 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
Long-horizon Reasoning Agent for Olympiad-Level Mathematical Problem Solving
Dec 12, 2025Large Reasoning Models (LRMs) have expanded the mathematical reasoning frontier through Chain-of-Thought (CoT) techniques and Reinforcement Learning with Verifiable Rewards (RLVR), capable of solving AIME-level problems. However, the performance of LRMs is heavily dependent on the extended reasoning context length. For solving ultra-hard problems like those in the International Mathematical Olympiad (IMO), the required reasoning complexity surpasses the space that an LRM can explore in a single round. Previous works attempt to extend the reasoning context of LRMs but remain prompt-based and built upon proprietary models, lacking systematic structures and training pipelines. Therefore, this paper introduces Intern-S1-MO, a long-horizon math agent that conducts multi-round hierarchical reasoning, composed of an LRM-based multi-agent system including reasoning, summary, and verification. By maintaining a compact memory in the form of lemmas, Intern-S1-MO can more freely explore the lemma-rich reasoning spaces in multiple reasoning stages, thereby breaking through the context constraints for IMO-level math problems. Furthermore, we propose OREAL-H, an RL framework for training the LRM using the online explored trajectories to simultaneously bootstrap the reasoning ability of LRM and elevate the overall performance of Intern-S1-MO. Experiments show that Intern-S1-MO can obtain 26 out of 35 points on the non-geometry problems of IMO2025, matching the performance of silver medalists. It also surpasses the current advanced LRMs on inference benchmarks such as HMMT2025, AIME2025, and CNMO2025. In addition, our agent officially participates in CMO2025 and achieves a score of 102/126 under the judgment of human experts, reaching the gold medal level.
InternBootcamp Technical Report: Boosting LLM Reasoning with Verifiable Task Scaling
Aug 12, 2025



Large language models (LLMs) have revolutionized artificial intelligence by enabling complex reasoning capabilities. While recent advancements in reinforcement learning (RL) have primarily focused on domain-specific reasoning tasks (e.g., mathematics or code generation), real-world reasoning scenarios often require models to handle diverse and complex environments that narrow-domain benchmarks cannot fully capture. To address this gap, we present InternBootcamp, an open-source framework comprising 1000+ domain-diverse task environments specifically designed for LLM reasoning research. Our codebase offers two key functionalities: (1) automated generation of unlimited training/testing cases with configurable difficulty levels, and (2) integrated verification modules for objective response evaluation. These features make InternBootcamp fundamental infrastructure for RL-based model optimization, synthetic data generation, and model evaluation. Although manually developing such a framework with enormous task coverage is extremely cumbersome, we accelerate the development procedure through an automated agent workflow supplemented by manual validation protocols, which enables the task scope to expand rapidly. % With these bootcamps, we further establish Bootcamp-EVAL, an automatically generated benchmark for comprehensive performance assessment. Evaluation reveals that frontier models still underperform in many reasoning tasks, while training with InternBootcamp provides an effective way to significantly improve performance, leading to our 32B model that achieves state-of-the-art results on Bootcamp-EVAL and excels on other established benchmarks. In particular, we validate that consistent performance gains come from including more training tasks, namely \textbf{task scaling}, over two orders of magnitude, offering a promising route towards capable reasoning generalist.
The Imitation Game: Turing Machine Imitator is Length Generalizable Reasoner
Jul 17, 2025Length generalization, the ability to solve problems of longer sequences than those observed during training, poses a core challenge of Transformer-based large language models (LLM). Although existing studies have predominantly focused on data-driven approaches for arithmetic operations and symbolic manipulation tasks, these approaches tend to be task-specific with limited overall performance. To pursue a more general solution, this paper focuses on a broader case of reasoning problems that are computable, i.e., problems that algorithms can solve, thus can be solved by the Turing Machine. From this perspective, this paper proposes Turing MAchine Imitation Learning (TAIL) to improve the length generalization ability of LLMs. TAIL synthesizes chain-of-thoughts (CoT) data that imitate the execution process of a Turing Machine by computer programs, which linearly expands the reasoning steps into atomic states to alleviate shortcut learning and explicit memory fetch mechanism to reduce the difficulties of dynamic and long-range data access in elementary operations. To validate the reliability and universality of TAIL, we construct a challenging synthetic dataset covering 8 classes of algorithms and 18 tasks. Without bells and whistles, TAIL significantly improves the length generalization ability as well as the performance of Qwen2.5-7B on various tasks using only synthetic data, surpassing previous methods and DeepSeek-R1. The experimental results reveal that the key concepts in the Turing Machine, instead of the thinking styles, are indispensable for TAIL for length generalization, through which the model exhibits read-and-write behaviors consistent with the properties of the Turing Machine in their attention layers. This work provides a promising direction for future research in the learning of LLM reasoning from synthetic data.
