 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
AutoLogi: Automated Generation of Logic Puzzles for Evaluating Reasoning Abilities of Large Language Models
Feb 24, 2025



While logical reasoning evaluation of Large Language Models (LLMs) has attracted significant attention, existing benchmarks predominantly rely on multiple-choice formats that are vulnerable to random guessing, leading to overestimated performance and substantial performance fluctuations. To obtain more accurate assessments of models' reasoning capabilities, we propose an automated method for synthesizing open-ended logic puzzles, and use it to develop a bilingual benchmark, AutoLogi. Our approach features program-based verification and controllable difficulty levels, enabling more reliable evaluation that better distinguishes models' reasoning abilities. Extensive evaluation of eight modern LLMs shows that AutoLogi can better reflect true model capabilities, with performance scores spanning from 35% to 73% compared to the narrower range of 21% to 37% on the source multiple-choice dataset. Beyond benchmark creation, this synthesis method can generate high-quality training data by incorporating program verifiers into the rejection sampling process, enabling systematic enhancement of LLMs' reasoning capabilities across diverse datasets.
Qwen2.5-1M Technical Report
Jan 26, 2025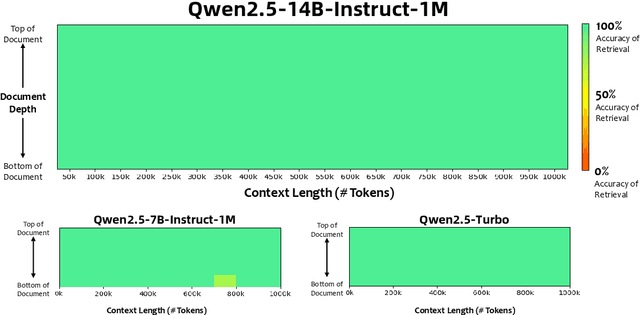

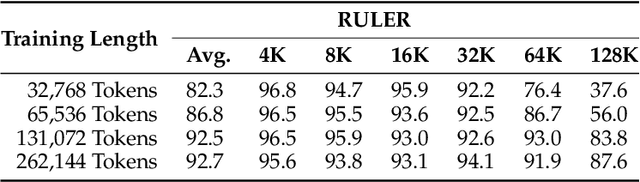
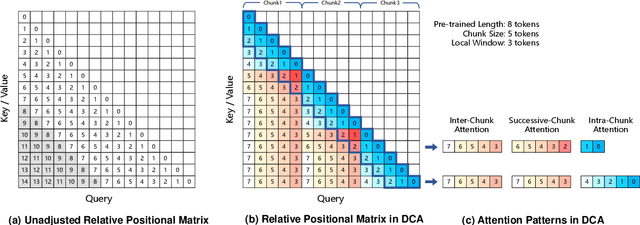
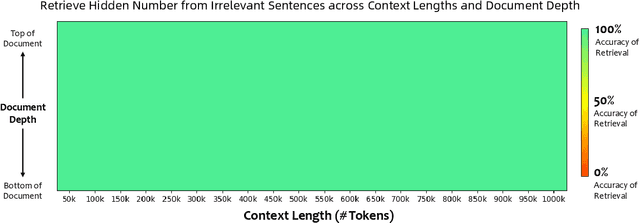
We introduce Qwen2.5-1M, a series of models that extend the context length to 1 million tokens. Compared to the previous 128K version, the Qwen2.5-1M series have significantly enhanced long-context capabilities through long-context pre-training and post-training. Key techniques such as long data synthesis, progressive pre-training, and multi-stage supervised fine-tuning are employed to effectively enhance long-context performance while reducing training costs. To promote the use of long-context models among a broader user base, we present and open-source our inference framework. This framework includes a length extrapolation method that can expand the model context lengths by at least four times, or even more, without additional training. To reduce inference costs, we implement a sparse attention method along with chunked prefill optimization for deployment scenarios and a sparsity refinement method to improve precision. Additionally, we detail our optimizations in the inference engine, including kernel optimization, pipeline parallelism, and scheduling optimization, which significantly enhance overall inference performance. By leveraging our inference framework, the Qwen2.5-1M models achieve a remarkable 3x to 7x prefill speedup in scenarios with 1 million tokens of context. This framework provides an efficient and powerful solution for developing applications that require long-context processing using open-source models. The Qwen2.5-1M series currently includes the open-source models Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, as well as the API-accessed model Qwen2.5-Turbo. Evaluations show that Qwen2.5-1M models have been greatly improved in long-context tasks without compromising performance in short-context scenarios. Specifically, the Qwen2.5-14B-Instruct-1M model significantly outperforms GPT-4o-mini in long-context tasks and supports contexts eight times longer.
