 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnitCoder: Scalable Iterative Code Synthesis with Unit Test Guidance
Feb 17, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in various tasks, yet code generation remains a major challenge. Current approaches for obtaining high-quality code data primarily focus on (i) collecting large-scale pre-training data and (ii) synthesizing instruction data through prompt engineering with powerful models. While pre-training data faces quality consistency issues, instruction-based synthesis suffers from limited instruction diversity and inherent biases of LLMs. To address this gap, we introduce UnitCoder, a systematic pipeline leveraging model-generated unit tests to both guide and validate the code generation process. Combined with large-scale package-based retrieval from pre-training corpus, we generate a dataset of 500K+ verifiable programs containing diverse API calls. Evaluations on multiple Python benchmarks (BigCodeBench, HumanEval, MBPP) demonstrate that models fine-tuned on our synthetic data exhibit consistent performance improvements. Notably, Llama3.1-8B and InternLM2.5-7B improve from 31\% and 28\% to 40\% and 39\% success rates on BigCodeBench, respectively. Our work presents a scalable approach that leverages model-generated unit tests to guide the synthesis of high-quality code data from pre-training corpora, demonstrating the potential for producing diverse and high-quality post-training data at scale. All code and data will be released (https://github.com).
FastMCTS: A Simple Sampling Strategy for Data Synthesis
Feb 17, 2025



Synthetic high-quality multi-step reasoning data can significantly enhance the performance of large language models on various tasks. However, most existing methods rely on rejection sampling, which generates trajectories independently and suffers from inefficiency and imbalanced sampling across problems of varying difficulty. In this work, we introduce FastMCTS, an innovative data synthesis strategy inspired by Monte Carlo Tree Search. FastMCTS provides a more efficient sampling method for multi-step reasoning data, offering step-level evaluation signals and promoting balanced sampling across problems of different difficulty levels. Experiments on both English and Chinese reasoning datasets demonstrate that FastMCTS generates over 30\% more correct reasoning paths compared to rejection sampling as the number of generated tokens scales up. Furthermore, under comparable synthetic data budgets, models trained on FastMCTS-generated data outperform those trained on rejection sampling data by 3.9\% across multiple benchmarks. As a lightweight sampling strategy, FastMCTS offers a practical and efficient alternative for synthesizing high-quality reasoning data. Our code will be released soon.
GAOKAO-Eval: Does high scores truly reflect strong capabilities in LLMs?
Dec 13, 2024Large Language Models (LLMs) are commonly evaluated using human-crafted benchmarks, under the premise that higher scores implicitly reflect stronger human-like performance. However, there is growing concern that LLMs may ``game" these benchmarks due to data leakage, achieving high scores while struggling with tasks simple for humans. To substantively address the problem, we create GAOKAO-Eval, a comprehensive benchmark based on China's National College Entrance Examination (Gaokao), and conduct ``closed-book" evaluations for representative models released prior to Gaokao. Contrary to prevailing consensus, even after addressing data leakage and comprehensiveness, GAOKAO-Eval reveals that high scores still fail to truly reflect human-aligned capabilities. To better understand this mismatch, We introduce the Rasch model from cognitive psychology to analyze LLM scoring patterns and identify two key discrepancies: 1) anomalous consistent performance across various question difficulties, and 2) high variance in performance on questions of similar difficulty. In addition, We identified inconsistent grading of LLM-generated answers among teachers and recurring mistake patterns. we find that the phenomenons are well-grounded in the motivations behind OpenAI o1, and o1's reasoning-as-difficulties can mitigate the mismatch. These results show that GAOKAO-Eval can reveal limitations in LLM capabilities not captured by current benchmarks and highlight the need for more LLM-aligned difficulty analysis.
Case2Code: Learning Inductive Reasoning with Synthetic Data
Jul 17, 2024



Complex reasoning is an impressive ability shown by large language models (LLMs). Most LLMs are skilled in deductive reasoning, such as chain-of-thought prompting or iterative tool-using to solve challenging tasks step-by-step. In this paper, we hope to focus on evaluating and teaching LLMs to conduct inductive reasoning, that is, LLMs are supposed to infer underlying rules by observing examples or sequential transformations. However, collecting large-scale and diverse human-generated inductive data is challenging. We focus on data synthesis in the code domain and propose a \textbf{Case2Code} task by exploiting the expressiveness and correctness of programs. Specifically, we collect a diverse set of executable programs, synthesize input-output transformations for each program, and force LLMs to infer the underlying code implementations based on the synthetic I/O cases. We first evaluate representative LLMs on the synthesized Case2Code task and demonstrate that the Case-to-code induction is challenging for LLMs. Then, we synthesize large-scale Case2Code training samples to train LLMs to perform inductive reasoning. Experimental results show that such induction training benefits not only in distribution Case2Code performance but also enhances various coding abilities of trained LLMs, demonstrating the great potential of learning inductive reasoning via synthetic data.