Mask-DPO: Generalizable Fine-grained Factuality Alignment of LLMs
Mar 04, 2025Large language models (LLMs) exhibit hallucinations (i.e., unfaithful or nonsensical information) when serving as AI assistants in various domains. Since hallucinations always come with truthful content in the LLM responses, previous factuality alignment methods that conduct response-level preference learning inevitably introduced noises during training. Therefore, this paper proposes a fine-grained factuality alignment method based on Direct Preference Optimization (DPO), called Mask-DPO. Incorporating sentence-level factuality as mask signals, Mask-DPO only learns from factually correct sentences in the preferred samples and prevents the penalty on factual contents in the not preferred samples, which resolves the ambiguity in the preference learning. Extensive experimental results demonstrate that Mask-DPO can significantly improve the factuality of LLMs responses to questions from both in-domain and out-of-domain datasets, although these questions and their corresponding topics are unseen during training. Only trained on the ANAH train set, the score of Llama3.1-8B-Instruct on the ANAH test set is improved from 49.19% to 77.53%, even surpassing the score of Llama3.1-70B-Instruct (53.44%), while its FactScore on the out-of-domain Biography dataset is also improved from 30.29% to 39.39%. We further study the generalization property of Mask-DPO using different training sample scaling strategies and find that scaling the number of topics in the dataset is more effective than the number of questions. We provide a hypothesis of what factual alignment is doing with LLMs, on the implication of this phenomenon, and conduct proof-of-concept experiments to verify it. We hope the method and the findings pave the way for future research on scaling factuality alignment.
Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning
Feb 10, 2025Reasoning abilities, especially those for solving complex math problems, are crucial components of general intelligence. Recent advances by proprietary companies, such as o-series models of OpenAI, have made remarkable progress on reasoning tasks. However, the complete technical details remain unrevealed, and the techniques that are believed certainly to be adopted are only reinforcement learning (RL) and the long chain of thoughts. This paper proposes a new RL framework, termed OREAL, to pursue the performance limit that can be achieved through \textbf{O}utcome \textbf{RE}w\textbf{A}rd-based reinforcement \textbf{L}earning for mathematical reasoning tasks, where only binary outcome rewards are easily accessible. We theoretically prove that behavior cloning on positive trajectories from best-of-N (BoN) sampling is sufficient to learn the KL-regularized optimal policy in binary feedback environments. This formulation further implies that the rewards of negative samples should be reshaped to ensure the gradient consistency between positive and negative samples. To alleviate the long-existing difficulties brought by sparse rewards in RL, which are even exacerbated by the partial correctness of the long chain of thought for reasoning tasks, we further apply a token-level reward model to sample important tokens in reasoning trajectories for learning. With OREAL, for the first time, a 7B model can obtain 94.0 pass@1 accuracy on MATH-500 through RL, being on par with 32B models. OREAL-32B also surpasses previous 32B models trained by distillation with 95.0 pass@1 accuracy on MATH-500. Our investigation also indicates the importance of initial policy models and training queries for RL. Code, models, and data will be released to benefit future research\footnote{https://github.com/InternLM/OREAL}.
