 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePackMamba: Efficient Processing of Variable-Length Sequences in Mamba training
Aug 07, 2024



With the evolution of large language models, traditional Transformer models become computationally demanding for lengthy sequences due to the quadratic growth in computation with respect to the sequence length. Mamba, emerging as a groundbreaking architecture in the field of generative AI, demonstrates remarkable proficiency in handling elongated sequences with reduced computational and memory complexity. Nevertheless, the existing training framework of Mamba presents inefficiency with variable-length sequence inputs. Either single-sequence training results in low GPU utilization, or batched processing of variable-length sequences to a maximum length incurs considerable memory and computational overhead. To address this problem, we analyze the performance of bottleneck operators in Mamba under diverse tensor shapes and proposed PackMamba, a high-throughput Mamba that efficiently handles variable-length sequences. Diving deep into state-space models (SSMs), we modify the parallel operators to avoid passing information between individual sequences while maintaining high performance. Experimental results on an NVIDIA A100 GPU demonstrate throughput exceeding the baseline single-sequence processing scheme: 3.06x speedup on the 1.4B model and 2.62x on the 2.8B model.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
Seller-Side Experiments under Interference Induced by Feedback Loops in Two-Sided Platforms
Jan 29, 2024Two-sided platforms are central to modern commerce and content sharing and often utilize A/B testing for developing new features. While user-side experiments are common, seller-side experiments become crucial for specific interventions and metrics. This paper investigates the effects of interference caused by feedback loops on seller-side experiments in two-sided platforms, with a particular focus on the counterfactual interleaving design, proposed in \citet{ha2020counterfactual,nandy2021b}. These feedback loops, often generated by pacing algorithms, cause outcomes from earlier sessions to influence subsequent ones. This paper contributes by creating a mathematical framework to analyze this interference, theoretically estimating its impact, and conducting empirical evaluations of the counterfactual interleaving design in real-world scenarios. Our research shows that feedback loops can result in misleading conclusions about the treatment effects.
Near-Optimal Experimental Design Under the Budget Constraint in Online Platforms
Feb 10, 2023A/B testing, or controlled experiments, is the gold standard approach to causally compare the performance of algorithms on online platforms. However, conventional Bernoulli randomization in A/B testing faces many challenges such as spillover and carryover effects. Our study focuses on another challenge, especially for A/B testing on two-sided platforms -- budget constraints. Buyers on two-sided platforms often have limited budgets, where the conventional A/B testing may be infeasible to be applied, partly because two variants of allocation algorithms may conflict and lead some buyers to exceed their budgets if they are implemented simultaneously. We develop a model to describe two-sided platforms where buyers have limited budgets. We then provide an optimal experimental design that guarantees small bias and minimum variance. Bias is lower when there is more budget and a higher supply-demand rate. We test our experimental design on both synthetic data and real-world data, which verifies the theoretical results and shows our advantage compared to Bernoulli randomization.
Dynamic Budget Throttling in Repeated Second-Price Auctions
Jul 15, 2022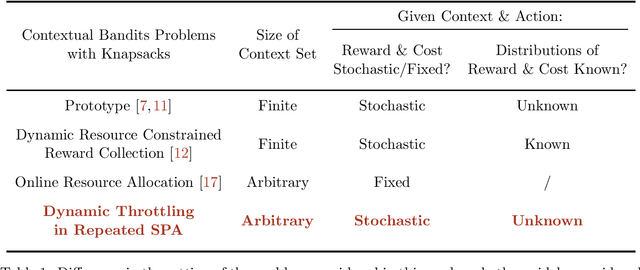
Throttling is one of the most popular budget control methods in today's online advertising markets. When a budget-constrained advertiser employs throttling, she can choose whether or not to participate in an auction after the advertising platform recommends a bid. This paper focuses on the dynamic budget throttling process in repeated second-price auctions from a theoretical view. An essential feature of the underlying problem is that the advertiser does not know the distribution of the highest competing bid upon entering the market. To model the difficulty of eliminating such uncertainty, we consider two different information structures. The advertiser could obtain the highest competing bid in each round with full-information feedback. Meanwhile, with partial information feedback, the advertiser could only have access to the highest competing bid in the auctions she participates in. We propose the OGD-CB algorithm, which involves simultaneous distribution learning and revenue optimization. In both settings, we demonstrate that this algorithm guarantees an $O(\sqrt{T\log T})$ regret with probability $1 - O(1/T)$ relative to the fluid adaptive throttling benchmark. By proving a lower bound of $\Omega(\sqrt{T})$ on the minimal regret for even the hindsight optimum, we establish the near optimality of our algorithm. Finally, we compare the fluid optimum of throttling to that of pacing, another widely adopted budget control method. The numerical relationship of these benchmarks sheds new light on the understanding of different online algorithms for revenue maximization under budget constraints.