Qwen2.5 Technical Report
Dec 19, 2024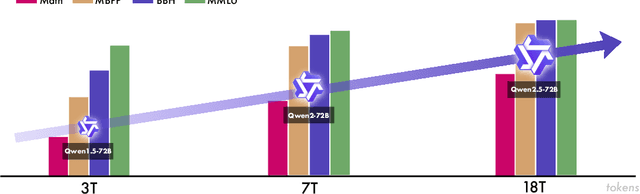

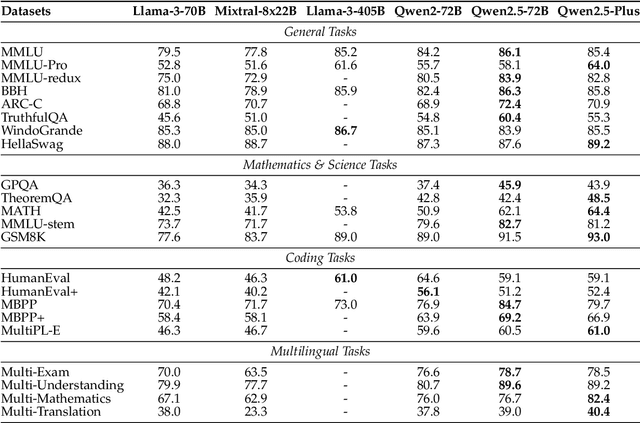
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
Inference-Time Decontamination: Reusing Leaked Benchmarks for Large Language Model Evaluation
Jun 20, 2024
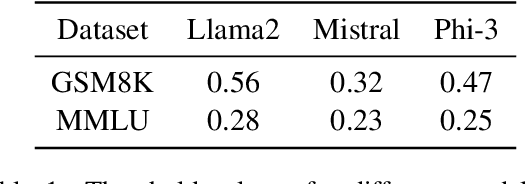


The training process of large language models (LLMs) often involves varying degrees of test data contamination. Although current LLMs are achieving increasingly better performance on various benchmarks, their performance in practical applications does not always match their benchmark results. Leakage of benchmarks can prevent the accurate assessment of LLMs' true performance. However, constructing new benchmarks is costly, labor-intensive and still carries the risk of leakage. Therefore, in this paper, we ask the question, Can we reuse these leaked benchmarks for LLM evaluation? We propose Inference-Time Decontamination (ITD) to address this issue by detecting and rewriting leaked samples without altering their difficulties. ITD can mitigate performance inflation caused by memorizing leaked benchmarks. Our proof-of-concept experiments demonstrate that ITD reduces inflated accuracy by 22.9% on GSM8K and 19.0% on MMLU. On MMLU, using Inference-time Decontamination can lead to a decrease in the results of Phi3 and Mistral by 6.7% and 3.6% respectively. We hope that ITD can provide more truthful evaluation results for large language models.
Unified Active Retrieval for Retrieval Augmented Generation
Jun 18, 2024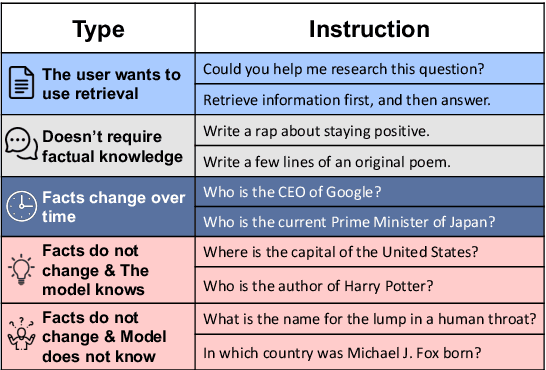

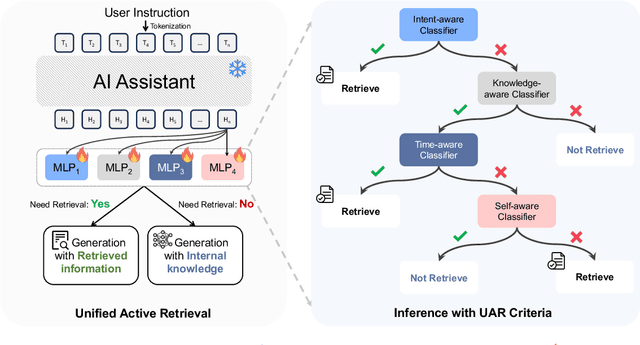
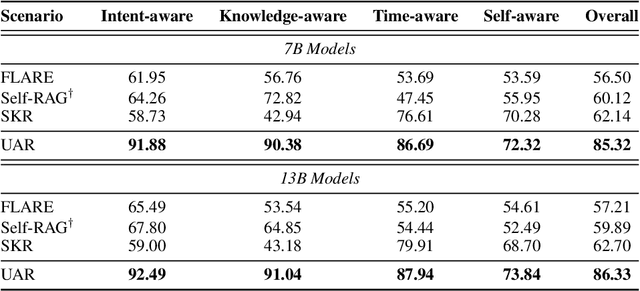
In Retrieval-Augmented Generation (RAG), retrieval is not always helpful and applying it to every instruction is sub-optimal. Therefore, determining whether to retrieve is crucial for RAG, which is usually referred to as Active Retrieval. However, existing active retrieval methods face two challenges: 1. They usually rely on a single criterion, which struggles with handling various types of instructions. 2. They depend on specialized and highly differentiated procedures, and thus combining them makes the RAG system more complicated and leads to higher response latency. To address these challenges, we propose Unified Active Retrieval (UAR). UAR contains four orthogonal criteria and casts them into plug-and-play classification tasks, which achieves multifaceted retrieval timing judgements with negligible extra inference cost. We further introduce the Unified Active Retrieval Criteria (UAR-Criteria), designed to process diverse active retrieval scenarios through a standardized procedure. Experiments on four representative types of user instructions show that UAR significantly outperforms existing work on the retrieval timing judgement and the performance of downstream tasks, which shows the effectiveness of UAR and its helpfulness to downstream tasks.
