 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pragmatic VLA Foundation Model
Jan 26, 2026Offering great potential in robotic manipulation, a capable Vision-Language-Action (VLA) foundation model is expected to faithfully generalize across tasks and platforms while ensuring cost efficiency (e.g., data and GPU hours required for adaptation). To this end, we develop LingBot-VLA with around 20,000 hours of real-world data from 9 popular dual-arm robot configurations. Through a systematic assessment on 3 robotic platforms, each completing 100 tasks with 130 post-training episodes per task, our model achieves clear superiority over competitors, showcasing its strong performance and broad generalizability. We have also built an efficient codebase, which delivers a throughput of 261 samples per second per GPU with an 8-GPU training setup, representing a 1.5~2.8$\times$ (depending on the relied VLM base model) speedup over existing VLA-oriented codebases. The above features ensure that our model is well-suited for real-world deployment. To advance the field of robot learning, we provide open access to the code, base model, and benchmark data, with a focus on enabling more challenging tasks and promoting sound evaluation standards.
Evolving Excellence: Automated Optimization of LLM-based Agents
Dec 09, 2025Agentic AI systems built on large language models (LLMs) offer significant potential for automating complex workflows, from software development to customer support. However, LLM agents often underperform due to suboptimal configurations; poorly tuned prompts, tool descriptions, and parameters that typically require weeks of manual refinement. Existing optimization methods either are too complex for general use or treat components in isolation, missing critical interdependencies. We present ARTEMIS, a no-code evolutionary optimization platform that jointly optimizes agent configurations through semantically-aware genetic operators. Given only a benchmark script and natural language goals, ARTEMIS automatically discovers configurable components, extracts performance signals from execution logs, and evolves configurations without requiring architectural modifications. We evaluate ARTEMIS on four representative agent systems: the \emph{ALE Agent} for competitive programming on AtCoder Heuristic Contest, achieving a \textbf{$13.6\%$ improvement} in acceptance rate; the \emph{Mini-SWE Agent} for code optimization on SWE-Perf, with a statistically significant \textbf{10.1\% performance gain}; and the \emph{CrewAI Agent} for cost and mathematical reasoning on Math Odyssey, achieving a statistically significant \textbf{$36.9\%$ reduction} in the number of tokens required for evaluation. We also evaluate the \emph{MathTales-Teacher Agent} powered by a smaller open-source model (Qwen2.5-7B) on GSM8K primary-level mathematics problems, achieving a \textbf{22\% accuracy improvement} and demonstrating that ARTEMIS can optimize agents based on both commercial and local models.
ForgeDAN: An Evolutionary Framework for Jailbreaking Aligned Large Language Models
Nov 17, 2025



