 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modality Earth Mover's Distance for Visible Thermal Person Re-Identification
Mar 03, 2022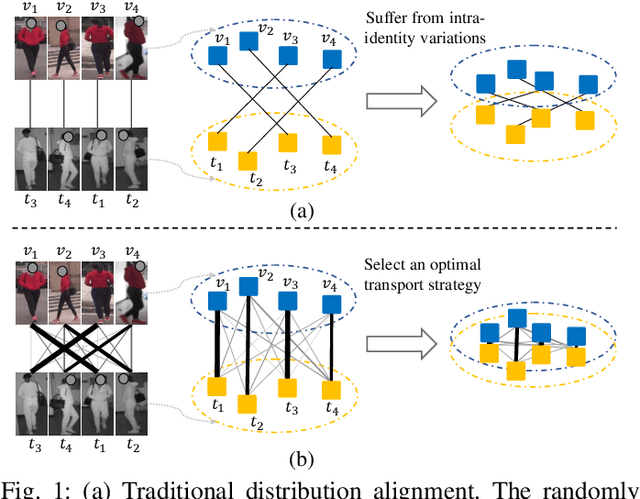
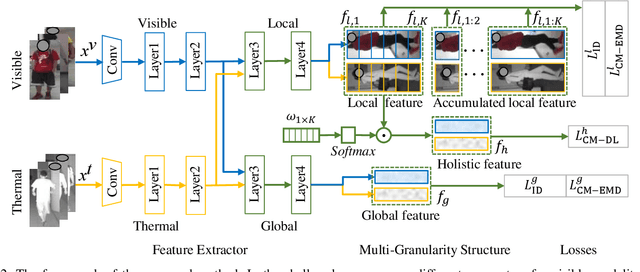
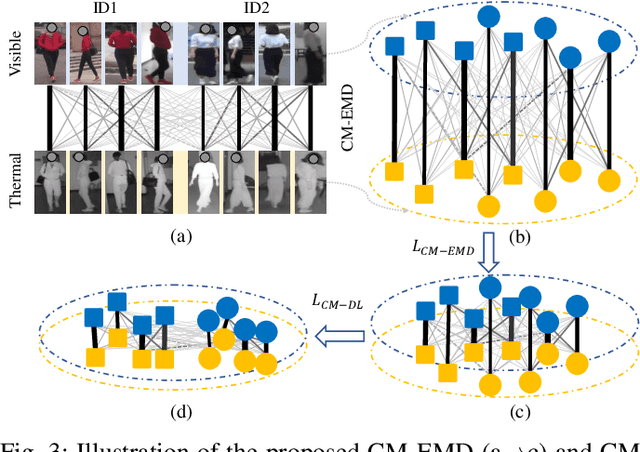

Visible thermal person re-identification (VT-ReID) suffers from the inter-modality discrepancy and intra-identity variations. Distribution alignment is a popular solution for VT-ReID, which, however, is usually restricted to the influence of the intra-identity variations. In this paper, we propose the Cross-Modality Earth Mover's Distance (CM-EMD) that can alleviate the impact of the intra-identity variations during modality alignment. CM-EMD selects an optimal transport strategy and assigns high weights to pairs that have a smaller intra-identity variation. In this manner, the model will focus on reducing the inter-modality discrepancy while paying less attention to intra-identity variations, leading to a more effective modality alignment. Moreover, we introduce two techniques to improve the advantage of CM-EMD. First, the Cross-Modality Discrimination Learning (CM-DL) is designed to overcome the discrimination degradation problem caused by modality alignment. By reducing the ratio between intra-identity and inter-identity variances, CM-DL leads the model to learn more discriminative representations. Second, we construct the Multi-Granularity Structure (MGS), enabling us to align modalities from both coarse- and fine-grained levels with the proposed CM-EMD. Extensive experiments show the benefits of the proposed CM-EMD and its auxiliary techniques (CM-DL and MGS). Our method achieves state-of-the-art performance on two VT-ReID benchmarks.