Towards Near-imperceptible Steganographic Text
Jul 29, 2019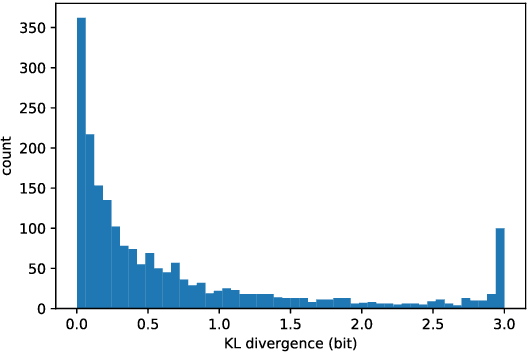
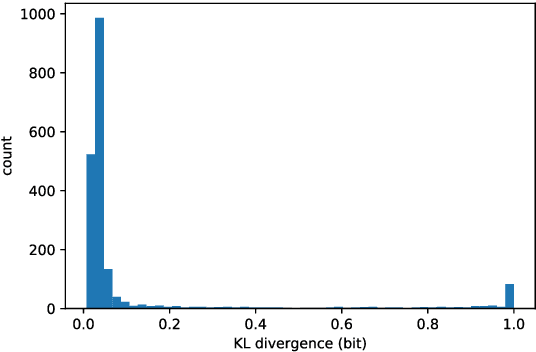
We show that the imperceptibility of several existing linguistic steganographic systems (Fang et al., 2017; Yang et al., 2018) relies on implicit assumptions on statistical behaviors of fluent text. We formally analyze them and empirically evaluate these assumptions. Furthermore, based on these observations, we propose an encoding algorithm called patient-Huffman with improved near-imperceptible guarantees.
Video (GIF) Sentiment Analysis using Large-Scale Mid-Level Ontology
Jun 02, 2015
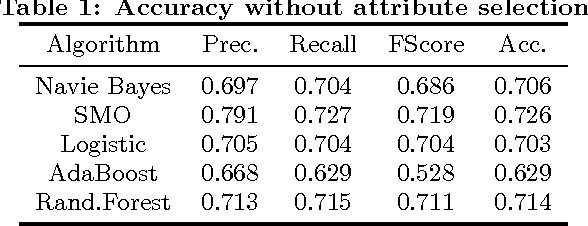
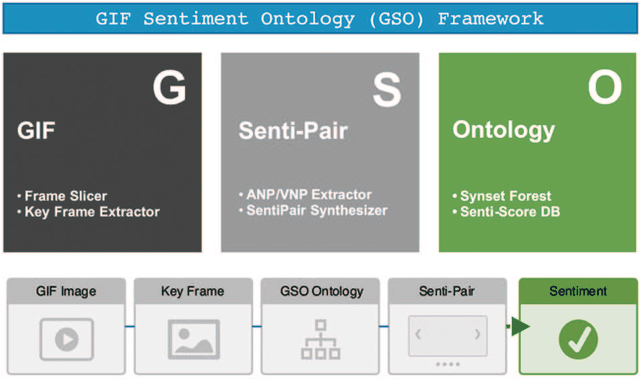
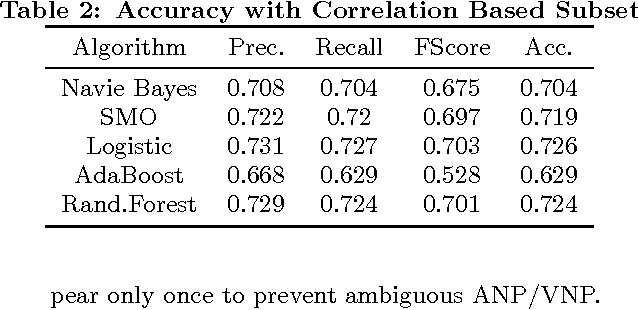
With faster connection speed, Internet users are now making social network a huge reservoir of texts, images and video clips (GIF). Sentiment analysis for such online platform can be used to predict political elections, evaluates economic indicators and so on. However, GIF sentiment analysis is quite challenging, not only because it hinges on spatio-temporal visual contentabstraction, but also for the relationship between such abstraction and final sentiment remains unknown.In this paper, we dedicated to find out such relationship.We proposed a SentiPairSequence basedspatiotemporal visual sentiment ontology, which forms the midlevel representations for GIFsentiment. The establishment process of SentiPair contains two steps. First, we construct the Synset Forest to define the semantic tree structure of visual sentiment label elements. Then, through theSynset Forest, we organically select and combine sentiment label elements to form a mid-level visual sentiment representation. Our experiments indicate that SentiPair outperforms other competing mid-level attributes. Using SentiPair, our analysis frameworkcan achieve satisfying prediction accuracy (72.6%). We also opened ourdataset (GSO-2015) to the research community. GSO-2015 contains more than 6,000 manually annotated GIFs out of more than 40,000 candidates. Each is labeled with both sentiment and SentiPair Sequence.