The rapid adoption of large language models (LLMs) has brought both transformative applications and new security risks, including jailbreak attacks that bypass alignment safeguards to elicit harmful outputs. Existing automated jailbreak generation approaches e.g. AutoDAN, suffer from limited mutation diversity, shallow fitness evaluation, and fragile keyword-based detection. To address these limitations, we propose ForgeDAN, a novel evolutionary framework for generating semantically coherent and highly effective adversarial prompts against aligned LLMs. First, ForgeDAN introduces multi-strategy textual perturbations across \textit{character, word, and sentence-level} operations to enhance attack diversity; then we employ interpretable semantic fitness evaluation based on a text similarity model to guide the evolutionary process toward semantically relevant and harmful outputs; finally, ForgeDAN integrates dual-dimensional jailbreak judgment, leveraging an LLM-based classifier to jointly assess model compliance and output harmfulness, thereby reducing false positives and improving detection effectiveness. Our evaluation demonstrates ForgeDAN achieves high jailbreaking success rates while maintaining naturalness and stealth, outperforming existing SOTA solutions.
When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and Audios
Jul 27, 2025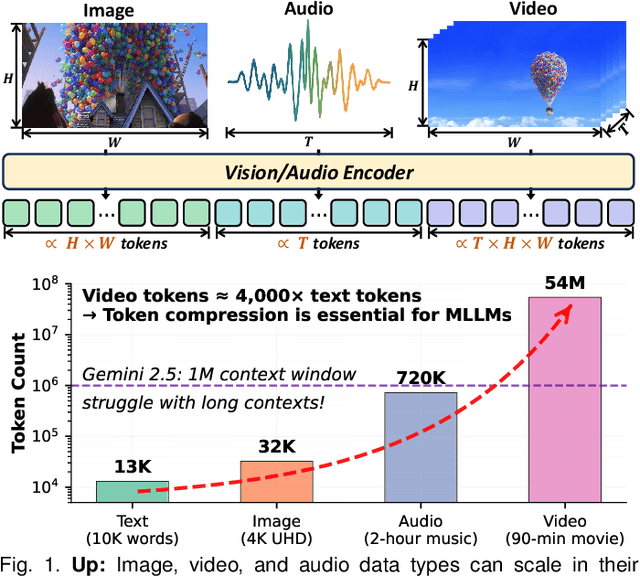
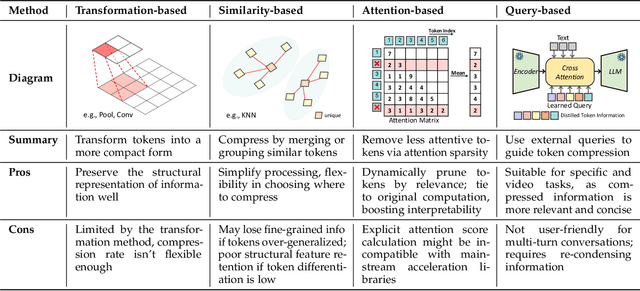
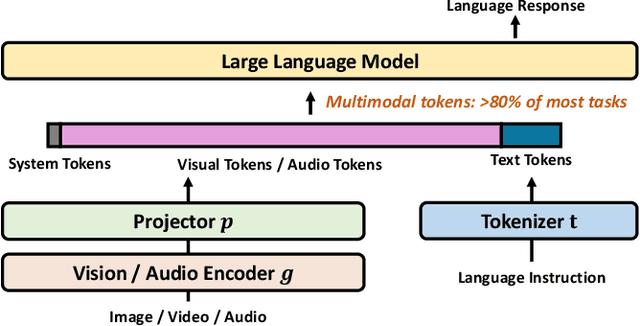
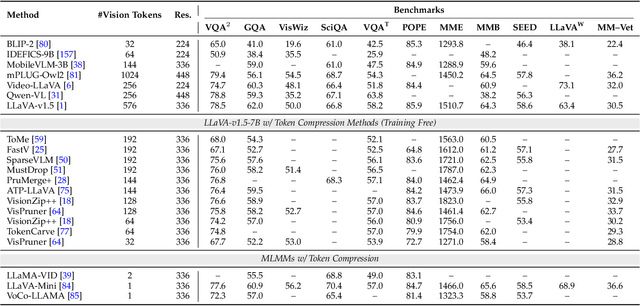
Multimodal large language models (MLLMs) have made remarkable strides, largely driven by their ability to process increasingly long and complex contexts, such as high-resolution images, extended video sequences, and lengthy audio input. While this ability significantly enhances MLLM capabilities, it introduces substantial computational challenges, primarily due to the quadratic complexity of self-attention mechanisms with numerous input tokens. To mitigate these bottlenecks, token compression has emerged as an auspicious and critical approach, efficiently reducing the number of tokens during both training and inference. In this paper, we present the first systematic survey and synthesis of the burgeoning field of multimodal long context token compression. Recognizing that effective compression strategies are deeply tied to the unique characteristics and redundancies of each modality, we categorize existing approaches by their primary data focus, enabling researchers to quickly access and learn methods tailored to their specific area of interest: (1) image-centric compression, which addresses spatial redundancy in visual data; (2) video-centric compression, which tackles spatio-temporal redundancy in dynamic sequences; and (3) audio-centric compression, which handles temporal and spectral redundancy in acoustic signals. Beyond this modality-driven categorization, we further dissect methods based on their underlying mechanisms, including transformation-based, similarity-based, attention-based, and query-based approaches. By providing a comprehensive and structured overview, this survey aims to consolidate current progress, identify key challenges, and inspire future research directions in this rapidly evolving domain. We also maintain a public repository to continuously track and update the latest advances in this promising area.
Poison as Cure: Visual Noise for Mitigating Object Hallucinations in LVMs
Jan 31, 2025



