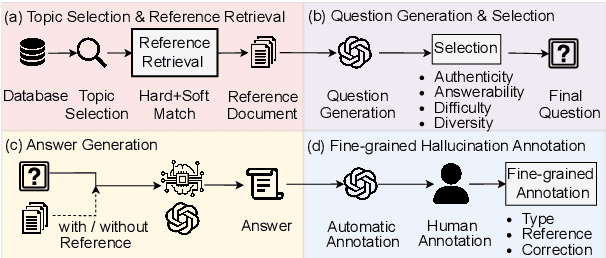

Reducing the `$\textit{hallucination}$' problem of Large Language Models (LLMs) is crucial for their wide applications. A comprehensive and fine-grained measurement of the hallucination is the first key step for the governance of this issue but is under-explored in the community. Thus, we present $\textbf{ANAH}$, a bilingual dataset that offers $\textbf{AN}$alytical $\textbf{A}$nnotation of $\textbf{H}$allucinations in LLMs within Generative Question Answering. Each answer sentence in our dataset undergoes rigorous annotation, involving the retrieval of a reference fragment, the judgment of the hallucination type, and the correction of hallucinated content. ANAH consists of ~12k sentence-level annotations for ~4.3k LLM responses covering over 700 topics, constructed by a human-in-the-loop pipeline. Thanks to the fine granularity of the hallucination annotations, we can quantitatively confirm that the hallucinations of LLMs progressively accumulate in the answer and use ANAH to train and evaluate hallucination annotators. We conduct extensive experiments on studying generative and discriminative annotators and show that, although current open-source LLMs have difficulties in fine-grained hallucination annotation, the generative annotator trained with ANAH can surpass all open-source LLMs and GPT-3.5, obtain performance competitive with GPT-4, and exhibits better generalization ability on unseen questions.