 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFAN, a transformer-based deep learning model for human-artificial intelligence collaborative assessment of incidental pulmonary nodules in CT scans: a multi-reader, multi-case trial
Mar 26, 2026The widespread adoption of CT has notably increased the number of detected lung nodules. However, current deep learning methods for classifying benign and malignant nodules often fail to comprehensively integrate global and local features, and most of them have not been validated through clinical trials. To address this, we developed DeepFAN, a transformer-based model trained on over 10K pathology-confirmed nodules and further conducted a multi-reader, multi-case clinical trial to evaluate its efficacy in assisting junior radiologists. DeepFAN achieved diagnostic area under the curve (AUC) of 0.939 (95% CI 0.930-0.948) on an internal test set and 0.954 (95% CI 0.934-0.973) on the clinical trial dataset involving 400 cases across three independent medical institutions. Explainability analysis indicated higher contributions from global than local features. Twelve readers' average performance significantly improved by 10.9% (95% CI 8.3%-13.5%) in AUC, 10.0% (95% CI 8.9%-11.1%) in accuracy, 7.6% (95% CI 6.1%-9.2%) in sensitivity, and 12.6% (95% CI 10.9%-14.3%) in specificity (P<0.001 for all). Nodule-level inter-reader diagnostic consistency improved from fair to moderate (overall k: 0.313 vs. 0.421; P=0.019). In conclusion, DeepFAN effectively assisted junior radiologists and may help homogenize diagnostic quality and reduce unnecessary follow-up of indeterminate pulmonary nodules. Chinese Clinical Trial Registry: ChiCTR2400084624.
HeatV2X: Scalable Heterogeneous Collaborative Perception via Efficient Alignment and Interaction
Nov 13, 2025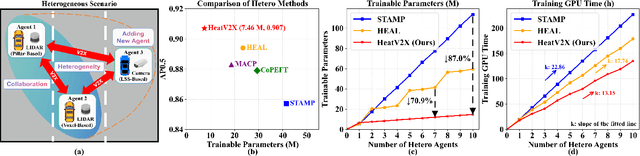
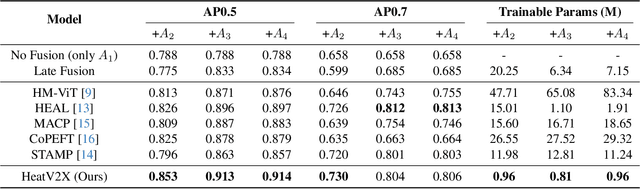
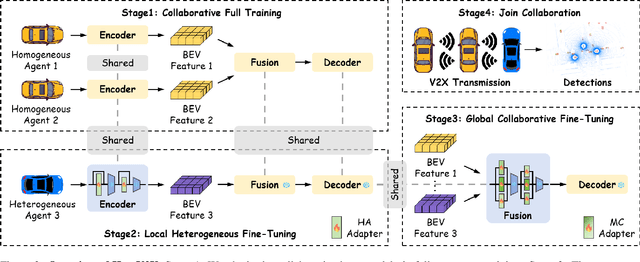
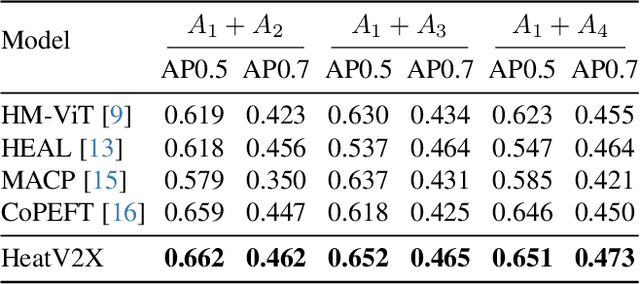
Vehicle-to-Everything (V2X) collaborative perception extends sensing beyond single vehicle limits through transmission. However, as more agents participate, existing frameworks face two key challenges: (1) the participating agents are inherently multi-modal and heterogeneous, and (2) the collaborative framework must be scalable to accommodate new agents. The former requires effective cross-agent feature alignment to mitigate heterogeneity loss, while the latter renders full-parameter training impractical, highlighting the importance of scalable adaptation. To address these issues, we propose Heterogeneous Adaptation (HeatV2X), a scalable collaborative framework. We first train a high-performance agent based on heterogeneous graph attention as the foundation for collaborative learning. Then, we design Local Heterogeneous Fine-Tuning and Global Collaborative Fine-Tuning to achieve effective alignment and interaction among heterogeneous agents. The former efficiently extracts modality-specific differences using Hetero-Aware Adapters, while the latter employs the Multi-Cognitive Adapter to enhance cross-agent collaboration and fully exploit the fusion potential. These designs enable substantial performance improvement of the collaborative framework with minimal training cost. We evaluate our approach on the OPV2V-H and DAIR-V2X datasets. Experimental results demonstrate that our method achieves superior perception performance with significantly reduced training overhead, outperforming existing state-of-the-art approaches. Our implementation will be released soon.
