 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileManiBench: Simplifying Model Verification for Mobile Manipulation
Feb 05, 2026Vision-language-action models have advanced robotic manipulation but remain constrained by reliance on the large, teleoperation-collected datasets dominated by the static, tabletop scenes. We propose a simulation-first framework to verify VLA architectures before real-world deployment and introduce MobileManiBench, a large-scale benchmark for mobile-based robotic manipulation. Built on NVIDIA Isaac Sim and powered by reinforcement learning, our pipeline autonomously generates diverse manipulation trajectories with rich annotations (language instructions, multi-view RGB-depth-segmentation images, synchronized object/robot states and actions). MobileManiBench features 2 mobile platforms (parallel-gripper and dexterous-hand robots), 2 synchronized cameras (head and right wrist), 630 objects in 20 categories, 5 skills (open, close, pull, push, pick) with over 100 tasks performed in 100 realistic scenes, yielding 300K trajectories. This design enables controlled, scalable studies of robot embodiments, sensing modalities, and policy architectures, accelerating research on data efficiency and generalization. We benchmark representative VLA models and report insights into perception, reasoning, and control in complex simulated environments.
Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos
Oct 24, 2025



This paper presents a novel approach for pretraining robotic manipulation Vision-Language-Action (VLA) models using a large corpus of unscripted real-life video recordings of human hand activities. Treating human hand as dexterous robot end-effector, we show that "in-the-wild" egocentric human videos without any annotations can be transformed into data formats fully aligned with existing robotic V-L-A training data in terms of task granularity and labels. This is achieved by the development of a fully-automated holistic human activity analysis approach for arbitrary human hand videos. This approach can generate atomic-level hand activity segments and their language descriptions, each accompanied with framewise 3D hand motion and camera motion. We process a large volume of egocentric videos and create a hand-VLA training dataset containing 1M episodes and 26M frames. This training data covers a wide range of objects and concepts, dexterous manipulation tasks, and environment variations in real life, vastly exceeding the coverage of existing robot data. We design a dexterous hand VLA model architecture and pretrain the model on this dataset. The model exhibits strong zero-shot capabilities on completely unseen real-world observations. Additionally, fine-tuning it on a small amount of real robot action data significantly improves task success rates and generalization to novel objects in real robotic experiments. We also demonstrate the appealing scaling behavior of the model's task performance with respect to pretraining data scale. We believe this work lays a solid foundation for scalable VLA pretraining, advancing robots toward truly generalizable embodied intelligence.
UniGraspTransformer: Simplified Policy Distillation for Scalable Dexterous Robotic Grasping
Dec 03, 2024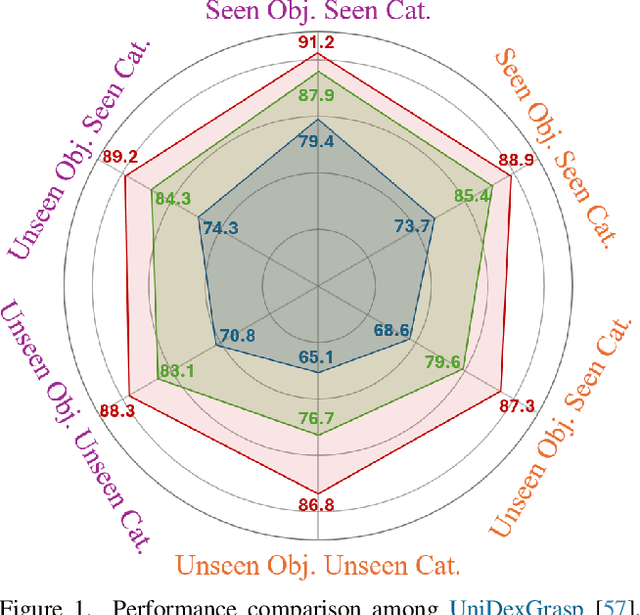