Solving Large-Scale Multi-Objective Optimization via Probabilistic Prediction Model
Jul 16, 2021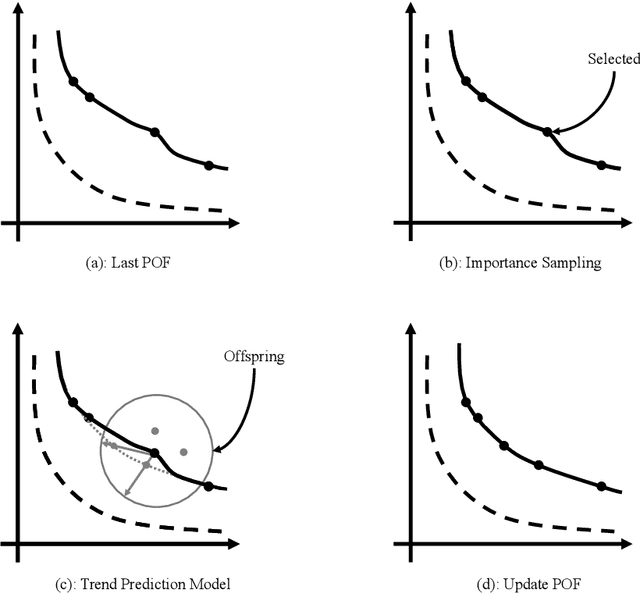
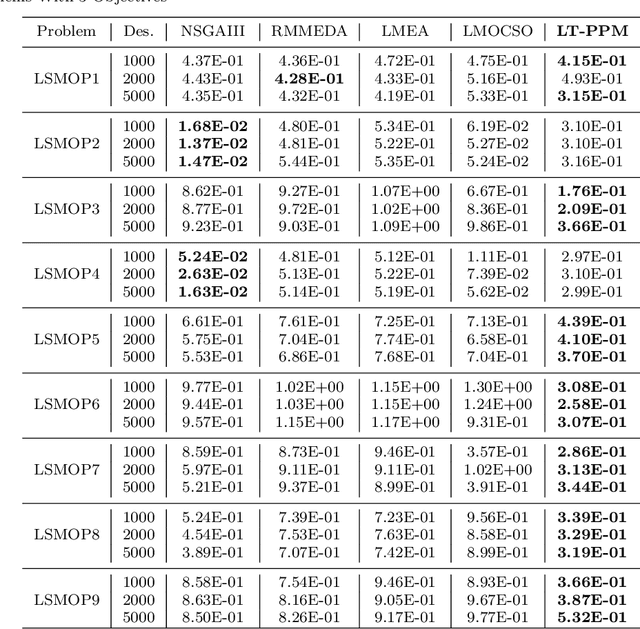
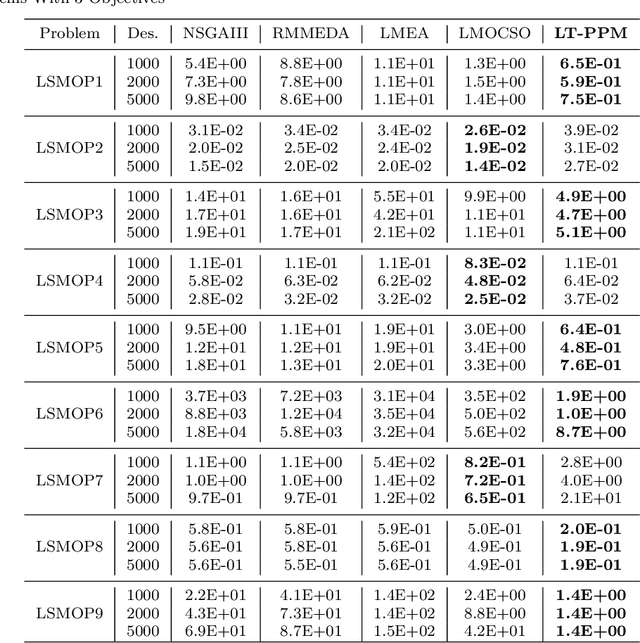
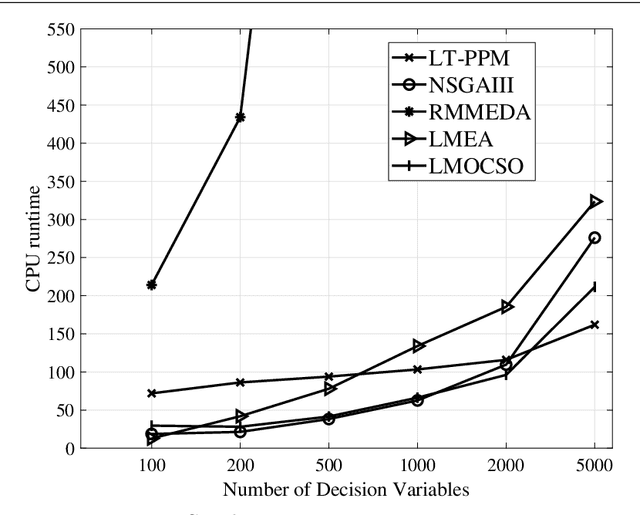
The main feature of large-scale multi-objective optimization problems (LSMOP) is to optimize multiple conflicting objectives while considering thousands of decision variables at the same time. An efficient LSMOP algorithm should have the ability to escape the local optimal solution from the huge search space and find the global optimal. Most of the current researches focus on how to deal with decision variables. However, due to the large number of decision variables, it is easy to lead to high computational cost. Maintaining the diversity of the population is one of the effective ways to improve search efficiency. In this paper, we propose a probabilistic prediction model based on trend prediction model and generating-filtering strategy, called LT-PPM, to tackle the LSMOP. The proposed method enhances the diversity of the population through importance sampling. At the same time, due to the adoption of an individual-based evolution mechanism, the computational cost of the proposed method is independent of the number of decision variables, thus avoiding the problem of exponential growth of the search space. We compared the proposed algorithm with several