Conditional Representation Learning for Customized Tasks
Oct 06, 2025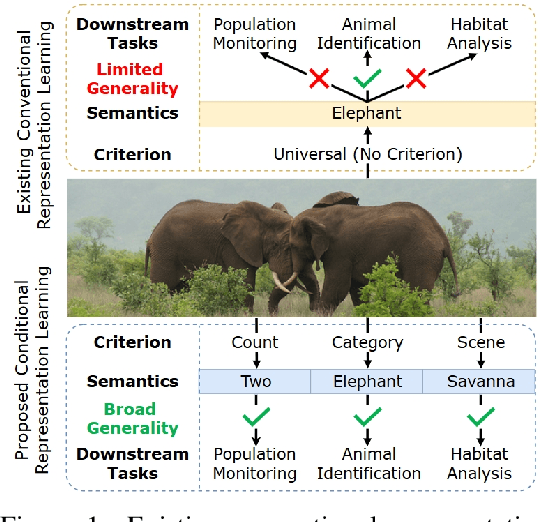

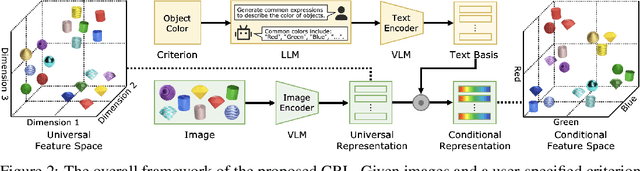
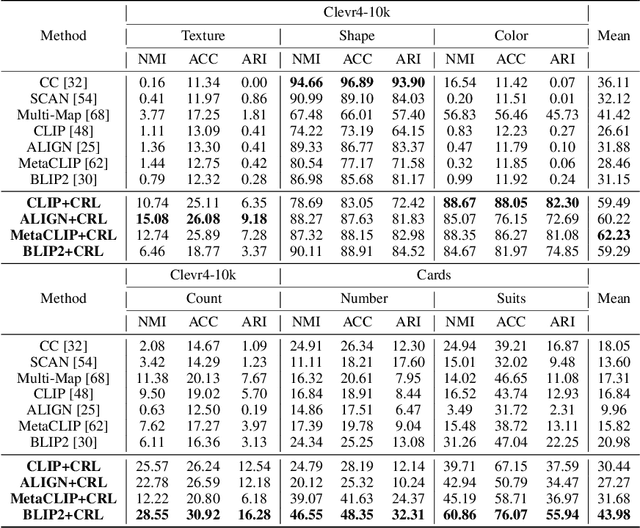
Conventional representation learning methods learn a universal representation that primarily captures dominant semantics, which may not always align with customized downstream tasks. For instance, in animal habitat analysis, researchers prioritize scene-related features, whereas universal embeddings emphasize categorical semantics, leading to suboptimal results. As a solution, existing approaches resort to supervised fine-tuning, which however incurs high computational and annotation costs. In this paper, we propose Conditional Representation Learning (CRL), aiming to extract representations tailored to arbitrary user-specified criteria. Specifically, we reveal that the semantics of a space are determined by its basis, thereby enabling a set of descriptive words to approximate the basis for a customized feature space. Building upon this insight, given a user-specified criterion, CRL first employs a large language model (LLM) to generate descriptive texts to construct the semantic basis, then projects the image representation into this conditional feature space leveraging a vision-language model (VLM). The conditional representation better captures semantics for the specific criterion, which could be utilized for multiple customized tasks. Extensive experiments on classification and retrieval tasks demonstrate the superiority and generality of the proposed CRL. The code is available at https://github.com/XLearning-SCU/2025-NeurIPS-CRL.
