 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
SVBench: Evaluation of Video Generation Models on Social Reasoning
Dec 25, 2025Recent text-to-video generation models exhibit remarkable progress in visual realism, motion fidelity, and text-video alignment, yet they remain fundamentally limited in their ability to generate socially coherent behavior. Unlike humans, who effortlessly infer intentions, beliefs, emotions, and social norms from brief visual cues, current models tend to render literal scenes without capturing the underlying causal or psychological logic. To systematically evaluate this gap, we introduce the first benchmark for social reasoning in video generation. Grounded in findings from developmental and social psychology, our benchmark organizes thirty classic social cognition paradigms into seven core dimensions, including mental-state inference, goal-directed action, joint attention, social coordination, prosocial behavior, social norms, and multi-agent strategy. To operationalize these paradigms, we develop a fully training-free agent-based pipeline that (i) distills the reasoning mechanism of each experiment, (ii) synthesizes diverse video-ready scenarios, (iii) enforces conceptual neutrality and difficulty control through cue-based critique, and (iv) evaluates generated videos using a high-capacity VLM judge across five interpretable dimensions of social reasoning. Using this framework, we conduct the first large-scale study across seven state-of-the-art video generation systems. Our results reveal substantial performance gaps: while modern models excel in surface-level plausibility, they systematically fail in intention recognition, belief reasoning, joint attention, and prosocial inference.
RLRF4Rec: Reinforcement Learning from Recsys Feedback for Enhanced Recommendation Reranking
Oct 08, 2024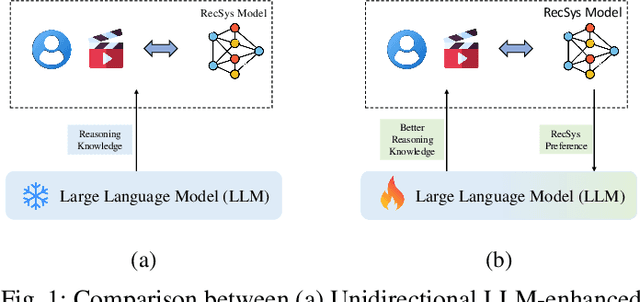



Large Language Models (LLMs) have demonstrated remarkable performance across diverse domains, prompting researchers to explore their potential for use in recommendation systems. Initial attempts have leveraged the exceptional capabilities of LLMs, such as rich knowledge and strong generalization through In-context Learning, which involves phrasing the recommendation task as prompts. Nevertheless, the performance of LLMs in recommendation tasks remains suboptimal due to a substantial disparity between the training tasks for LLMs and recommendation tasks and inadequate recommendation data during pre-training. This paper introduces RLRF4Rec, a novel framework integrating Reinforcement Learning from Recsys Feedback for Enhanced Recommendation Reranking(RLRF4Rec) with LLMs to address these challenges. Specifically, We first have the LLM generate inferred user preferences based on user interaction history, which is then used to augment traditional ID-based sequence recommendation models. Subsequently, we trained a reward model based on knowledge augmentation recommendation models to evaluate the quality of the reasoning knowledge from LLM. We then select the best and worst responses from the N samples to construct a dataset for LLM tuning. Finally, we design a structure alignment strategy with Direct Preference Optimization(DPO). We validate the effectiveness of RLRF4Rec through extensive experiments, demonstrating significant improvements in recommendation re-ranking metrics compared to baselines. This demonstrates that our approach significantly improves the capability of LLMs to respond to instructions within recommender systems.
You Can't Ignore Either: Unifying Structure and Feature Denoising for Robust Graph Learning
Aug 01, 2024Recent research on the robustness of Graph Neural Networks (GNNs) under noises or attacks has attracted great attention due to its importance in real-world applications. Most previous methods explore a single noise source, recovering corrupt node embedding by reliable structures bias or developing structure learning with reliable node features. However, the noises and attacks may come from both structures and features in graphs, making the graph denoising a dilemma and challenging problem. In this paper, we develop a unified graph denoising (UGD) framework to unravel the deadlock between structure and feature denoising. Specifically, a high-order neighborhood proximity evaluation method is proposed to recognize noisy edges, considering features may be perturbed simultaneously. Moreover, we propose to refine noisy features with reconstruction based on a graph auto-encoder. An iterative updating algorithm is further designed to optimize the framework and acquire a clean graph, thus enabling robust graph learning for downstream tasks. Our UGD framework is self-supervised and can be easily implemented as a plug-and-play module. We carry out extensive experiments, which proves the effectiveness and advantages of our method. Code is avalaible at https://github.com/YoungTimmy/UGD.
SEFraud: Graph-based Self-Explainable Fraud Detection via Interpretative Mask Learning
Jun 17, 2024



