 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOdysseyArena: Benchmarking Large Language Models For Long-Horizon, Active and Inductive Interactions
Feb 05, 2026The rapid advancement of Large Language Models (LLMs) has catalyzed the development of autonomous agents capable of navigating complex environments. However, existing evaluations primarily adopt a deductive paradigm, where agents execute tasks based on explicitly provided rules and static goals, often within limited planning horizons. Crucially, this neglects the inductive necessity for agents to discover latent transition laws from experience autonomously, which is the cornerstone for enabling agentic foresight and sustaining strategic coherence. To bridge this gap, we introduce OdysseyArena, which re-centers agent evaluation on long-horizon, active, and inductive interactions. We formalize and instantiate four primitives, translating abstract transition dynamics into concrete interactive environments. Building upon this, we establish OdysseyArena-Lite for standardized benchmarking, providing a set of 120 tasks to measure an agent's inductive efficiency and long-horizon discovery. Pushing further, we introduce OdysseyArena-Challenge to stress-test agent stability across extreme interaction horizons (e.g., > 200 steps). Extensive experiments on 15+ leading LLMs reveal that even frontier models exhibit a deficiency in inductive scenarios, identifying a critical bottleneck in the pursuit of autonomous discovery in complex environments. Our code and data are available at https://github.com/xufangzhi/Odyssey-Arena
Steering LLMs via Scalable Interactive Oversight
Feb 04, 2026As Large Language Models increasingly automate complex, long-horizon tasks such as \emph{vibe coding}, a supervision gap has emerged. While models excel at execution, users often struggle to guide them effectively due to insufficient domain expertise, the difficulty of articulating precise intent, and the inability to reliably validate complex outputs. It presents a critical challenge in scalable oversight: enabling humans to responsibly steer AI systems on tasks that surpass their own ability to specify or verify. To tackle this, we propose Scalable Interactive Oversight, a framework that decomposes complex intent into a recursive tree of manageable decisions to amplify human supervision. Rather than relying on open-ended prompting, our system elicits low-burden feedback at each node and recursively aggregates these signals into precise global guidance. Validated in web development task, our framework enables non-experts to produce expert-level Product Requirement Documents, achieving a 54\% improvement in alignment. Crucially, we demonstrate that this framework can be optimized via Reinforcement Learning using only online user feedback, offering a practical pathway for maintaining human control as AI scales.
TIDE: Trajectory-based Diagnostic Evaluation of Test-Time Improvement in LLM Agents
Feb 03, 2026Recent advances in autonomous LLM agents demonstrate their ability to improve performance through iterative interaction with the environment. We define this paradigm as Test-Time Improvement (TTI). However, the mechanisms under how and why TTI succeed or fail remain poorly understood, and existing evaluation metrics fail to capture their task optimization efficiency, behavior adaptation after erroneous actions, and the specific utility of working memory for task completion. To address these gaps, we propose Test-time Improvement Diagnostic Evaluation (TIDE), an agent-agnostic and environment-agnostic framework that decomposes TTI into three comprehensive and interconnected dimensions. The framework measures (1) the overall temporal dynamics of task completion and (2) identifies whether performance is primarily constrained by recursive looping behaviors or (3) by burdensome accumulated memory. Through extensive experiments across diverse agents and environments, TIDE highlights that improving agent performance requires more than scaling internal reasoning, calling for explicitly optimizing the interaction dynamics between the agent and the environment.