PillarMamba: Learning Local-Global Context for Roadside Point Cloud via Hybrid State Space Model
May 08, 2025Serving the Intelligent Transport System (ITS) and Vehicle-to-Everything (V2X) tasks, roadside perception has received increasing attention in recent years, as it can extend the perception range of connected vehicles and improve traffic safety. However, roadside point cloud oriented 3D object detection has not been effectively explored. To some extent, the key to the performance of a point cloud detector lies in the receptive field of the network and the ability to effectively utilize the scene context. The recent emergence of Mamba, based on State Space Model (SSM), has shaken up the traditional convolution and transformers that have long been the foundational building blocks, due to its efficient global receptive field. In this work, we introduce Mamba to pillar-based roadside point cloud perception and propose a framework based on Cross-stage State-space Group (CSG), called PillarMamba. It enhances the expressiveness of the network and achieves efficient computation through cross-stage feature fusion. However, due to the limitations of scan directions, state space model faces local connection disrupted and historical relationship forgotten. To address this, we propose the Hybrid State-space Block (HSB) to obtain the local-global context of roadside point cloud. Specifically, it enhances neighborhood connections through local convolution and preserves historical memory through residual attention. The proposed method outperforms the state-of-the-art methods on the popular large scale roadside benchmark: DAIR-V2X-I. The code will be released soon.
HeightFormer: Learning Height Prediction in Voxel Features for Roadside Vision Centric 3D Object Detection via Transformer
Mar 13, 2025
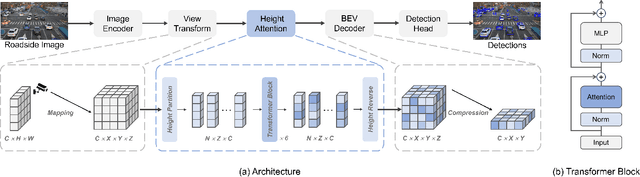


Roadside vision centric 3D object detection has received increasing attention in recent years. It expands the perception range of autonomous vehicles, enhances the road safety. Previous methods focused on predicting per-pixel height rather than depth, making significant gains in roadside visual perception. While it is limited by the perspective property of near-large and far-small on image features, making it difficult for network to understand real dimension of objects in the 3D world. BEV features and voxel features present the real distribution of objects in 3D world compared to the image features. However, BEV features tend to lose details due to the lack of explicit height information, and voxel features are computationally expensive. Inspired by this insight, an efficient framework learning height prediction in voxel features via transformer is proposed, dubbed HeightFormer. It groups the voxel features into local height sequences, and utilize attention mechanism to obtain height distribution prediction. Subsequently, the local height sequences are reassembled to generate accurate 3D features. The proposed method is applied to two large-scale roadside benchmarks, DAIR-V2X-I and Rope3D. Extensive experiments are performed and the HeightFormer outperforms the state-of-the-art methods in roadside vision centric 3D object detection task.
