 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Causal Alignment for High-Confidence Adversarial Training
Jun 02, 2026Inverse adversarial training leverages high-confidence predictions to stabilize robust learning, yet we uncover a critical paradox: high confidence often stems from overfitting to non-causal background correlations rather than intrinsic object semantics. Our investigation reveals that visual context functions as a dual-natured signal, serving as either a necessary supportive prior or a spurious confounder. This insight renders existing blind suppression strategies flawed, as they inevitably lead to severe Feature Loss. To resolve this, we propose High-Confidence Causally Aligned Training (HICAT), a unified framework that establishes a Semantic Equilibrium. Operating on a ``Measure-Debias-Align'' pipeline, HICAT integrates a Learnable Background-Bias Estimator (LBBE) to adaptively diagnose context utility. Guided by this diagnosis, an Adaptive Debiasing mechanism performs surgical logit rectification, complemented by a geometrically grounded Foreground Logit Orthogonal Enhancement (FLOE) loss to enforce rigorous feature disentanglement. Extensive experiments on CIFAR-10, CIFAR-100, and ImageNet-1K demonstrate that HICAT consistently improves over matched baselines across diverse architectures (CNNs and ViTs) while significantly reducing the robust generalization gap.
HCCM: Hierarchical Cross-Granularity Contrastive and Matching Learning for Natural Language-Guided Drones
Aug 29, 2025Natural Language-Guided Drones (NLGD) provide a novel paradigm for tasks such as target matching and navigation. However, the wide field of view and complex compositional semantics in drone scenarios pose challenges for vision-language understanding. Mainstream Vision-Language Models (VLMs) emphasize global alignment while lacking fine-grained semantics, and existing hierarchical methods depend on precise entity partitioning and strict containment, limiting effectiveness in dynamic environments. To address this, we propose the Hierarchical Cross-Granularity Contrastive and Matching learning (HCCM) framework with two components: (1) Region-Global Image-Text Contrastive Learning (RG-ITC), which avoids precise scene partitioning and captures hierarchical local-to-global semantics by contrasting local visual regions with global text and vice versa; (2) Region-Global Image-Text Matching (RG-ITM), which dispenses with rigid constraints and instead evaluates local semantic consistency within global cross-modal representations, enhancing compositional reasoning. Moreover, drone text descriptions are often incomplete or ambiguous, destabilizing alignment. HCCM introduces a Momentum Contrast and Distillation (MCD) mechanism to improve robustness. Experiments on GeoText-1652 show HCCM achieves state-of-the-art Recall@1 of 28.8% (image retrieval) and 14.7% (text retrieval). On the unseen ERA dataset, HCCM demonstrates strong zero-shot generalization with 39.93% mean recall (mR), outperforming fine-tuned baselines.
Weakly Supervised Object Detection for Automatic Tooth-marked Tongue Recognition
Aug 29, 2024Tongue diagnosis in Traditional Chinese Medicine (TCM) is a crucial diagnostic method that can reflect an individual's health status. Traditional methods for identifying tooth-marked tongues are subjective and inconsistent because they rely on practitioner experience. We propose a novel fully automated Weakly Supervised method using Vision transformer and Multiple instance learning WSVM for tongue extraction and tooth-marked tongue recognition. Our approach first accurately detects and extracts the tongue region from clinical images, removing any irrelevant background information. Then, we implement an end-to-end weakly supervised object detection method. We utilize Vision Transformer (ViT) to process tongue images in patches and employ multiple instance loss to identify tooth-marked regions with only image-level annotations. WSVM achieves high accuracy in tooth-marked tongue classification, and visualization experiments demonstrate its effectiveness in pinpointing these regions. This automated approach enhances the objectivity and accuracy of tooth-marked tongue diagnosis. It provides significant clinical value by assisting TCM practitioners in making precise diagnoses and treatment recommendations. Code is available at https://github.com/yc-zh/WSVM.
Long-Tailed Out-of-Distribution Detection: Prioritizing Attention to Tail
Aug 13, 2024