Forget What's Sensitive, Remember What Matters: Token-Level Differential Privacy in Memory Sculpting for Continual Learning
Sep 16, 2025
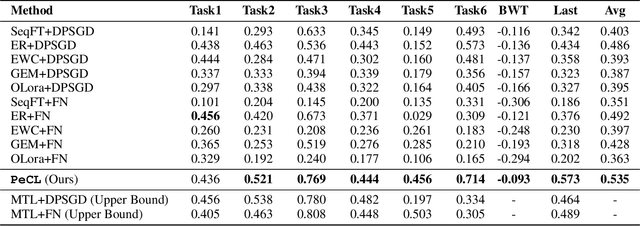
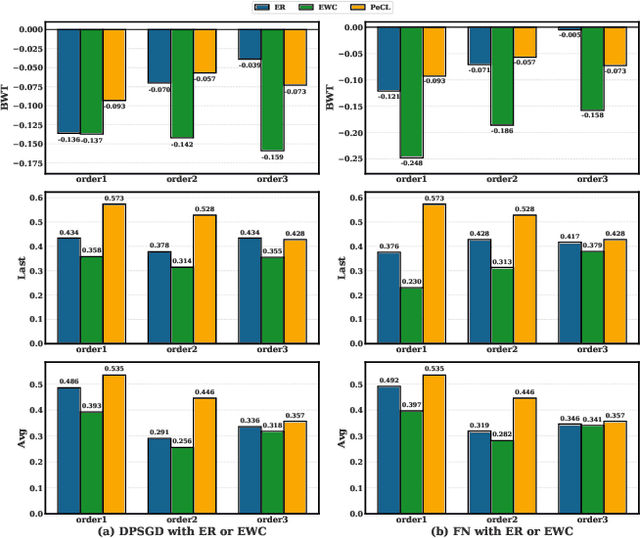

Continual Learning (CL) models, while adept at sequential knowledge acquisition, face significant and often overlooked privacy challenges due to accumulating diverse information. Traditional privacy methods, like a uniform Differential Privacy (DP) budget, indiscriminately protect all data, leading to substantial model utility degradation and hindering CL deployment in privacy-sensitive areas. To overcome this, we propose a privacy-enhanced continual learning (PeCL) framework that forgets what's sensitive and remembers what matters. Our approach first introduces a token-level dynamic Differential Privacy strategy that adaptively allocates privacy budgets based on the semantic sensitivity of individual tokens. This ensures robust protection for private entities while minimizing noise injection for non-sensitive, general knowledge. Second, we integrate a privacy-guided memory sculpting module. This module leverages the sensitivity analysis from our dynamic DP mechanism to intelligently forget sensitive information from the model's memory and parameters, while explicitly preserving the task-invariant historical knowledge crucial for mitigating catastrophic forgetting. Extensive experiments show that PeCL achieves a superior balance between privacy preserving and model utility, outperforming baseline models by maintaining high accuracy on previous tasks while ensuring robust privacy.
Black-box Model Merging for Language-Model-as-a-Service with Massive Model Repositories
Sep 16, 2025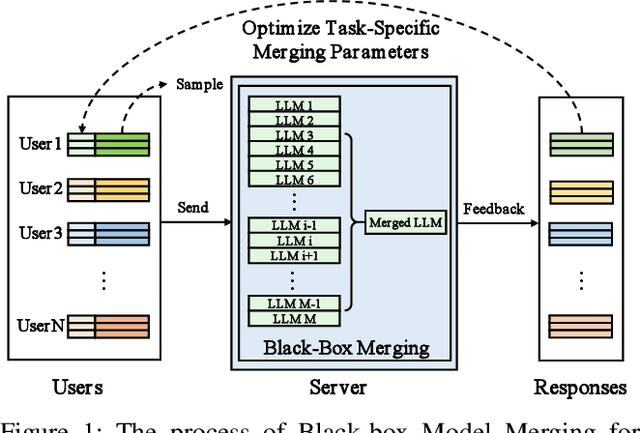
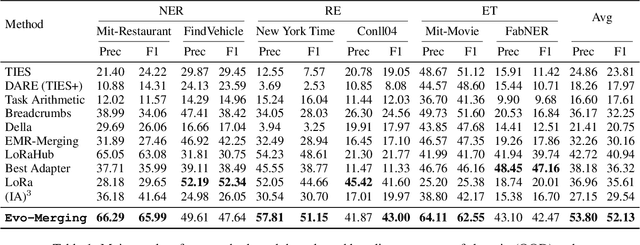
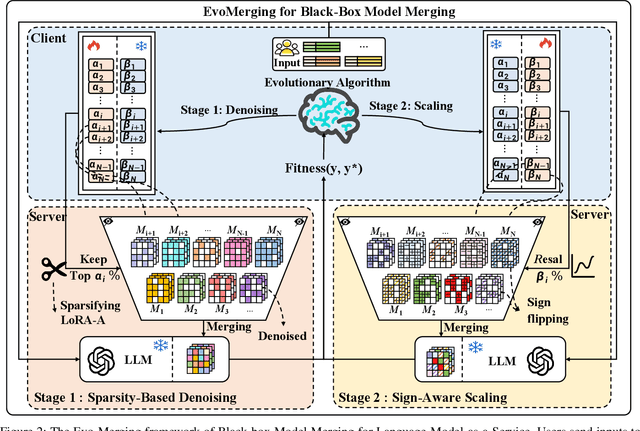
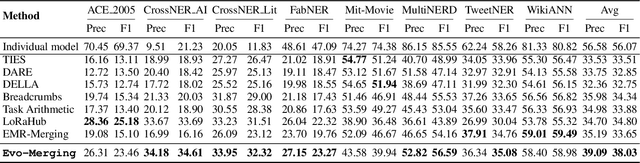
Model merging refers to the process of integrating multiple distinct models into a unified model that preserves and combines the strengths and capabilities of the individual models. Most existing approaches rely on task vectors to combine models, typically under the assumption that model parameters are accessible. However, for extremely large language models (LLMs) such as GPT-4, which are often provided solely as black-box services through API interfaces (Language-Model-as-a-Service), model weights are not available to end users. This presents a significant challenge, which we refer to as black-box model merging (BMM) with massive LLMs. To address this challenge, we propose a derivative-free optimization framework based on the evolutionary algorithm (Evo-Merging) that