Unified Active Retrieval for Retrieval Augmented Generation
Jun 18, 2024

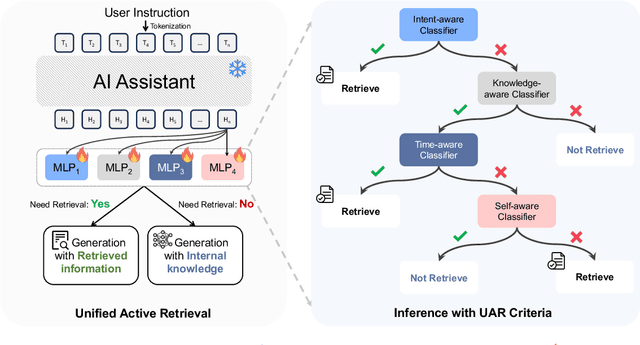
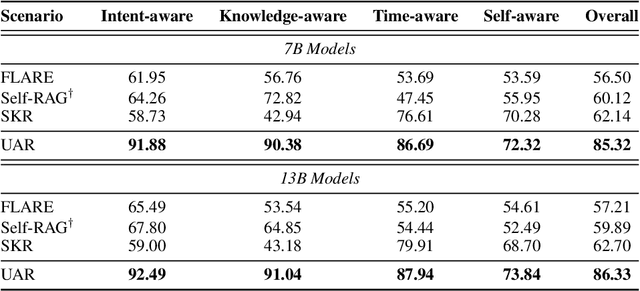
In Retrieval-Augmented Generation (RAG), retrieval is not always helpful and applying it to every instruction is sub-optimal. Therefore, determining whether to retrieve is crucial for RAG, which is usually referred to as Active Retrieval. However, existing active retrieval methods face two challenges: 1. They usually rely on a single criterion, which struggles with handling various types of instructions. 2. They depend on specialized and highly differentiated procedures, and thus combining them makes the RAG system more complicated and leads to higher response latency. To address these challenges, we propose Unified Active Retrieval (UAR). UAR contains four orthogonal criteria and casts them into plug-and-play classification tasks, which achieves multifaceted retrieval timing judgements with negligible extra inference cost. We further introduce the Unified Active Retrieval Criteria (UAR-Criteria), designed to process diverse active retrieval scenarios through a standardized procedure. Experiments on four representative types of user instructions show that UAR significantly outperforms existing work on the retrieval timing judgement and the performance of downstream tasks, which shows the effectiveness of UAR and its helpfulness to downstream tasks.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
Balanced Data Sampling for Language Model Training with Clustering
Feb 22, 2024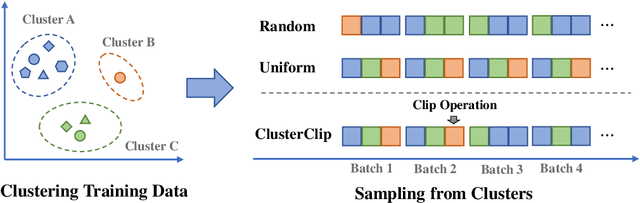
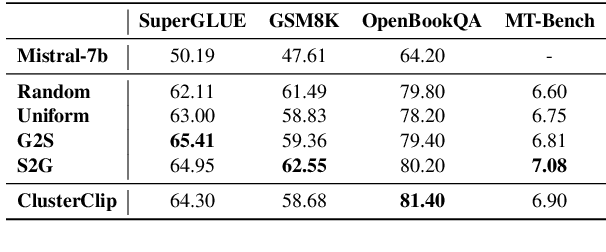
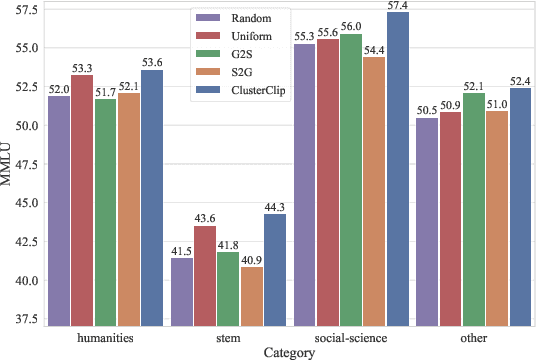
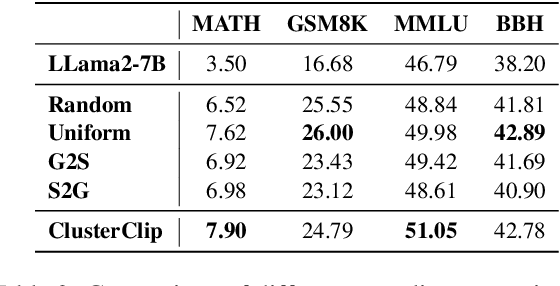
Data plays a fundamental role in the training of Large Language Models (LLMs). While attention has been paid to the collection and composition of datasets, determining the data sampling strategy in training remains an open question. Most LLMs are trained with a simple strategy, random sampling. However, this sampling strategy ignores the unbalanced nature of training data distribution, which can be sub-optimal. In this paper, we propose ClusterClip Sampling to balance the text distribution of training data for better model