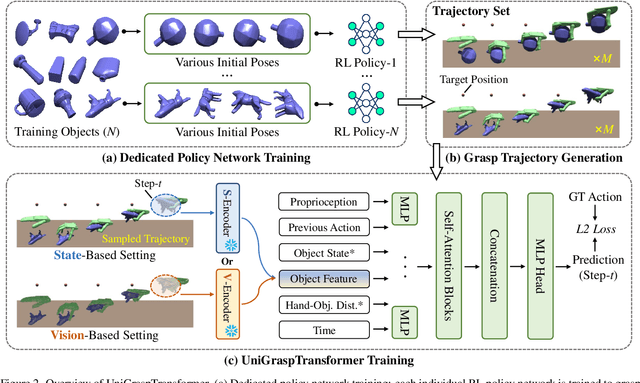

We introduce UniGraspTransformer, a universal Transformer-based network for dexterous robotic grasping that simplifies training while enhancing scalability and performance. Unlike prior methods such as UniDexGrasp++, which require complex, multi-step training pipelines, UniGraspTransformer follows a streamlined process: first, dedicated policy networks are trained for individual objects using reinforcement learning to generate successful grasp trajectories; then, these trajectories are distilled into a single, universal network. Our approach enables UniGraspTransformer to scale effectively, incorporating up to 12 self-attention blocks for handling thousands of objects with diverse poses. Additionally, it generalizes well to both idealized and real-world inputs, evaluated in state-based and vision-based settings. Notably, UniGraspTransformer generates a broader range of grasping poses for objects in various shapes and orientations, resulting in more diverse grasp strategies. Experimental results demonstrate significant improvements over state-of-the-art, UniDexGrasp++, across various object categories, achieving success rate gains of 3.5%, 7.7%, and 10.1% on seen objects, unseen objects within seen categories, and completely unseen objects, respectively, in the vision-based setting. Project page: https://dexhand.github.io/UniGraspTransformer.
CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation
Nov 29, 2024



The advancement of large Vision-Language-Action (VLA) models has significantly improved robotic manipulation in terms of language-guided task execution and generalization to unseen scenarios. While existing VLAs adapted from pretrained large Vision-Language-Models (VLM) have demonstrated promising generalizability, their task performance is still unsatisfactory as indicated by the low tasks success rates in different environments. In this paper, we present a new advanced VLA architecture derived from VLM. Unlike previous works that directly repurpose VLM for action prediction by simple action quantization, we propose a omponentized VLA architecture that has a specialized action module conditioned on VLM output. We systematically study the design of the action module and demonstrates the strong performance enhancement with diffusion action transformers for action sequence modeling, as well as their favorable scaling behaviors. We also conduct comprehensive experiments and ablation studies to evaluate the efficacy of our models with varied designs. The evaluation on 5 robot embodiments in simulation and real work shows that our model not only significantly surpasses existing VLAs in task performance and but also exhibits remarkable adaptation to new robots and generalization to unseen objects and backgrounds. It exceeds the average success rates of OpenVLA which has similar model size (7B) with ours by over 35% in simulated evaluation and 55% in real robot experiments. It also outperforms the large RT-2-X model (55B) by 18% absolute success rates in simulation. Code and models can be found on our project page (https://cogact.github.io/).
RLRF4Rec: Reinforcement Learning from Recsys Feedback for Enhanced Recommendation Reranking
Oct 08, 2024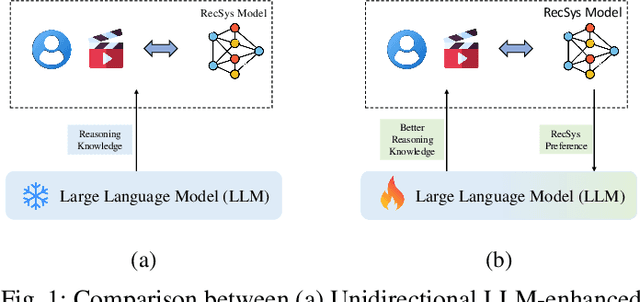