enables effective model merging using only inference-time API queries. Our method consists of two key components: (1) sparsity-based denoising, designed to identify and filter out irrelevant or redundant information across models, and (2) sign-aware scaling, which dynamically computes optimal combination weights for the relevant models based on their performance. We also provide a formal justification, along with a theoretical analysis, for our asymmetric sparsification. Extensive experimental evaluations demonstrate that our approach achieves state-of-the-art results on a range of tasks, significantly outperforming existing strong baselines.
Building Self-Evolving Agents via Experience-Driven Lifelong Learning: A Framework and Benchmark
Aug 26, 2025As AI advances toward general intelligence, the focus is shifting from systems optimized for static tasks to creating open-ended agents that learn continuously. In this paper, we introduce Experience-driven Lifelong Learning (ELL), a framework for building self-evolving agents capable of continuous growth through real-world interaction. The framework is built on four core principles: (1) Experience Exploration: Agents learn through continuous, self-motivated interaction with dynamic environments, navigating interdependent tasks and generating rich experiential trajectories. (2) Long-term Memory: Agents preserve and structure historical knowledge, including personal experiences, domain expertise, and commonsense reasoning, into a persistent memory system. (3) Skill Learning: Agents autonomously improve by abstracting recurring patterns from experience into reusable skills, which are actively refined and validated for application in new tasks. (4) Knowledge Internalization: Agents internalize explicit and discrete experiences into implicit and intuitive capabilities as "second nature". We also introduce StuLife, a benchmark dataset for ELL that simulates a student's holistic college journey, from enrollment to academic and personal development, across three core phases and ten detailed sub-scenarios. StuLife is designed around three key paradigm shifts: From Passive to Proactive, From Context to Memory, and From Imitation to Learning. In this dynamic environment, agents must acquire and distill practical skills and maintain persistent memory to make decisions based on evolving state variables. StuLife provides a comprehensive platform for evaluating lifelong learning capabilities, including memory retention, skill transfer, and self-motivated behavior. Beyond evaluating SOTA LLMs on the StuLife benchmark, we also explore the role of context engineering in advancing AGI.