Semantic Scene Completion Based 3D Traversability Estimation for Off-Road Terrains
Dec 11, 2024Off-road environments present significant challenges for autonomous ground vehicles due to the absence of structured roads and the presence of complex obstacles, such as uneven terrain, vegetation, and occlusions. Traditional perception algorithms, designed primarily for structured environments, often fail under these conditions, leading to inaccurate traversability estimations. In this paper, ORDformer, a novel multimodal method that combines LiDAR point clouds with monocular images, is proposed to generate dense traversable occupancy predictions from a forward-facing perspective. By integrating multimodal data, environmental feature extraction is enhanced, which is crucial for accurate occupancy estimation in complex terrains. Furthermore, RELLIS-OCC, a dataset with 3D traversable occupancy annotations, is introduced, incorporating geometric features such as step height, slope, and unevenness. Through a comprehensive analysis of vehicle obstacle-crossing conditions and the incorporation of vehicle body structure constraints, four traversability cost labels are generated: lethal, medium-cost, low-cost, and free. Experimental results demonstrate that ORDformer outperforms existing approaches in 3D traversable area recognition, particularly in off-road environments with irregular geometries and partial occlusions. Specifically, ORDformer achieves over a 20\% improvement in scene completion IoU compared to other models. The proposed framework is scalable and adaptable to various vehicle platforms, allowing for adjustments to occupancy grid parameters and the integration of advanced dynamic models for traversability cost estimation.
RLRF4Rec: Reinforcement Learning from Recsys Feedback for Enhanced Recommendation Reranking
Oct 08, 2024



Large Language Models (LLMs) have demonstrated remarkable performance across diverse domains, prompting researchers to explore their potential for use in recommendation systems. Initial attempts have leveraged the exceptional capabilities of LLMs, such as rich knowledge and strong generalization through In-context Learning, which involves phrasing the recommendation task as prompts. Nevertheless, the performance of LLMs in recommendation tasks remains suboptimal due to a substantial disparity between the training tasks for LLMs and recommendation tasks and inadequate recommendation data during pre-training. This paper introduces RLRF4Rec, a novel framework integrating Reinforcement Learning from Recsys Feedback for Enhanced Recommendation Reranking(RLRF4Rec) with LLMs to address these challenges. Specifically, We first have the LLM generate inferred user preferences based on user interaction history, which is then used to augment traditional ID-based sequence recommendation models. Subsequently, we