Large Language Models (LLMs) have demonstrated remarkable performance across diverse domains, prompting researchers to explore their potential for use in recommendation systems. Initial attempts have leveraged the exceptional capabilities of LLMs, such as rich knowledge and strong generalization through In-context Learning, which involves phrasing the recommendation task as prompts. Nevertheless, the performance of LLMs in recommendation tasks remains suboptimal due to a substantial disparity between the training tasks for LLMs and recommendation tasks and inadequate recommendation data during pre-training. This paper introduces RLRF4Rec, a novel framework integrating Reinforcement Learning from Recsys Feedback for Enhanced Recommendation Reranking(RLRF4Rec) with LLMs to address these challenges. Specifically, We first have the LLM generate inferred user preferences based on user interaction history, which is then used to augment traditional ID-based sequence recommendation models. Subsequently, we trained a reward model based on knowledge augmentation recommendation models to evaluate the quality of the reasoning knowledge from LLM. We then select the best and worst responses from the N samples to construct a dataset for LLM tuning. Finally, we design a structure alignment strategy with Direct Preference Optimization(DPO). We validate the effectiveness of RLRF4Rec through extensive experiments, demonstrating significant improvements in recommendation re-ranking metrics compared to baselines. This demonstrates that our approach significantly improves the capability of LLMs to respond to instructions within recommender systems.
PPTC-R benchmark: Towards Evaluating the Robustness of Large Language Models for PowerPoint Task Completion
Mar 06, 2024



The growing dependence on Large Language Models (LLMs) for finishing user instructions necessitates a comprehensive understanding of their robustness to complex task completion in real-world situations. To address this critical need, we propose the PowerPoint Task Completion Robustness benchmark (PPTC-R) to measure LLMs' robustness to the user PPT task instruction and software version. Specifically, we construct adversarial user instructions by attacking user instructions at sentence, semantic, and multi-language levels. To assess the robustness of Language Models to software versions, we vary the number of provided APIs to simulate both the newest version and earlier version settings. Subsequently, we test 3 closed-source and 4 open-source LLMs using a benchmark that incorporates these robustness settings, aiming to evaluate how deviations impact LLMs' API calls for task completion. We find that GPT-4 exhibits the highest performance and strong robustness in our benchmark, particularly in the version update and the multilingual settings. However, we find that all LLMs lose their robustness when confronted with multiple challenges (e.g., multi-turn) simultaneously, leading to significant performance drops. We further analyze the robustness behavior and error reasons of LLMs in our benchmark, which provide valuable insights for researchers to understand the LLM's robustness in task completion and develop more robust LLMs and agents. We release the code and data at \url{https://github.com/ZekaiGalaxy/PPTCR}.
Competition-Level Problems are Effective LLM Evaluators
Dec 05, 2023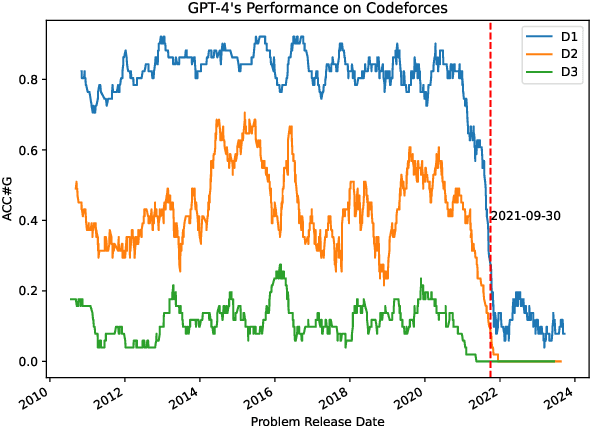