training. Specifically, ClusterClip Sampling utilizes data clustering to reflect the data distribution of the training set and balances the common samples and rare samples during training based on the cluster results. A repetition clip operation is introduced to mitigate the overfitting issue led by samples from certain clusters. Extensive experiments validate the effectiveness of ClusterClip Sampling, which outperforms random sampling and other cluster-based sampling variants under various training datasets and large language models.
InternLM-Math: Open Math Large Language Models Toward Verifiable Reasoning
Feb 09, 2024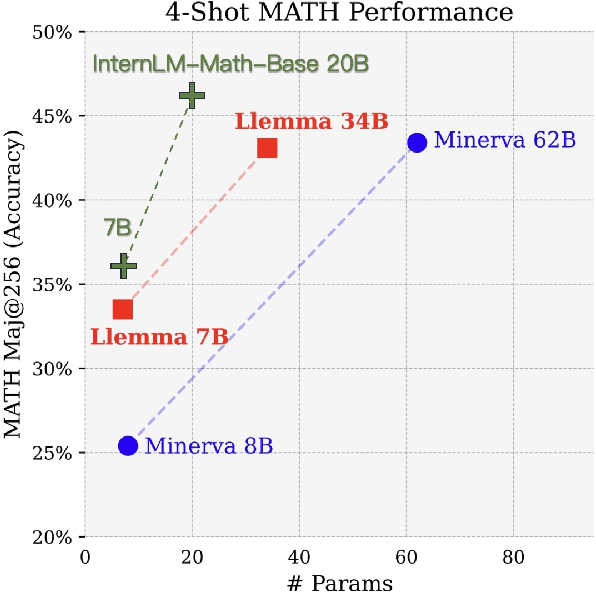
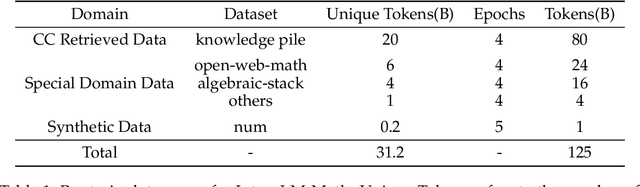
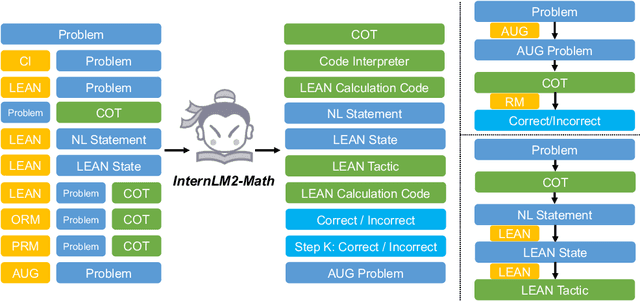
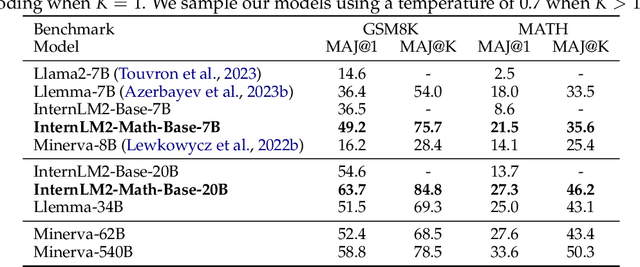
The math abilities of large language models can represent their abstract reasoning ability. In this paper, we introduce and open-source our math reasoning LLMs InternLM-Math which is continue pre-trained from InternLM2. We unify chain-of-thought reasoning, reward modeling, formal reasoning, data augmentation, and code interpreter in a unified seq2seq format and supervise our model to be a versatile math reasoner, verifier, prover, and augmenter. These abilities can be used to develop the next math LLMs or self-iteration. InternLM-Math obtains open-sourced state-of-the-art performance under the setting of in-context learning, supervised fine-tuning, and code-assisted reasoning in various informal and formal benchmarks including GSM8K, MATH, Hungary math exam, MathBench-ZH, and MiniF2F. Our pre-trained model achieves 30.3 on the MiniF2F test set without fine-tuning. We further explore how to use LEAN to solve math problems and study its performance under the setting of multi-task learning which shows the possibility of using LEAN as a unified platform for solving and proving in math. Our models, codes, and data are released at \url{https://github.com/InternLM/InternLM-Math}.
Query of CC: Unearthing Large Scale Domain-Specific Knowledge from Public Corpora
Jan 26, 2024

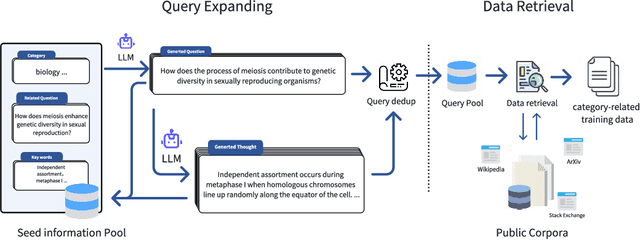

