 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQianfan-OCR: A Unified End-to-End Model for Document Intelligence
Mar 11, 2026We present Qianfan-OCR, a 4B-parameter end-to-end vision-language model that unifies document parsing, layout analysis, and document understanding within a single architecture. It performs direct image-to-Markdown conversion and supports diverse prompt-driven tasks including table extraction, chart understanding, document QA, and key information extraction. To address the loss of explicit layout analysis in end-to-end OCR, we propose Layout-as-Thought, an optional thinking phase triggered by special think tokens that generates structured layout representations -- bounding boxes, element types, and reading order -- before producing final outputs, recovering layout grounding capabilities while improving accuracy on complex layouts. Qianfan-OCR ranks first among end-to-end models on OmniDocBench v1.5 (93.12) and OlmOCR Bench (79.8), achieves competitive results on OCRBench, CCOCR, DocVQA, and ChartQA against general VLMs of comparable scale, and attains the highest average score on public key information extraction benchmarks, surpassing Gemini-3.1-Pro, Seed-2.0, and Qwen3-VL-235B. The model is publicly accessible via the Baidu AI Cloud Qianfan platform.
WiFlow: A Lightweight WiFi-based Continuous Human Pose Estimation Network with Spatio-Temporal Feature Decoupling
Feb 09, 2026Human pose estimation is fundamental to intelligent perception in the Internet of Things (IoT), enabling applications ranging from smart healthcare to human-computer interaction. While WiFi-based methods have gained traction, they often struggle with continuous motion and high computational overhead. This work presents WiFlow, a novel framework for continuous human pose estimation using WiFi signals. Unlike vision-based approaches such as two-dimensional deep residual networks that treat Channel State Information (CSI) as images, WiFlow employs an encoder-decoder architecture. The encoder captures spatio-temporal features of CSI using temporal and asymmetric convolutions, preserving the original sequential structure of signals. It then refines keypoint features of human bodies to be tracked and capture their structural dependencies via axial attention. The decoder subsequently maps the encoded high-dimensional features into keypoint coordinates. Trained on a self-collected dataset of 360,000 synchronized CSI-pose samples from 5 subjects performing continuous sequences of 8 daily activities, WiFlow achieves a Percentage of Correct Keypoints (PCK) of 97.00% at a threshold of 20% (PCK@20) and 99.48% at PCK@50, with a mean per-joint position error of 0.008m. With only 4.82M parameters, WiFlow significantly reduces model complexity and computational cost, establishing a new performance baseline for practical WiFi-based human pose estimation. Our code and datasets are available at https://github.com/DY2434/WiFlow-WiFi-Pose-Estimation-with-Spatio-Temporal-Decoupling.git.
MobileManiBench: Simplifying Model Verification for Mobile Manipulation
Feb 05, 2026Vision-language-action models have advanced robotic manipulation but remain constrained by reliance on the large, teleoperation-collected datasets dominated by the static, tabletop scenes. We propose a simulation-first framework to verify VLA architectures before real-world deployment and introduce MobileManiBench, a large-scale benchmark for mobile-based robotic manipulation. Built on NVIDIA Isaac Sim and powered by reinforcement learning, our pipeline autonomously generates diverse manipulation trajectories with rich annotations (language instructions, multi-view RGB-depth-segmentation images, synchronized object/robot states and actions). MobileManiBench features 2 mobile platforms (parallel-gripper and dexterous-hand robots), 2 synchronized cameras (head and right wrist), 630 objects in 20 categories, 5 skills (open, close, pull, push, pick) with over 100 tasks performed in 100 realistic scenes, yielding 300K trajectories. This design enables controlled, scalable studies of robot embodiments, sensing modalities, and policy architectures, accelerating research on data efficiency and generalization. We benchmark representative VLA models and report insights into perception, reasoning, and control in complex simulated environments.
Learning the Basis: A Kolmogorov-Arnold Network Approach Embedding Green's Function Priors
Nov 13, 2025The Method of Moments (MoM) is constrained by the usage of static, geometry-defined basis functions, such as the Rao-Wilton-Glisson (RWG) basis. This letter reframes electromagnetic modeling around a learnable basis representation rather than solving for the coefficients over a fixed basis. We first show that the RWG basis is essentially a static and piecewise-linear realization of the Kolmogorov-Arnold representation theorem. Inspired by this insight, we propose PhyKAN, a physics-informed Kolmogorov-Arnold Network (KAN) that generalizes RWG into a learnable and adaptive basis family. Derived from the EFIE, PhyKAN integrates a local KAN branch with a global branch embedded with Green's function priors to preserve physical consistency. It is demonstrated that, across canonical geometries, PhyKAN achieves sub-0.01 reconstruction errors as well as accurate, unsupervised radar cross section predictions, offering an interpretable, physics-consistent bridge between classical solvers and modern neural network models for electromagnetic modeling.