A webcam-based machine learning approach for three-dimensional range of motion evaluation
Oct 11, 2023Background. Joint range of motion (ROM) is an important quantitative measure for physical therapy. Commonly relying on a goniometer, accurate and reliable ROM measurement requires extensive training and practice. This, in turn, imposes a significant barrier for those who have limited in-person access to healthcare. Objective. The current study presents and evaluates an alternative machine learning-based ROM evaluation method that could be remotely accessed via a webcam. Methods. To evaluate its reliability, the ROM measurements for a diverse set of joints (neck, spine, and upper and lower extremities) derived using this method were compared to those obtained from a marker-based optical motion capture system. Results. Data collected from 25 healthy adults demonstrated that the webcam solution exhibited high test-retest reliability, with substantial to almost perfect intraclass correlation coefficients for most joints. Compared with the marker-based system, the webcam-based system demonstrated substantial to almost perfect inter-rater reliability for some joints, and lower inter-rater reliability for other joints (e.g., shoulder flexion and elbow flexion), which could be attributed to the reduced sensitivity to joint locations at the apex of the movement. Conclusions. The proposed webcam-based method exhibited high test-retest and inter-rater reliability, making it a versatile alternative for existing ROM evaluation methods in clinical practice and the tele-implementation of physical therapy and rehabilitation.
Multi-Task Pre-Training of Modular Prompt for Few-Shot Learning
Oct 14, 2022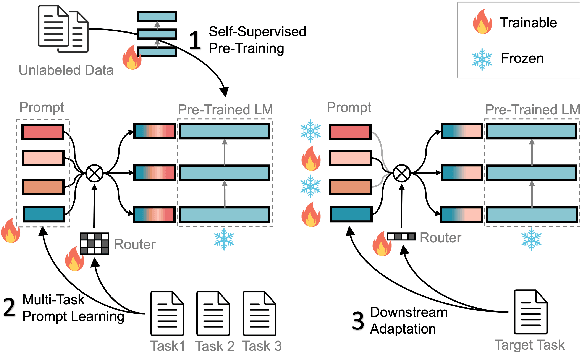
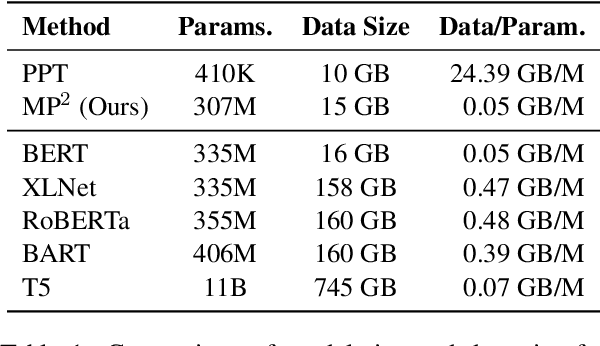
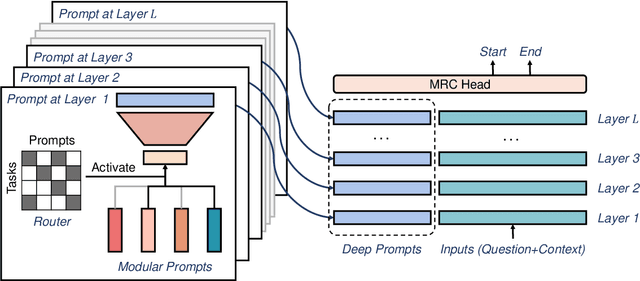
Prompt tuning is a parameter-efficient approach to adapting pre-trained language models to downstream tasks. Although prompt tuning has been shown to match the performance of full model tuning when training data is sufficient, it tends to struggle in few-shot learning settings. In this paper, we present Multi-task Pre-trained Modular Prompt (MP2) to boost prompt tuning for few-shot learning. MP2 is a set of combinable prompts pre-trained on 38 Chinese tasks. On downstream tasks, the pre-trained prompts are selectively activated and combined, leading to strong compositional generalization to unseen tasks. To bridge the gap between pre-training and fine-tuning, we formulate upstream and downstream tasks into a unified machine reading comprehension task. Extensive experiments under two learning paradigms, i.e., gradient descent and black-box tuning, show that MP2 significantly outperforms prompt tuning, full model tuning, and prior prompt pre-training methods in few-shot settings. In addition, we demonstrate that MP2 can achieve surprisingly fast and strong adaptation to downstream tasks by merely learning 8 parameters to combine the pre-trained modular prompts.