Capability Salience Vector: Fine-grained Alignment of Loss and Capabilities for Downstream Task Scaling Law
Jun 16, 2025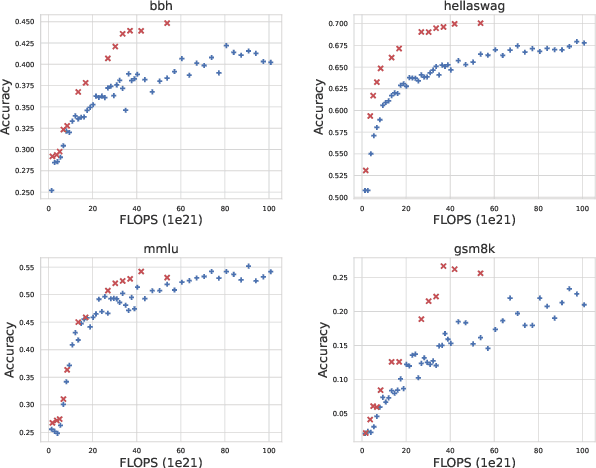
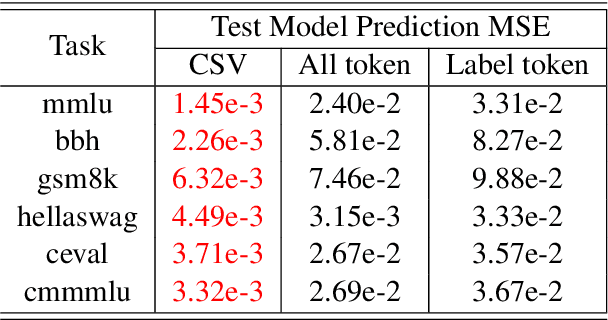
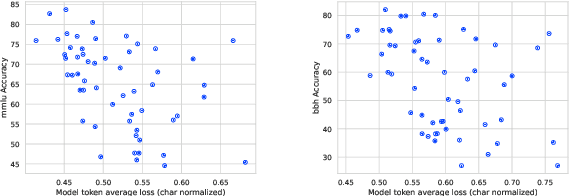
Scaling law builds the relationship between training computation and validation loss, enabling researchers to effectively predict the loss trending of models across different levels of computation. However, a gap still remains between validation loss and the model's downstream capabilities, making it untrivial to apply scaling law to direct performance prediction for downstream tasks. The loss typically represents a cumulative penalty for predicted tokens, which are implicitly considered to have equal importance. Nevertheless, our studies have shown evidence that when considering different training data distributions, we cannot directly model the relationship between downstream capability and computation or token loss. To bridge the gap between validation loss and downstream task capabilities, in this work, we introduce Capability Salience Vector, which decomposes the overall loss and assigns different importance weights to tokens to assess a specific meta-capability, aligning the validation loss with downstream task performance in terms of the model's capabilities. Experiments on various popular benchmarks demonstrate that our proposed Capability Salience Vector could significantly improve the predictability of language model performance on downstream tasks.