LLM Enabled Multi-Agent System for 6G Networks: Framework and Method of Dual-Loop Edge-Terminal Collaboration
Sep 05, 2025The ubiquitous computing resources in 6G networks provide ideal environments for the fusion of large language models (LLMs) and intelligent services through the agent framework. With auxiliary modules and planning cores, LLM-enabled agents can autonomously plan and take actions to deal with diverse environment semantics and user intentions. However, the limited resources of individual network devices significantly hinder the efficient operation of LLM-enabled agents with complex tool calls, highlighting the urgent need for efficient multi-level device collaborations. To this end, the framework and method of the LLM-enabled multi-agent system with dual-loop terminal-edge collaborations are proposed in 6G networks. Firstly, the outer loop consists of the iterative collaborations between the global agent and multiple sub-agents deployed on edge servers and terminals, where the planning capability is enhanced through task decomposition and parallel sub-task distribution. Secondly, the inner loop utilizes sub-agents with dedicated roles to circularly reason, execute, and replan the sub-task, and the parallel tool calling generation with offloading strategies is incorporated to improve efficiency. The improved task planning capability and task execution efficiency are validated through the conducted case study in 6G-supported urban safety governance. Finally, the open challenges and future directions are thoroughly analyzed in 6G networks, accelerating the advent of the 6G era.
Denoising, segmentation and volumetric rendering of optical coherence tomography angiography (OCTA) image using deep learning techniques: a review
Feb 20, 2025Optical coherence tomography angiography (OCTA) is a non-invasive imaging technique widely used to study vascular structures and micro-circulation dynamics in the retina and choroid. OCTA has been widely used in clinics for diagnosing ocular disease and monitoring its progression, because OCTA is safer and faster than dye-based angiography while retaining the ability to characterize micro-scale structures. However, OCTA data contains many inherent noises from the devices and acquisition protocols and suffers from various types of artifacts, which impairs diagnostic accuracy and repeatability. Deep learning (DL) based imaging analysis models are able to automatically detect and remove artifacts and noises, and enhance the quality of image data. It is also a powerful tool for segmentation and identification of normal and pathological structures in the images. Thus, the value of OCTA imaging can be significantly enhanced by the DL-based approaches for interpreting and performing measurements and predictions on the OCTA data. In this study, we reviewed literature on the DL models for OCTA images in the latest five years. In particular, we focused on discussing the current problems in the OCTA data and the corresponding design principles of the DL models. We also reviewed the state-of-art DL models for 3D volumetric reconstruction of the vascular networks and pathological structures such as the edema and distorted optic disc. In addition, the publicly available dataset of OCTA images are summarized at the end of this review. Overall, this review can provide valuable insights for engineers to develop novel DL models by utilizing the characteristics of OCTA signals and images. The pros and cons of each DL methods and their applications discussed in this review can be helpful to assist technicians and clinicians to use proper DL models for fundamental research and disease screening.
Graph-Enhanced Dual-Stream Feature Fusion with Pre-Trained Model for Acoustic Traffic Monitoring
Dec 26, 2024



Microphone array techniques are widely used in sound source localization and smart city acoustic-based traffic monitoring, but these applications face significant challenges due to the scarcity of labeled real-world traffic audio data and the complexity and diversity of application scenarios. The DCASE Challenge's Task 10 focuses on using multi-channel audio signals to count vehicles (cars or commercial vehicles) and identify their directions (left-to-right or vice versa). In this paper, we propose a graph-enhanced dual-stream feature fusion network (GEDF-Net) for acoustic traffic monitoring, which simultaneously considers vehicle type and direction to improve detection. We propose a graph-enhanced dual-stream feature fusion strategy which consists of a vehicle type feature extraction (VTFE) branch, a vehicle direction feature extraction (VDFE) branch, and a frame-level feature fusion module to combine the type and direction feature for enhanced performance. A pre-trained model (PANNs) is used in the VTFE branch to mitigate data scarcity and enhance the type features, followed by a graph attention mechanism to exploit temporal relationships and highlight important audio events within these features. The frame-level fusion of direction and type features enables fine-grained feature representation, resulting in better detection performance. Experiments demonstrate the effectiveness of our proposed method. GEDF-Net is our submission that achieved 1st place in the DCASE 2024 Challenge Task 10.