COLO: A Contrastive Learning based Re-ranking Framework for One-Stage Summarization
Sep 29, 2022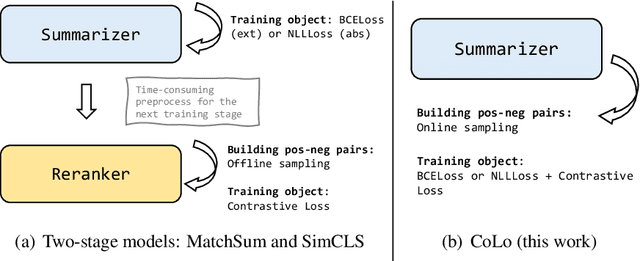

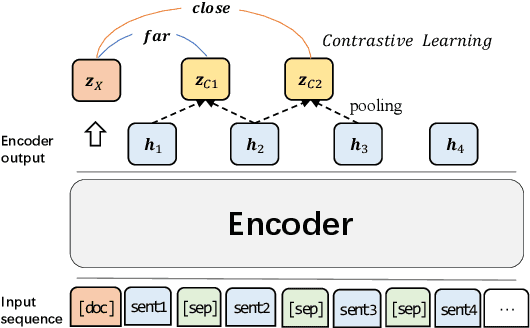
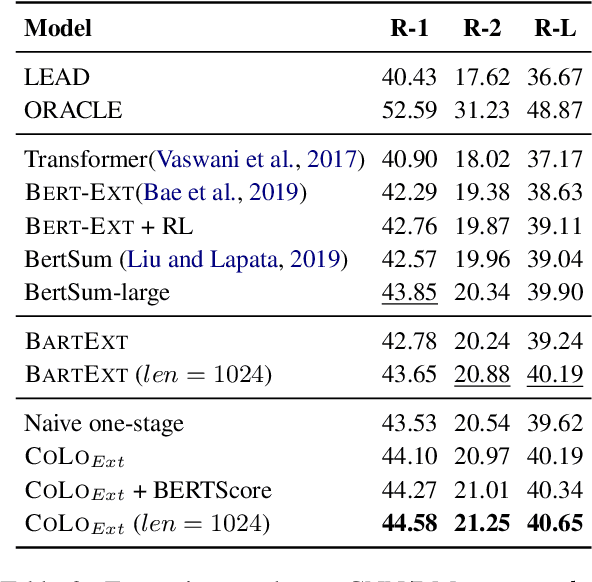
Traditional training paradigms for extractive and abstractive summarization systems always only use token-level or sentence-level training objectives. However, the output summary is always evaluated from summary-level which leads to the inconsistency in training and evaluation. In this paper, we propose a Contrastive Learning based re-ranking framework for one-stage summarization called COLO. By modeling a contrastive objective, we show that the summarization model is able to directly generate summaries according to the summary-level score without additional modules and parameters. Extensive experiments demonstrate that COLO boosts the extractive and abstractive results of one-stage systems on CNN/DailyMail benchmark to 44.58 and 46.33 ROUGE-1 score while preserving the parameter efficiency and inference efficiency. Compared with state-of-the-art multi-stage systems, we save more than 100 GPU training hours and obtaining 3~8 speed-up ratio during inference while maintaining comparable results.