Large vision-language models (LVMs) extend large language models (LLMs) with visual perception capabilities, enabling them to process and interpret visual information. A major challenge compromising their reliability is object hallucination that LVMs may generate plausible but factually inaccurate information. We propose a novel visual adversarial perturbation (VAP) method to mitigate this hallucination issue. VAP alleviates LVM hallucination by applying strategically optimized visual noise without altering the base model. Our approach formulates hallucination suppression as an optimization problem, leveraging adversarial strategies to generate beneficial visual perturbations that enhance the model's factual grounding and reduce parametric knowledge bias. Extensive experimental results demonstrate that our method consistently reduces object hallucinations across 8 state-of-the-art LVMs, validating its efficacy across diverse evaluations.
ZhoBLiMP: a Systematic Assessment of Language Models with Linguistic Minimal Pairs in Chinese
Nov 09, 2024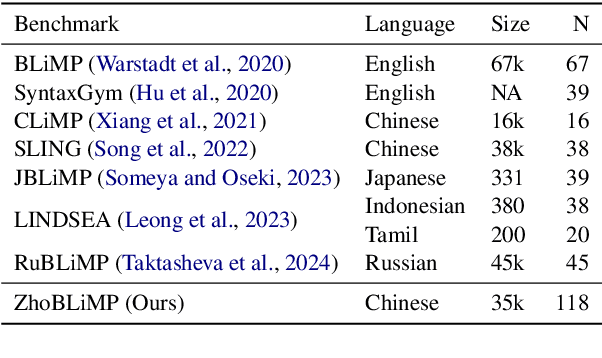

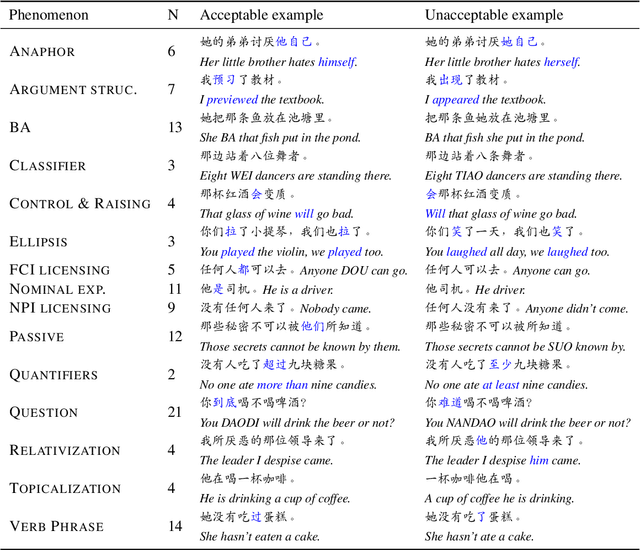
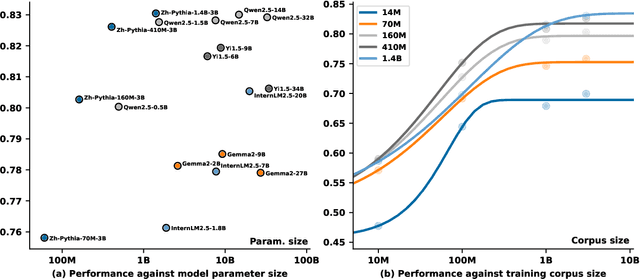
Whether and how language models (LMs) acquire the syntax of natural languages has been widely evaluated under the minimal pair paradigm. However, a lack of wide-coverage benchmarks in languages other than English has constrained systematic investigations into the issue. Addressing it, we first introduce ZhoBLiMP, the most comprehensive benchmark of linguistic minimal pairs for Chinese to date, with 118 paradigms, covering 15 linguistic phenomena. We then train 20 LMs of different sizes (14M to 1.4B) on Chinese corpora of various volumes (100M to 3B tokens) and evaluate them along with 14 off-the-shelf LLMs on ZhoBLiMP. The overall results indicate that Chinese grammar can be mostly learned by models with around 500M parameters, trained on 1B tokens with one epoch, showing limited benefits for further scaling. Most (N=95) linguistic paradigms are of easy or medium difficulty for LMs, while there are still 13 paradigms that remain challenging even for models with up to 32B parameters. In regard to how LMs acquire Chinese grammar, we observe a U-shaped learning pattern in several phenomena, similar to those observed in child language acquisition.
Towards Adversarial Robustness via Debiased High-Confidence Logit Alignment
Aug 12, 2024