Speech-Language Models with Decoupled Tokenizers and Multi-Token Prediction
Jun 14, 2025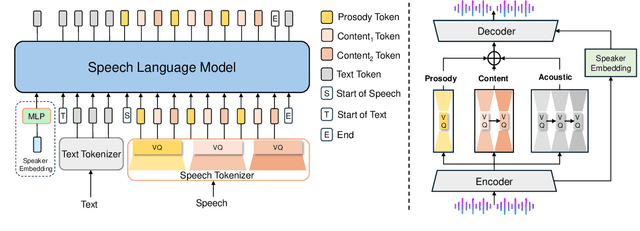
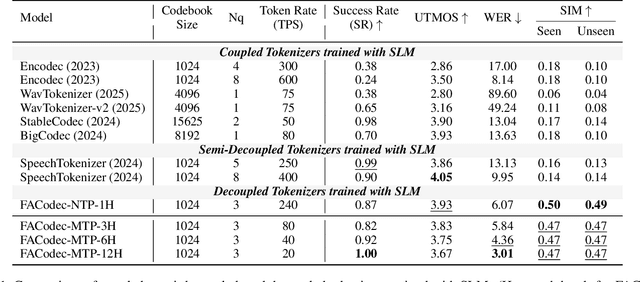
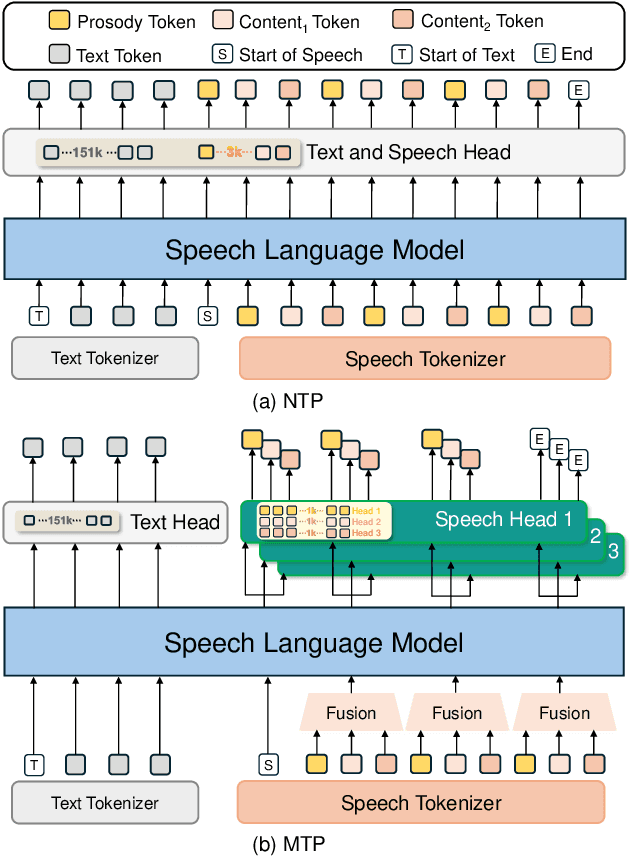
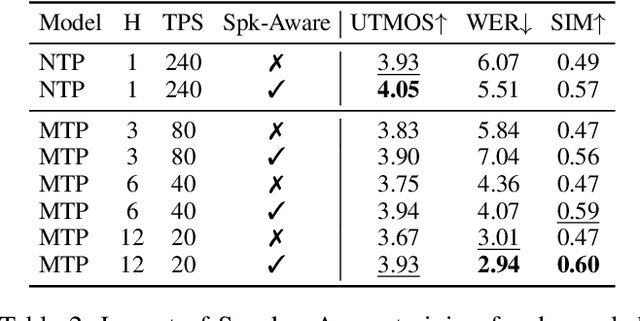
Speech-language models (SLMs) offer a promising path toward unifying speech and text understanding and generation. However, challenges remain in achieving effective cross-modal alignment and high-quality speech generation. In this work, we systematically investigate the impact of key components (i.e., speech tokenizers, speech heads, and speaker modeling) on the performance of LLM-centric SLMs. We compare coupled, semi-decoupled, and fully decoupled speech tokenizers under a fair SLM framework and find that decoupled tokenization significantly improves alignment and synthesis quality. To address the information density mismatch between speech and text, we introduce multi-token prediction (MTP) into SLMs, enabling each hidden state to decode multiple speech tokens. This leads to up to 12$\times$ faster decoding and a substantial drop in word error rate (from 6.07 to 3.01). Furthermore, we propose a speaker-aware generation paradigm and introduce RoleTriviaQA, a large-scale role-playing knowledge QA benchmark with diverse speaker identities. Experiments demonstrate that our methods enhance both knowledge understanding and speaker consistency.