Graph-based fraud detection has widespread application in modern industry scenarios, such as spam review and malicious account detection. While considerable efforts have been devoted to designing adequate fraud detectors, the interpretability of their results has often been overlooked. Previous works have attempted to generate explanations for specific instances using post-hoc explaining methods such as a GNNExplainer. However, post-hoc explanations can not facilitate the model predictions and the computational cost of these methods cannot meet practical requirements, thus limiting their application in real-world scenarios. To address these issues, we propose SEFraud, a novel graph-based self-explainable fraud detection framework that simultaneously tackles fraud detection and result in interpretability. Concretely, SEFraud first leverages customized heterogeneous graph transformer networks with learnable feature masks and edge masks to learn expressive representations from the informative heterogeneously typed transactions. A new triplet loss is further designed to enhance the performance of mask learning. Empirical results on various datasets demonstrate the effectiveness of SEFraud as it shows considerable advantages in both the fraud detection performance and interpretability of prediction results. Moreover, SEFraud has been deployed and offers explainable fraud detection service for the largest bank in China, Industrial and Commercial Bank of China Limited (ICBC). Results collected from the production environment of ICBC show that SEFraud can provide accurate detection results and comprehensive explanations that align with the expert business understanding, confirming its efficiency and applicability in large-scale online services.
Mitigating Semantic Confusion from Hostile Neighborhood for Graph Active Learning
Aug 17, 2023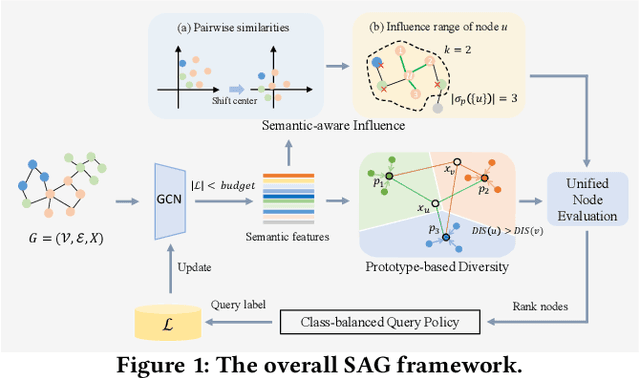

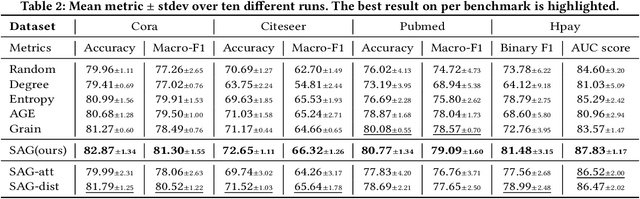
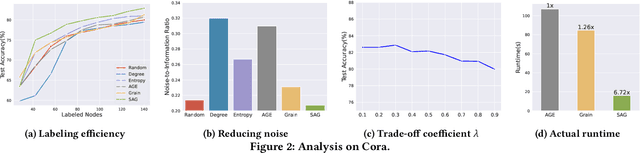
Graph Active Learning (GAL), which aims to find the most informative nodes in graphs for annotation to maximize the Graph Neural Networks (GNNs) performance, has attracted many research efforts but remains non-trivial challenges. One major challenge is that existing GAL strategies may introduce semantic confusion to the selected training set, particularly when graphs are noisy. Specifically, most existing methods assume all aggregating features to be helpful, ignoring the semantically negative effect between inter-class edges under the message-passing mechanism. In this work, we present Semantic-aware Active learning framework for Graphs (SAG) to mitigate the semantic confusion problem. Pairwise similarities and dissimilarities of nodes with semantic features are introduced to jointly evaluate the node influence. A new prototype-based criterion and query policy are also designed to maintain diversity and class balance of the selected nodes, respectively. Extensive experiments on the public benchmark graphs and a real-world financial dataset demonstrate that SAG significantly improves node classification performances and consistently outperforms previous methods. Moreover, comprehensive analysis and ablation study also verify the effectiveness of the proposed framework.
Graph Pointer Neural Networks
Oct 03, 2021
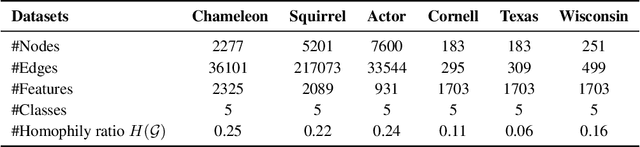