state-of-the-art algorithms for different benchmark functions. The experimental results and complexity analysis have demonstrated that the proposed algorithm has significant improvement in terms of its performance and computational efficiency in large-scale multi-objective optimization.
Re-ranking Person Re-identification with k-reciprocal Encoding
May 05, 2017


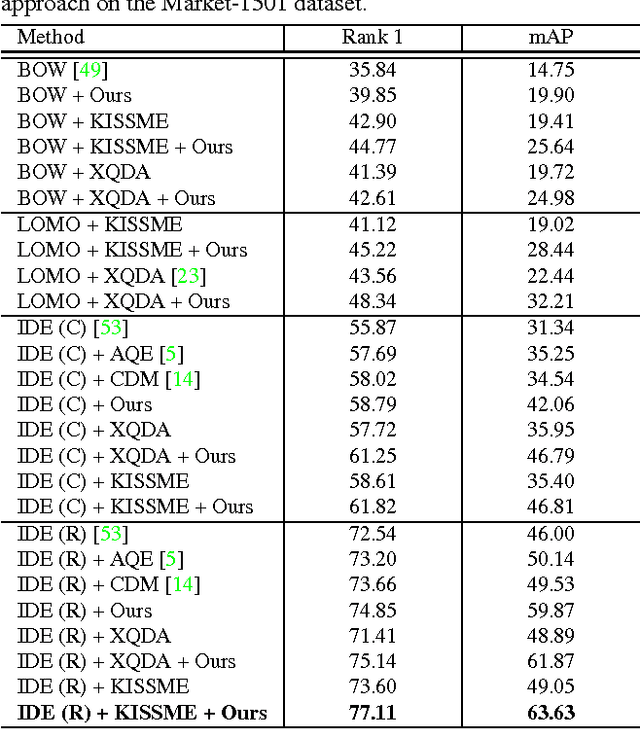
When considering person re-identification (re-ID) as a retrieval process, re-ranking is a critical step to improve its accuracy. Yet in the re-ID community, limited effort has been devoted to re-ranking, especially those fully automatic, unsupervised solutions. In this paper, we propose a k-reciprocal encoding method to re-rank the re-ID results. Our hypothesis is that if a gallery image is similar to the probe in the k-reciprocal nearest neighbors, it is more likely to be a true match. Specifically, given an image, a k-reciprocal feature is calculated by encoding its k-reciprocal nearest neighbors into a single vector, which is used for re-ranking under the Jaccard distance. The final distance is computed as the combination of the original distance and the Jaccard distance. Our re-ranking method does not require any human interaction or any labeled data, so it is applicable to large-scale datasets. Experiments on the large-scale Market-1501, CUHK03, MARS, and PRW datasets confirm the effectiveness of our method.