Current out-of-distribution (OOD) detection methods typically assume balanced in-distribution (ID) data, while most real-world data follow a long-tailed distribution. Previous approaches to long-tailed OOD detection often involve balancing the ID data by reducing the semantics of head classes. However, this reduction can severely affect the classification accuracy of ID data. The main challenge of this task lies in the severe lack of features for tail classes, leading to confusion with OOD data. To tackle this issue, we introduce a novel Prioritizing Attention to Tail (PATT) method using augmentation instead of reduction. Our main intuition involves using a mixture of von Mises-Fisher (vMF) distributions to model the ID data and a temperature scaling module to boost the confidence of ID data. This enables us to generate infinite contrastive pairs, implicitly enhancing the semantics of ID classes while promoting differentiation between ID and OOD data. To further strengthen the detection of OOD data without compromising the classification performance of ID data, we propose feature calibration during the inference phase. By extracting an attention weight from the training set that prioritizes the tail classes and reduces the confidence in OOD data, we improve the OOD detection capability. Extensive experiments verified that our method outperforms the current state-of-the-art methods on various benchmarks.
Towards Adversarial Robustness via Debiased High-Confidence Logit Alignment
Aug 12, 2024



Despite the significant advances that deep neural networks (DNNs) have achieved in various visual tasks, they still exhibit vulnerability to adversarial examples, leading to serious security concerns. Recent adversarial training techniques have utilized inverse adversarial attacks to generate high-confidence examples, aiming to align the distributions of adversarial examples with the high-confidence regions of their corresponding classes. However, in this paper, our investigation reveals that high-confidence outputs under inverse adversarial attacks are correlated with biased feature activation. Specifically, training with inverse adversarial examples causes the model's attention to shift towards background features, introducing a spurious correlation bias. To address this bias, we propose Debiased High-Confidence Adversarial Training (DHAT), a novel approach that not only aligns the logits of adversarial examples with debiased high-confidence logits obtained from inverse adversarial examples, but also restores the model's attention to its normal state by enhancing foreground logit orthogonality. Extensive experiments demonstrate that DHAT achieves state-of-the-art performance and exhibits robust generalization capabilities across various vision datasets. Additionally, DHAT can seamlessly integrate with existing advanced adversarial training techniques for improving the performance.
Mitigating Low-Frequency Bias: Feature Recalibration and Frequency Attention Regularization for Adversarial Robustness
Jul 04, 2024


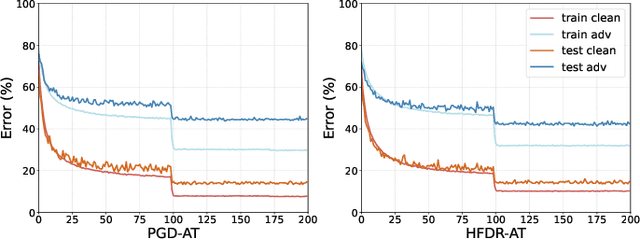
Ensuring the robustness of computer vision models against adversarial attacks is a significant and long-lasting objective. Motivated by adversarial attacks, researchers have devoted considerable efforts to enhancing model robustness by adversarial training (AT). However, we observe that while AT improves the models' robustness against adversarial perturbations, it fails to improve their ability to effectively extract features across all frequency components. Each frequency component contains distinct types of crucial information: low-frequency features provide fundamental structural insights, while high-frequency features capture intricate details and textures. In particular, AT tends to neglect the reliance on susceptible high-frequency features. This low-frequency bias impedes the model's ability to effectively leverage the potentially meaningful semantic information present in high-frequency features. This paper proposes a novel module called High-Frequency Feature Disentanglement and Recalibration (HFDR), which separates features into high-frequency and low-frequency components and recalibrates the high-frequency feature to capture latent useful semantics. Additionally, we introduce frequency attention regularization to magnitude the model's extraction of different frequency features and mitigate low-frequency bias during AT. Extensive experiments showcase the immense potential and superiority of our approach in resisting various white-box attacks, transfer attacks, and showcasing strong generalization capabilities.
Harmonizing Feature Maps: A Graph Convolutional Approach for Enhancing Adversarial Robustness
Jun 17, 2024