Large language models have demonstrated remarkable potential in various tasks, however, there remains a significant scarcity of open-source models and data for specific domains. Previous works have primarily focused on manually specifying resources and collecting high-quality data on specific domains, which significantly consume time and effort. To address this limitation, we propose an efficient data collection method~\textit{Query of CC} based on large language models. This method bootstraps seed information through a large language model and retrieves related data from public corpora. It not only collects knowledge-related data for specific domains but unearths the data with potential reasoning procedures. Through the application of this method, we have curated a high-quality dataset called~\textsc{Knowledge Pile}, encompassing four major domains, including stem and humanities sciences, among others. Experimental results demonstrate that~\textsc{Knowledge Pile} significantly improves the performance of large language models in mathematical and knowledge-related reasoning ability tests. To facilitate academic sharing, we open-source our dataset and code, providing valuable support to the academic community.
Character-LLM: A Trainable Agent for Role-Playing
Oct 16, 2023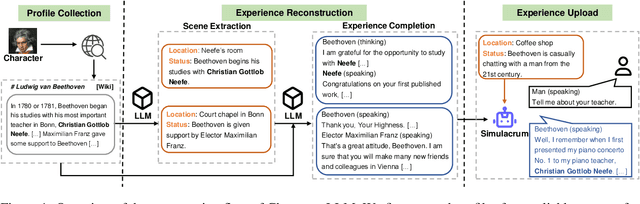



Large language models (LLMs) can be used to serve as agents to simulate human behaviors, given the powerful ability to understand human instructions and provide high-quality generated texts. Such ability stimulates us to wonder whether LLMs can simulate a person in a higher form than simple human behaviors. Therefore, we aim to train an agent with the profile, experience, and emotional states of a specific person instead of using limited prompts to instruct ChatGPT API. In this work, we introduce Character-LLM that teach LLMs to act as specific people such as Beethoven, Queen Cleopatra, Julius Caesar, etc. Our method focuses on editing profiles as experiences of a certain character and training models to be personal simulacra with these experiences. To assess the effectiveness of our approach, we build a test playground that interviews trained agents and evaluates whether the agents \textit{memorize} their characters and experiences. Experimental results show interesting observations that help build future simulacra of humankind.