Detecting Ground Control Points via Convolutional Neural Network for Stereo Matching
May 08, 2016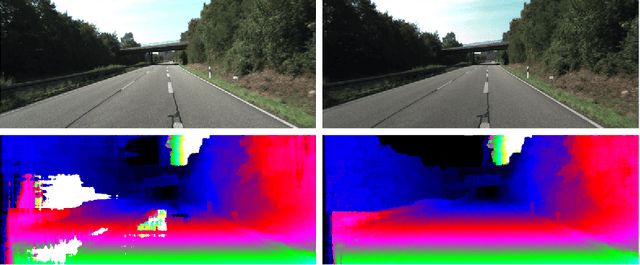

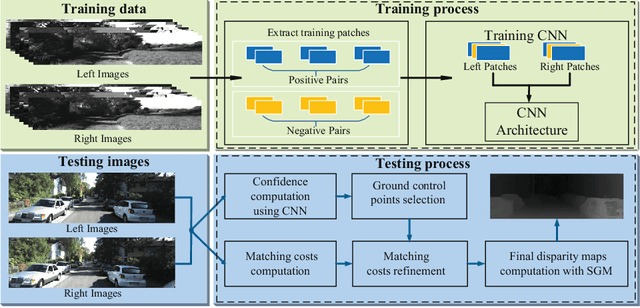

In this paper, we present a novel approach to detect ground control points (GCPs) for stereo matching problem. First of all, we train a convolutional neural network (CNN) on a large stereo set, and compute the matching confidence of each pixel by using the trained CNN model. Secondly, we present a ground control points selection scheme according to the maximum matching confidence of each pixel. Finally, the selected GCPs are used to refine the matching costs, and we apply the new matching costs to perform optimization with semi-global matching algorithm for improving the final disparity maps. We evaluate our approach on the KITTI 2012 stereo benchmark dataset. Our experiments show that the proposed approach significantly improves the accuracy of disparity maps.
Video (GIF) Sentiment Analysis using Large-Scale Mid-Level Ontology
Jun 02, 2015
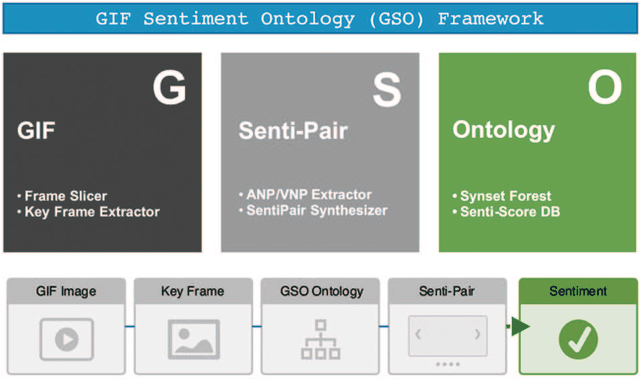
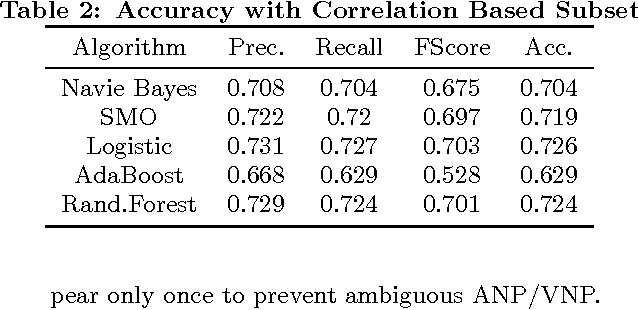
With faster connection speed, Internet users are now making social network a huge reservoir of texts, images and video clips (GIF). Sentiment analysis for such online platform can be used to predict political elections, evaluates economic indicators and so on. However, GIF sentiment analysis is quite challenging, not only because it hinges on spatio-temporal visual contentabstraction, but also for the relationship between such abstraction and final sentiment remains unknown.In this paper, we dedicated to find out such relationship.We proposed a SentiPairSequence basedspatiotemporal visual sentiment ontology, which forms the midlevel representations for GIFsentiment. The establishment process of SentiPair contains two steps. First, we construct the Synset Forest to define the semantic tree structure of visual sentiment label elements. Then, through theSynset Forest, we organically select and combine sentiment label elements to form a mid-level visual sentiment representation. Our experiments indicate that SentiPair outperforms other competing mid-level attributes. Using SentiPair, our analysis frameworkcan achieve satisfying prediction accuracy (72.6%). We also opened ourdataset (GSO-2015) to the research community. GSO-2015 contains more than 6,000 manually annotated GIFs out of more than 40,000 candidates. Each is labeled with both sentiment and SentiPair Sequence.