trained a reward model based on knowledge augmentation recommendation models to evaluate the quality of the reasoning knowledge from LLM. We then select the best and worst responses from the N samples to construct a dataset for LLM tuning. Finally, we design a structure alignment strategy with Direct Preference Optimization(DPO). We validate the effectiveness of RLRF4Rec through extensive experiments, demonstrating significant improvements in recommendation re-ranking metrics compared to baselines. This demonstrates that our approach significantly improves the capability of LLMs to respond to instructions within recommender systems.
Utilizing Large Language Models for Named Entity Recognition in Traditional Chinese Medicine against COVID-19 Literature: Comparative Study
Aug 24, 2024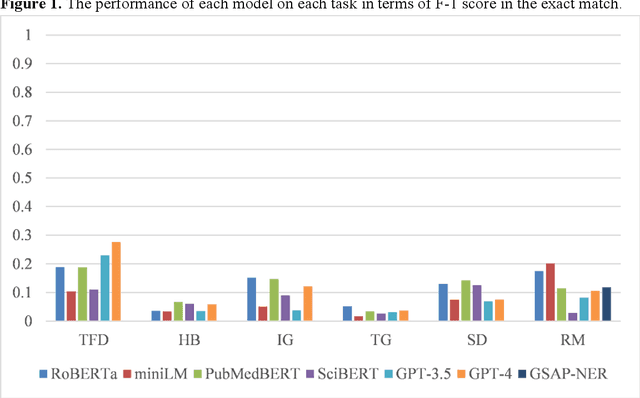
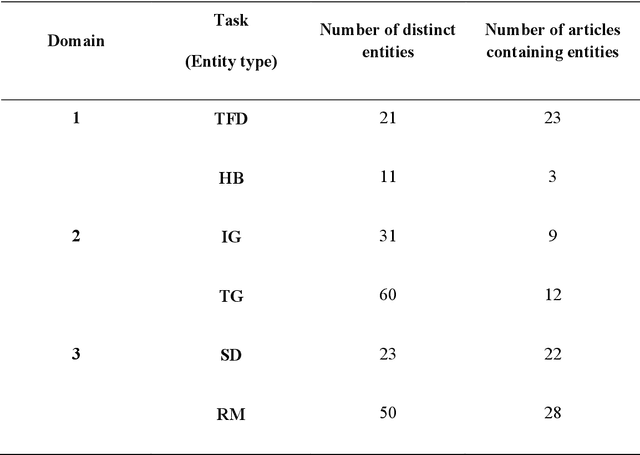
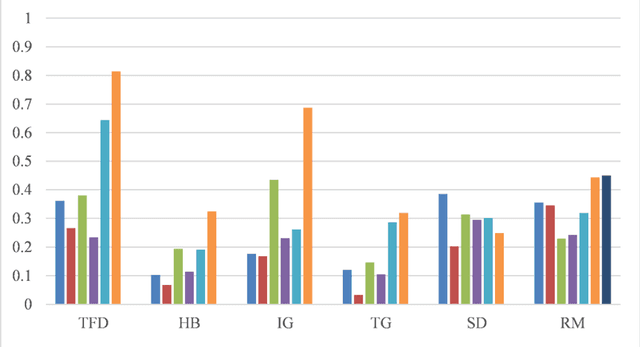
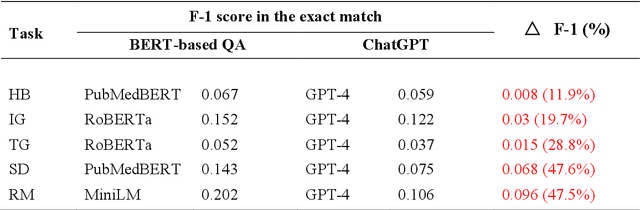
Objective: To explore and compare the performance of ChatGPT and other state-of-the-art LLMs on domain-specific NER tasks covering different entity types and domains in TCM against COVID-19 literature. Methods: We established a dataset of 389 articles on TCM against COVID-19, and manually annotated 48 of them with 6 types of entities belonging to 3 domains as the ground truth, against which the NER performance of LLMs can be assessed. We then performed NER tasks for the 6 entity types using ChatGPT (GPT-3.5 and GPT-4) and 4 state-of-the-art BERT-based question-answering (QA) models (RoBERTa, MiniLM, PubMedBERT and SciBERT) without prior training on the specific task. A domain fine-tuned model (GSAP-NER) was also applied for a comprehensive comparison. Results: The overall performance of LLMs varied significantly in exact match and fuzzy match. In the fuzzy match, ChatGPT surpassed BERT-based QA models in 5 out of 6 tasks, while in exact match, BERT-based QA models outperformed ChatGPT in 5 out of 6 tasks but with a smaller F-1 difference. GPT-4 showed a significant advantage over other models in fuzzy match, especially on the entity type of TCM formula and the Chinese patent drug (TFD) and ingredient (IG). Although GPT-4 outperformed BERT-based models on entity type of herb, target, and research method, none of the F-1 scores exceeded 0.5. GSAP-NER, outperformed GPT-4 in terms of F-1 by a slight margin on RM. ChatGPT achieved considerably higher recalls than precisions, particularly in the fuzzy match. Conclusions: The NER performance of LLMs is highly dependent on the entity type, and their performance varies across application scenarios. ChatGPT could be a good choice for scenarios where high recall is favored. However, for knowledge acquisition in rigorous scenarios, neither ChatGPT nor BERT-based QA models are off-the-shelf tools for professional practitioners.