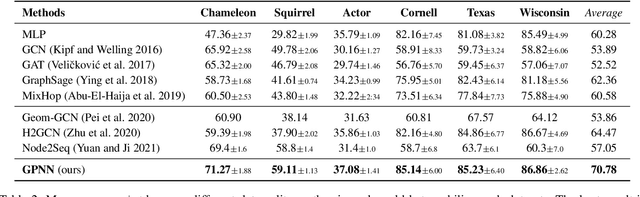
Graph Neural Networks (GNNs) have shown advantages in various graph-based applications. Most existing GNNs assume strong homophily of graph structure and apply permutation-invariant local aggregation of neighbors to learn a representation for each node. However, they fail to generalize to heterophilic graphs, where most neighboring nodes have different labels or features, and the relevant nodes are distant. Few recent studies attempt to address this problem by combining multiple hops of hidden representations of central nodes (i.e., multi-hop-based approaches) or sorting the neighboring nodes based on attention scores (i.e., ranking-based approaches). As a result, these approaches have some apparent limitations. On the one hand, multi-hop-based approaches do not explicitly distinguish relevant nodes from a large number of multi-hop neighborhoods, leading to a severe over-smoothing problem. On the other hand, ranking-based models do not joint-optimize node ranking with end tasks and result in sub-optimal solutions. In this work, we present Graph Pointer Neural Networks (GPNN) to tackle the challenges mentioned above. We leverage a pointer network to select the most relevant nodes from a large amount of multi-hop neighborhoods, which constructs an ordered sequence according to the relationship with the central node. 1D convolution is then applied to extract high-level features from the node sequence. The pointer-network-based ranker in GPNN is joint-optimized with other parts in an end-to-end manner. Extensive experiments are conducted on six public node classification datasets with heterophilic graphs. The results show that GPNN significantly improves the classification performance of state-of-the-art methods. In addition, analyses also reveal the privilege of the proposed GPNN in filtering out irrelevant neighbors and reducing over-smoothing.
Learning Timestamp-Level Representations for Time Series with Hierarchical Contrastive Loss
Jun 19, 2021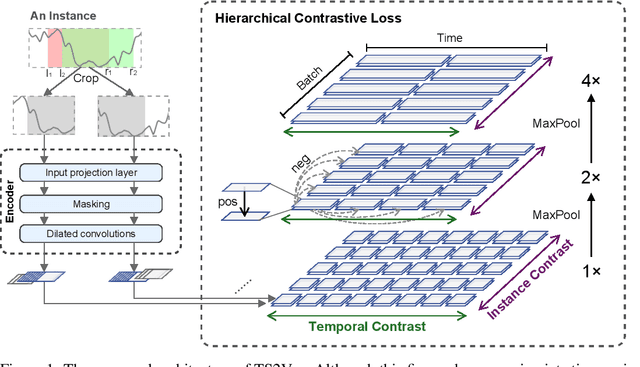

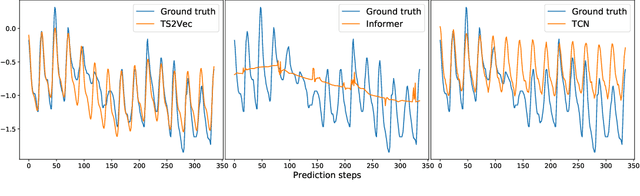
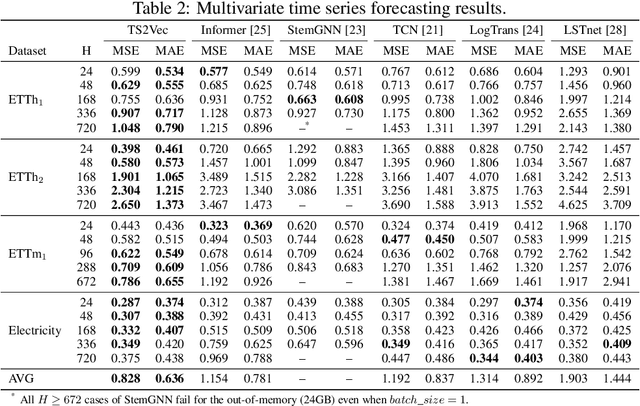
This paper presents TS2Vec, a universal framework for learning timestamp-level representations of time series. Unlike existing methods, TS2Vec performs timestamp-wise discrimination, which learns a contextual representation vector directly for each timestamp. We find that the learned representations have superior predictive ability. A linear regression trained on top of the learned representations outperforms previous SOTAs for supervised time series forecasting. Also, the instance-level representations can be simply obtained by applying a max pooling layer on top of learned representations of all timestamps. We conduct extensive experiments on time series classification tasks to evaluate the quality of instance-level representations. As a result, TS2Vec achieves significant improvement compared with existing SOTAs of unsupervised time series representation on 125 UCR datasets and 29 UEA datasets. The source code is publicly available at https://github.com/yuezhihan/ts2vec.