Despite the significant advances that deep neural networks (DNNs) have achieved in various visual tasks, they still exhibit vulnerability to adversarial examples, leading to serious security concerns. Recent adversarial training techniques have utilized inverse adversarial attacks to generate high-confidence examples, aiming to align the distributions of adversarial examples with the high-confidence regions of their corresponding classes. However, in this paper, our investigation reveals that high-confidence outputs under inverse adversarial attacks are correlated with biased feature activation. Specifically, training with inverse adversarial examples causes the model's attention to shift towards background features, introducing a spurious correlation bias. To address this bias, we propose Debiased High-Confidence Adversarial Training (DHAT), a novel approach that not only aligns the logits of adversarial examples with debiased high-confidence logits obtained from inverse adversarial examples, but also restores the model's attention to its normal state by enhancing foreground logit orthogonality. Extensive experiments demonstrate that DHAT achieves state-of-the-art performance and exhibits robust generalization capabilities across various vision datasets. Additionally, DHAT can seamlessly integrate with existing advanced adversarial training techniques for improving the performance.
A Reference-free Metric for Language-Queried Audio Source Separation using Contrastive Language-Audio Pretraining
Jul 06, 2024



Language-queried audio source separation (LASS) aims to separate an audio source guided by a text query, with the signal-to-distortion ratio (SDR)-based metrics being commonly used to objectively measure the quality of the separated audio. However, the SDR-based metrics require a reference signal, which is often difficult to obtain in real-world scenarios. In addition, with the SDR-based metrics, the content information of the text query is not considered effectively in LASS. This paper introduces a reference-free evaluation metric using a contrastive language-audio pretraining (CLAP) module, termed CLAPScore, which measures the semantic similarity between the separated audio and the text query. Unlike SDR, the proposed CLAPScore metric evaluates the quality of the separated audio based on the content information of the text query, without needing a reference signal. Experimental results show that the CLAPScore metric provides an effective evaluation of the semantic relevance of the separated audio to the text query, as compared to the SDR metric, offering an alternative for the performance evaluation of LASS systems.
Mitigating Low-Frequency Bias: Feature Recalibration and Frequency Attention Regularization for Adversarial Robustness
Jul 04, 2024


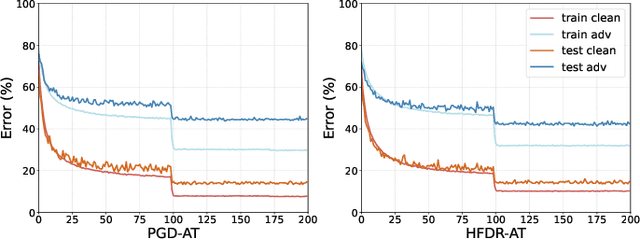
Ensuring the robustness of computer vision models against adversarial attacks is a significant and long-lasting objective. Motivated by adversarial attacks, researchers have devoted considerable efforts to enhancing model robustness by adversarial training (AT). However, we observe that while AT improves the models' robustness against adversarial perturbations, it fails to improve their ability to effectively extract features across all frequency components. Each frequency component contains distinct types of crucial information: low-frequency features provide fundamental structural insights, while high-frequency features capture intricate details and textures. In particular, AT tends to neglect the reliance on susceptible high-frequency features. This low-frequency bias impedes the model's ability to effectively leverage the potentially meaningful semantic information present in high-frequency features. This paper proposes a novel module called High-Frequency Feature Disentanglement and Recalibration (HFDR), which separates features into high-frequency and low-frequency components and recalibrates the high-frequency feature to capture latent useful semantics. Additionally, we introduce frequency attention regularization to magnitude the model's extraction of different frequency features and mitigate low-frequency bias during AT. Extensive experiments showcase the immense potential and superiority of our approach in resisting various white-box attacks, transfer attacks, and showcasing strong generalization capabilities.
Harmonizing Feature Maps: A Graph Convolutional Approach for Enhancing Adversarial Robustness
Jun 17, 2024



The vulnerability of Deep Neural Networks to adversarial perturbations presents significant security concerns, as the imperceptible perturbations can contaminate the feature space and lead to incorrect predictions. Recent studies have attempted to calibrate contaminated features by either suppressing or over-activating particular channels. Despite these efforts, we claim that adversarial attacks exhibit varying disruption levels across individual channels. Furthermore, we argue that harmonizing feature maps via graph and employing graph convolution can calibrate contaminated features. To this end, we introduce an innovative plug-and-play module called Feature Map-based Reconstructed Graph Convolution (FMR-GC). FMR-GC harmonizes feature maps in the channel dimension to reconstruct the graph, then employs graph convolution to capture neighborhood information, effectively calibrating contaminated features. Extensive experiments have demonstrated the superior performance and scalability of FMR-GC. Moreover, our model can be combined with advanced adversarial training methods to considerably enhance robustness without compromising the model's clean accuracy.