Large language models (LLMs) have demonstrated impressive reasoning capabilities, yet there is ongoing debate about these abilities and the potential data contamination problem recently. This paper aims to evaluate the reasoning capacities of LLMs, specifically in solving recent competition-level programming problems in Codeforces, which are expert-crafted and unique, requiring deep understanding and robust reasoning skills. We first provide a comprehensive evaluation of GPT-4's peiceived zero-shot performance on this task, considering various aspects such as problems' release time, difficulties, and types of errors encountered. Surprisingly, the peiceived performance of GPT-4 has experienced a cliff like decline in problems after September 2021 consistently across all the difficulties and types of problems, which shows the potential data contamination, as well as the challenges for any existing LLM to solve unseen complex reasoning problems. We further explore various approaches such as fine-tuning, Chain-of-Thought prompting and problem description simplification, unfortunately none of them is able to consistently mitigate the challenges. Through our work, we emphasis the importance of this excellent data source for assessing the genuine reasoning capabilities of LLMs, and foster the development of LLMs with stronger reasoning abilities and better generalization in the future.
PPTC Benchmark: Evaluating Large Language Models for PowerPoint Task Completion
Nov 07, 2023



Recent evaluations of Large Language Models (LLMs) have centered around testing their zero-shot/few-shot capabilities for basic natural language tasks and their ability to translate instructions into tool APIs. However, the evaluation of LLMs utilizing complex tools to finish multi-turn, multi-modal instructions in a complex multi-modal environment has not been investigated. To address this gap, we introduce the PowerPoint Task Completion (PPTC) benchmark to assess LLMs' ability to create and edit PPT files based on user instructions. It contains 279 multi-turn sessions covering diverse topics and hundreds of instructions involving multi-modal operations. We also propose the PPTX-Match Evaluation System that evaluates if LLMs finish the instruction based on the prediction file rather than the label API sequence, thus it supports various LLM-generated API sequences. We measure 3 closed LLMs and 6 open-source LLMs. The results show that GPT-4 outperforms other LLMs with 75.1\% accuracy in single-turn dialogue testing but faces challenges in completing entire sessions, achieving just 6\% session accuracy. We find three main error causes in our benchmark: error accumulation in the multi-turn session, long PPT template processing, and multi-modality perception. These pose great challenges for future LLM and agent systems. We release the data, code, and evaluation system of PPTC at \url{https://github.com/gydpku/PPTC}.
EIPE-text: Evaluation-Guided Iterative Plan Extraction for Long-Form Narrative Text Generation
Oct 12, 2023



Plan-and-Write is a common hierarchical approach in long-form narrative text generation, which first creates a plan to guide the narrative writing. Following this approach, several studies rely on simply prompting large language models for planning, which often yields suboptimal results. In this paper, we propose a new framework called Evaluation-guided Iterative Plan Extraction for long-form narrative text generation (EIPE-text), which extracts plans from the corpus of narratives and utilizes the extracted plans to construct a better planner. EIPE-text has three stages: plan extraction, learning, and inference. In the plan extraction stage, it iteratively extracts and improves plans from the narrative corpus and constructs a plan corpus. We propose a question answer (QA) based evaluation mechanism to automatically evaluate the plans and generate detailed plan refinement instructions to guide the iterative improvement. In the learning stage, we build a better planner by fine-tuning with the plan corpus or in-context learning with examples in the plan corpus. Finally, we leverage a hierarchical approach to generate long-form narratives. We evaluate the effectiveness of EIPE-text in the domains of novels and storytelling. Both GPT-4-based evaluations and human evaluations demonstrate that our method can generate more coherent and relevant long-form narratives. Our code will be released in the future.
GameEval: Evaluating LLMs on Conversational Games
Aug 19, 2023The rapid advancements in large language models (LLMs) have presented challenges in evaluating those models. Existing evaluation methods are either reference-based or preference based, which inevitably need human intervention or introduce test bias caused by evaluator models. In this paper, we propose GameEval, a novel approach to evaluating LLMs through goal-driven conversational games, overcoming the limitations of previous methods. GameEval treats LLMs as game players and assigns them distinct roles with specific goals achieved by launching conversations of various forms, including discussion, question answering, and voting. We design three unique games with cooperative or adversarial objectives, accompanied by corresponding evaluation metrics, to show how this new paradigm comprehensively evaluates model performance.Through extensive experiments, we show that GameEval can effectively differentiate the capabilities of various LLMs, providing a comprehensive assessment of their integrated abilities to solve complex problems. Our public anonymous code is available at https://github.com/GameEval/GameEval.