Training Language Models to Critique With Multi-agent Feedback
Oct 20, 2024
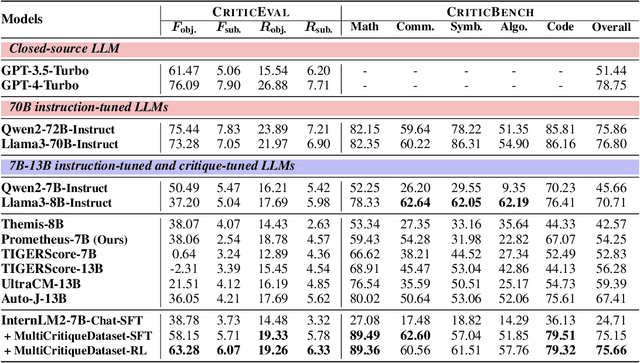
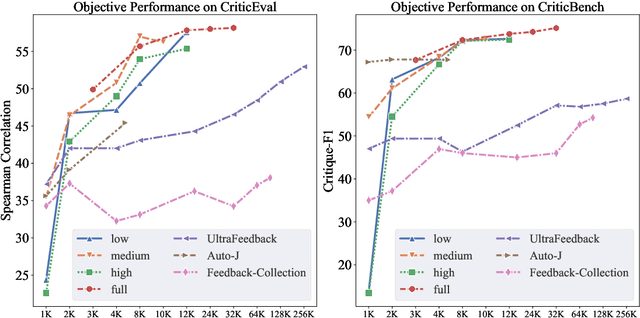
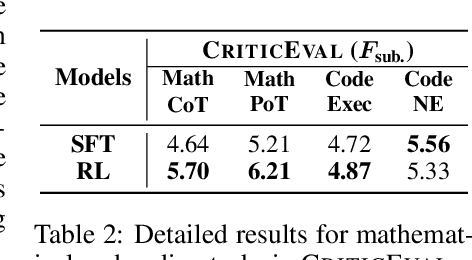
Critique ability, a meta-cognitive capability of humans, presents significant challenges for LLMs to improve. Recent works primarily rely on supervised fine-tuning (SFT) using critiques generated by a single LLM like GPT-4. However, these model-generated critiques often exhibit flaws due to the inherent complexity of the critique. Consequently, fine-tuning LLMs on such flawed critiques typically limits the model's performance and propagates these flaws into the learned model. To overcome these challenges, this paper proposes a novel data generation pipeline, named MultiCritique, that improves the critique ability of LLMs by utilizing multi-agent feedback in both the SFT and reinforcement learning (RL) stages. First, our data generation pipeline aggregates high-quality critiques from multiple agents instead of a single model, with crucial information as input for simplifying the critique. Furthermore, our pipeline improves the preference accuracy of critique quality through multi-agent feedback, facilitating the effectiveness of RL in improving the critique ability of LLMs. Based on our proposed MultiCritique data generation pipeline, we construct the MultiCritiqueDataset for the SFT and RL fine-tuning stages. Extensive experimental results on two benchmarks demonstrate: 1) the superior quality of our constructed SFT dataset compared to existing critique datasets; 2) additional improvements to the critique ability of LLMs brought by the RL stage. Notably, our fine-tuned 7B model significantly surpasses other advanced 7B-13B open-source models, approaching the performance of advanced 70B LLMs and GPT-4. Codes, datasets and model weights will be publicly available.
ANAH-v2: Scaling Analytical Hallucination Annotation of Large Language Models
Jul 05, 2024



Large language models (LLMs) exhibit hallucinations in long-form question-answering tasks across various domains and wide applications. Current hallucination detection and mitigation datasets are limited in domains and sizes, which struggle to scale due to prohibitive labor costs and insufficient reliability of existing hallucination annotators. To facilitate the scalable oversight of LLM hallucinations, this paper introduces an iterative self-training framework that simultaneously and progressively scales up the hallucination annotation dataset and improves the accuracy of the hallucination annotator. Based on the Expectation Maximization (EM) algorithm, in each iteration, the framework first applies a hallucination annotation pipeline to annotate a scaled dataset and then trains a more accurate hallucination annotator on the dataset. This new hallucination annotator is adopted in the hallucination annotation pipeline used for the next iteration. Extensive experimental results demonstrate that the finally obtained hallucination annotator with only 7B parameters surpasses the performance of GPT-4 and obtains new state-of-the-art hallucination detection results on HaluEval and HalluQA by zero-shot inference. Such an annotator can not only evaluate the hallucination levels of various LLMs on the large-scale dataset but also help to mitigate the hallucination of LLMs generations, with the Natural Language Inference (NLI) metric increasing from 25% to 37% on HaluEval.