UniGraspTransformer: Simplified Policy Distillation for Scalable Dexterous Robotic Grasping
Dec 03, 2024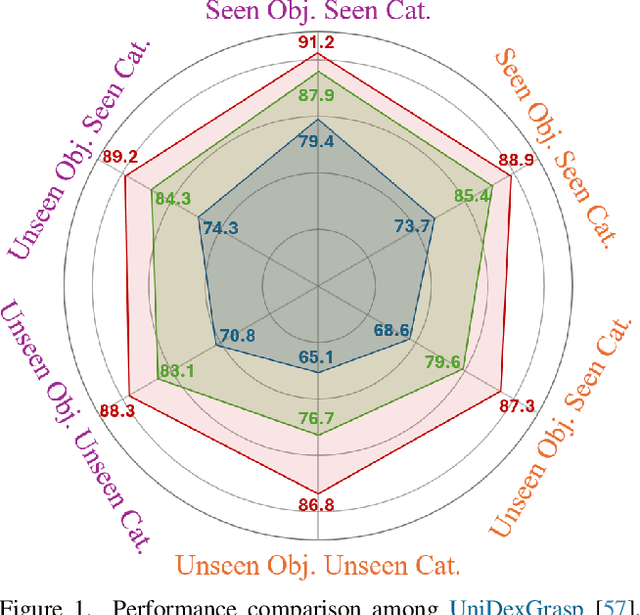

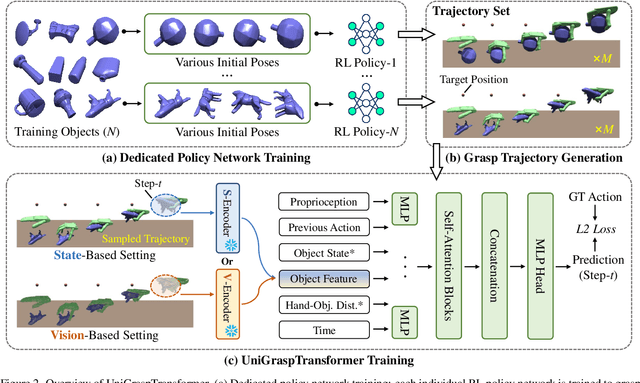

We introduce UniGraspTransformer, a universal Transformer-based network for dexterous robotic grasping that simplifies training while enhancing scalability and performance. Unlike prior methods such as UniDexGrasp++, which require complex, multi-step training pipelines, UniGraspTransformer follows a streamlined process: first, dedicated policy networks are trained for individual objects using reinforcement learning to generate successful grasp trajectories; then, these trajectories are distilled into a single, universal network. Our approach enables UniGraspTransformer to scale effectively, incorporating up to 12 self-attention blocks for handling thousands of objects with diverse poses. Additionally, it generalizes well to both idealized and real-world inputs, evaluated in state-based and vision-based settings. Notably, UniGraspTransformer generates a broader range of grasping poses for objects in various shapes and orientations, resulting in more diverse grasp strategies. Experimental results demonstrate significant improvements over state-of-the-art, UniDexGrasp++, across various object categories, achieving success rate gains of 3.5%, 7.7%, and 10.1% on seen objects, unseen objects within seen categories, and completely unseen objects, respectively, in the vision-based setting. Project page: https://dexhand.github.io/UniGraspTransformer.
Independent Feature Enhanced Crossmodal Fusion for Match-Mismatch Classification of Speech Stimulus and EEG Response
Oct 19, 2024



It is crucial for auditory attention decoding to classify matched and mismatched speech stimuli with corresponding EEG responses by exploring their relationship. However, existing methods often adopt two independent networks to encode speech stimulus and EEG response, which neglect the relationship between these signals from the two modalities. In this paper, we propose an independent feature enhanced crossmodal fusion model (IFE-CF) for match-mismatch classification, which leverages the fusion feature of the speech stimulus and the EEG response to achieve auditory EEG decoding. Specifically, our IFE-CF contains a crossmodal encoder to encode the speech stimulus and the EEG response with a two-branch structure connected via crossmodal attention mechanism in the encoding process, a multi-channel fusion module to fuse features of two modalities by aggregating the interaction feature obtained from the crossmodal encoder and the independent feature obtained from the speech stimulus and EEG response, and a predictor to give the matching result. In addition, the causal mask is introduced to consider the time delay of the speech-EEG pair in the crossmodal encoder, which further enhances the feature representation for match-mismatch classification. Experiments demonstrate our method's effectiveness with better classification accuracy, as compared with the baseline of the Auditory EEG Decoding Challenge 2023.
Gaussian Garments: Reconstructing Simulation-Ready Clothing with Photorealistic Appearance from Multi-View Video
Sep 12, 2024We introduce Gaussian Garments, a novel approach for reconstructing realistic simulation-ready garment assets from multi-view videos. Our method represents garments with a combination of a 3D mesh and a Gaussian texture that encodes both the color and high-frequency surface details. This representation enables accurate registration of garment geometries to multi-view videos and helps disentangle albedo textures from lighting effects. Furthermore, we demonstrate how a pre-trained graph neural network (GNN) can be fine-tuned to replicate the real behavior of each garment. The reconstructed Gaussian Garments can be automatically combined into multi-garment outfits and animated with the fine-tuned GNN.