Leveraging Temporal Contexts to Enhance Vehicle-Infrastructure Cooperative Perception
Aug 20, 2024Infrastructure sensors installed at elevated positions offer a broader perception range and encounter fewer occlusions. Integrating both infrastructure and ego-vehicle data through V2X communication, known as vehicle-infrastructure cooperation, has shown considerable advantages in enhancing perception capabilities and addressing corner cases encountered in single-vehicle autonomous driving. However, cooperative perception still faces numerous challenges, including limited communication bandwidth and practical communication interruptions. In this paper, we propose CTCE, a novel framework for cooperative 3D object detection. This framework transmits queries with temporal contexts enhancement, effectively balancing transmission efficiency and performance to accommodate real-world communication conditions. Additionally, we propose a temporal-guided fusion module to further improve performance. The roadside temporal enhancement and vehicle-side spatial-temporal fusion together constitute a multi-level temporal contexts integration mechanism, fully leveraging temporal information to enhance performance. Furthermore, a motion-aware reconstruction module is introduced to recover lost roadside queries due to communication interruptions. Experimental results on V2X-Seq and V2X-Sim datasets demonstrate that CTCE outperforms the baseline QUEST, achieving improvements of 3.8% and 1.3% in mAP, respectively. Experiments under communication interruption conditions validate CTCE's robustness to communication interruptions.
Human Detection in Realistic Through-the-Wall Environments using Raw Radar ADC Data and Parametric Neural Networks
Mar 20, 2024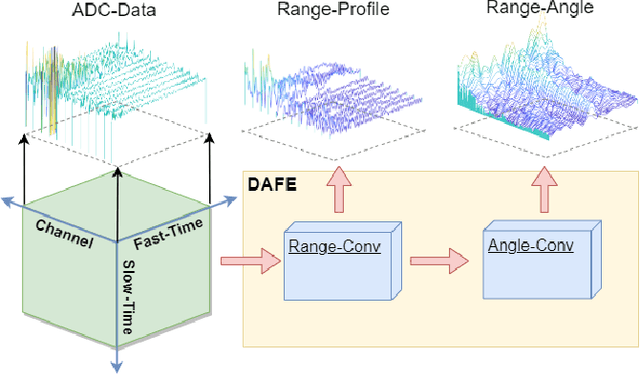
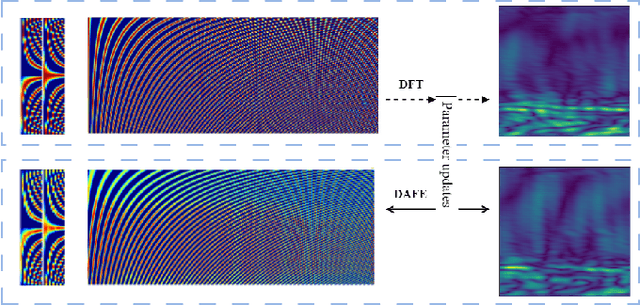
The radar signal processing algorithm is one of the core components in through-wall radar human detection technology. Traditional algorithms (e.g., DFT and matched filtering) struggle to adaptively handle low signal-to-noise ratio echo signals in challenging and dynamic real-world through-wall application environments, which becomes a major bottleneck in the system. In this paper, we introduce an end-to-end through-wall radar human detection network (TWP-CNN), which takes raw radar Analog-to-Digital Converter (ADC) signals without any preprocessing as input. We replace the conventional radar signal processing flow with the proposed DFT-based adaptive feature extraction (DAFE) module. This module employs learnable parameterized 3D complex convolution layers to extract superior feature representations from ADC signals, which is beyond the limitation of traditional preprocessing methods. Additionally, by embedding phase information from radar data within the network and employing multi-task learning, a more accurate detection is achieved. Finally, due to the absence of through-wall radar datasets containing raw ADC data, we gathered a realistic through-wall (RTW) dataset using our in-house developed through-wall radar system. We trained and validated our proposed method on this dataset to confirm its effectiveness and superiority in real through-wall detection scenarios.