ANAH: Analytical Annotation of Hallucinations in Large Language Models
May 30, 2024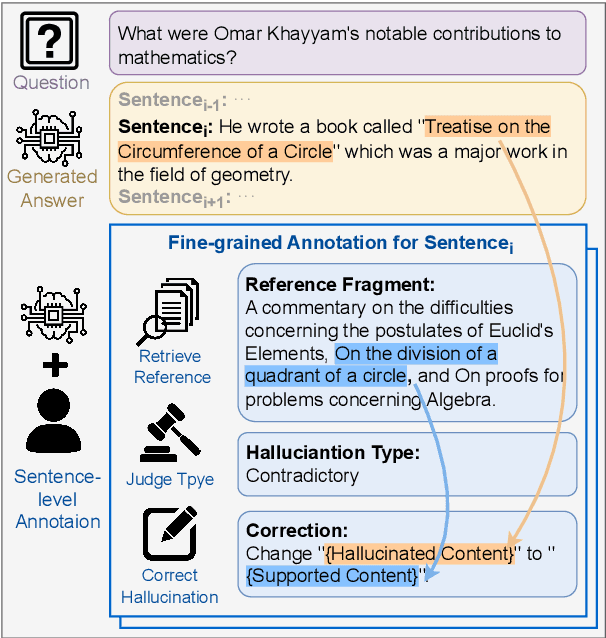
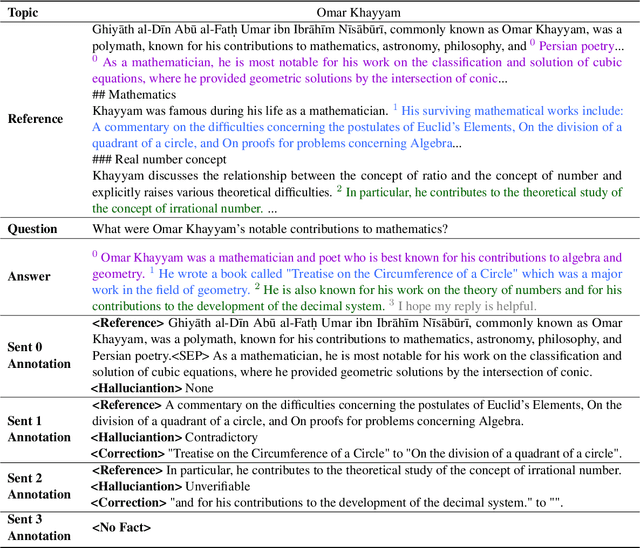
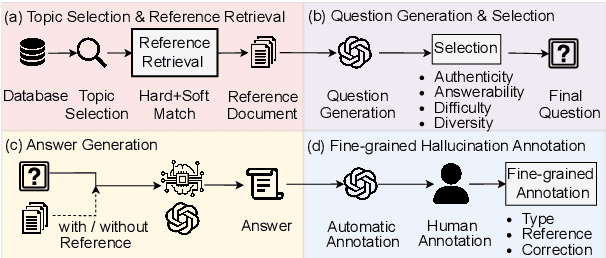

Reducing the `$\textit{hallucination}$' problem of Large Language Models (LLMs) is crucial for their wide applications. A comprehensive and fine-grained measurement of the hallucination is the first key step for the governance of this issue but is under-explored in the community. Thus, we present $\textbf{ANAH}$, a bilingual dataset that offers $\textbf{AN}$alytical $\textbf{A}$nnotation of $\textbf{H}$allucinations in LLMs within Generative Question Answering. Each answer sentence in our dataset undergoes rigorous annotation, involving the retrieval of a reference fragment, the judgment of the hallucination type, and the correction of hallucinated content. ANAH consists of ~12k sentence-level annotations for ~4.3k LLM responses covering over 700 topics, constructed by a human-in-the-loop pipeline. Thanks to the fine granularity of the hallucination annotations, we can quantitatively confirm that the hallucinations of LLMs progressively accumulate in the answer and use ANAH to train and evaluate hallucination annotators. We conduct extensive experiments on studying generative and discriminative annotators and show that, although current open-source LLMs have difficulties in fine-grained hallucination annotation, the generative annotator trained with ANAH can surpass all open-source LLMs and GPT-3.5, obtain performance competitive with GPT-4, and exhibits better generalization ability on unseen questions.
AlchemistCoder: Harmonizing and Eliciting Code Capability by Hindsight Tuning on Multi-source Data
May 29, 2024Open-source Large Language Models (LLMs) and their specialized variants, particularly Code LLMs, have recently delivered impressive performance. However, previous Code LLMs are typically fine-tuned on single-source data with limited quality and diversity, which may insufficiently elicit the potential of pre-trained Code LLMs. In this paper, we present AlchemistCoder, a series of Code LLMs with enhanced code generation and generalization capabilities fine-tuned on multi-source data. To achieve this, we pioneer to unveil inherent conflicts among the various styles and qualities in multi-source code corpora and introduce data-specific prompts with hindsight relabeling, termed AlchemistPrompts, to harmonize different data sources and instruction-response pairs. Additionally, we propose incorporating the data construction process into the fine-tuning data as code comprehension tasks, including instruction evolution, data filtering, and code review. Extensive experiments demonstrate that AlchemistCoder holds a clear lead among all models of the same size (6.7B/7B) and rivals or even surpasses larger models (15B/33B/70B), showcasing the efficacy of our method in refining instruction-following capabilities and advancing the boundaries of code intelligence.