The vulnerability of Deep Neural Networks to adversarial perturbations presents significant security concerns, as the imperceptible perturbations can contaminate the feature space and lead to incorrect predictions. Recent studies have attempted to calibrate contaminated features by either suppressing or over-activating particular channels. Despite these efforts, we claim that adversarial attacks exhibit varying disruption levels across individual channels. Furthermore, we argue that harmonizing feature maps via graph and employing graph convolution can calibrate contaminated features. To this end, we introduce an innovative plug-and-play module called Feature Map-based Reconstructed Graph Convolution (FMR-GC). FMR-GC harmonizes feature maps in the channel dimension to reconstruct the graph, then employs graph convolution to capture neighborhood information, effectively calibrating contaminated features. Extensive experiments have demonstrated the superior performance and scalability of FMR-GC. Moreover, our model can be combined with advanced adversarial training methods to considerably enhance robustness without compromising the model's clean accuracy.
Improving Transferable Targeted Adversarial Attack via Normalized Logit Calibration and Truncated Feature Mixing
May 10, 2024This paper aims to enhance the transferability of adversarial samples in targeted attacks, where attack success rates remain comparatively low. To achieve this objective, we propose two distinct techniques for improving the targeted transferability from the loss and feature aspects. First, in previous approaches, logit calibrations used in targeted attacks primarily focus on the logit margin between the targeted class and the untargeted classes among samples, neglecting the standard deviation of the logit. In contrast, we introduce a new normalized logit calibration method that jointly considers the logit margin and the standard deviation of logits. This approach effectively calibrates the logits, enhancing the targeted transferability. Second, previous studies have demonstrated that mixing the features of clean samples during optimization can significantly increase transferability. Building upon this, we further investigate a truncated feature mixing method to reduce the impact of the source training model, resulting in additional improvements. The truncated feature is determined by removing the Rank-1 feature associated with the largest singular value decomposed from the high-level convolutional layers of the clean sample. Extensive experiments conducted on the ImageNet-Compatible and CIFAR-10 datasets demonstrate the individual and mutual benefits of our proposed two components, which outperform the state-of-the-art methods by a large margin in black-box targeted attacks.
Exploring Frequencies via Feature Mixing and Meta-Learning for Improving Adversarial Transferability
May 06, 2024Recent studies have shown that Deep Neural Networks (DNNs) are susceptible to adversarial attacks, with frequency-domain analysis underscoring the significance of high-frequency components in influencing model predictions. Conversely, targeting low-frequency components has been effective in enhancing attack transferability on black-box models. In this study, we introduce a frequency decomposition-based feature mixing method to exploit these frequency characteristics in both clean and adversarial samples. Our findings suggest that incorporating features of clean samples into adversarial features extracted from adversarial examples is more effective in attacking normally-trained models, while combining clean features with the adversarial features extracted from low-frequency parts decomposed from the adversarial samples yields better results in attacking defense models. However, a conflict issue arises when these two mixing approaches are employed simultaneously. To tackle the issue, we propose a cross-frequency meta-optimization approach comprising the meta-train step, meta-test step, and final update. In the meta-train step, we leverage the low-frequency components of adversarial samples to boost the transferability of attacks against defense models. Meanwhile, in the meta-test step, we utilize adversarial samples to stabilize gradients, thereby enhancing the attack's transferability against normally trained models. For the final update, we update the adversarial sample based on the gradients obtained from both meta-train and meta-test steps. Our proposed method is evaluated through extensive experiments on the ImageNet-Compatible dataset, affirming its effectiveness in improving the transferability of attacks on both normally-trained CNNs and defense models. The source code is available at https://github.com/WJJLL/MetaSSA.
Selective Domain-Invariant Feature for Generalizable Deepfake Detection
Mar 19, 2024



With diverse presentation forgery methods emerging continually, detecting the authenticity of images has drawn growing attention. Although existing methods have achieved impressive accuracy in training dataset detection, they still perform poorly in the unseen domain and suffer from forgery of irrelevant information such as background and identity, affecting generalizability. To solve this problem, we proposed a novel framework Selective Domain-Invariant Feature (SDIF), which reduces the sensitivity to face forgery by fusing content features and styles. Specifically, we first use a Farthest-Point Sampling (FPS) training strategy to construct a task-relevant style sample representation space for fusing with content features. Then, we propose a dynamic feature extraction module to generate features with diverse styles to improve the performance and effectiveness of the feature extractor. Finally, a domain separation strategy is used to retain domain-related features to help distinguish between real and fake faces. Both qualitative and quantitative results in existing benchmarks and proposals demonstrate the effectiveness of our approach.