RAGSynth: Synthetic Data for Robust and Faithful RAG Component Optimization
May 16, 2025RAG can enhance the performance of LLMs on knowledge-intensive tasks. Various RAG paradigms, including vanilla, planning-based, and iterative RAG, are built upon 2 cores: the retriever, which should robustly select relevant documents across complex queries, and the generator, which should faithfully synthesize responses. However, existing retrievers rely heavily on public knowledge and struggle with queries of varying logical complexity and clue completeness, while generators frequently face fidelity problems. In this work, we introduce RAGSynth, a framework that includes a data construction modeling and a corresponding synthetic data generation implementation, designed to optimize retriever robustness and generator fidelity. Additionally, we present SynthBench, a benchmark encompassing 8 domain-specific documents across 4 domains, featuring diverse query complexities, clue completeness, and fine-grained citation granularity. Leveraging RAGSynth, we generate a large-scale synthetic dataset, including single and multi-hop. Extensive experiments demonstrate that the synthetic data significantly improves the robustness of the retrievers and the fidelity of the generators. Additional evaluations confirm that RAGSynth can also generalize well across different domains. By integrating the optimized retrievers into various RAG paradigms, we consistently observe enhanced RAG system performance. We have open-sourced the implementation on https://github.com/EachSheep/RAGSynth.
Genius: A Generalizable and Purely Unsupervised Self-Training Framework For Advanced Reasoning
Apr 11, 2025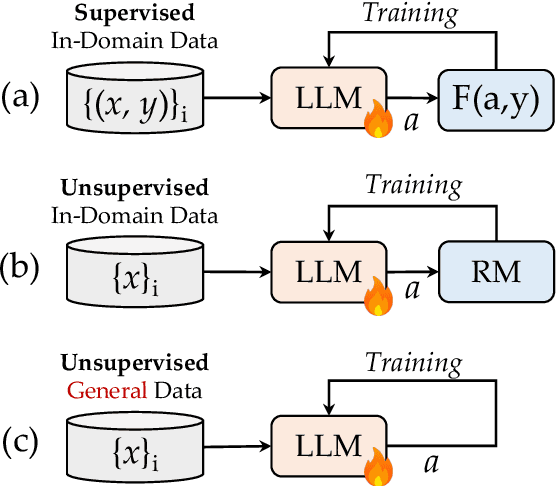
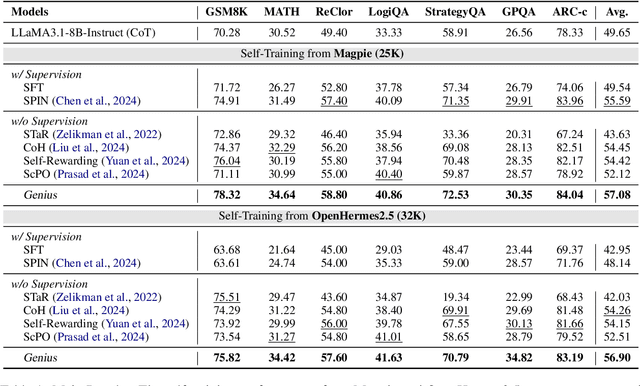
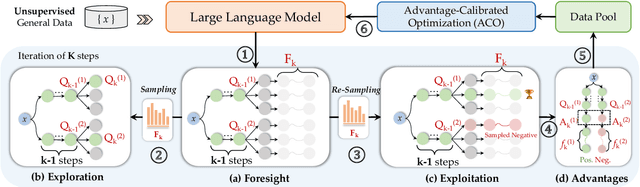

Advancing LLM reasoning skills has captivated wide interest. However, current post-training techniques rely heavily on supervisory signals, such as outcome supervision or auxiliary reward models, which face the problem of scalability and high annotation costs. This motivates us to enhance LLM reasoning without the need for external supervision. We introduce a generalizable and purely unsupervised self-training framework, named Genius. Without external auxiliary, Genius requires to seek the optimal response sequence in a stepwise manner and optimize the LLM. To explore the potential steps and exploit the optimal ones, Genius introduces a stepwise foresight re-sampling strategy to sample and estimate the step value by simulating future outcomes. Further, we recognize that the unsupervised setting inevitably induces the intrinsic noise and uncertainty. To provide a robust optimization, we propose an advantage-calibrated optimization (ACO) loss function to mitigate estimation inconsistencies. Combining these techniques together, Genius provides an advanced initial step towards self-improve LLM reasoning with general queries and without supervision, revolutionizing reasoning scaling laws given the vast availability of general queries. The code will be released at https://github.com/xufangzhi/Genius.