 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Single-Granularity Prompts: A Multi-Scale Chain-of-Thought Prompt Learning for Graph
Oct 10, 2025The "pre-train, prompt'' paradigm, designed to bridge the gap between pre-training tasks and downstream objectives, has been extended from the NLP domain to the graph domain and has achieved remarkable progress. Current mainstream graph prompt-tuning methods modify input or output features using learnable prompt vectors. However, existing approaches are confined to single-granularity (e.g., node-level or subgraph-level) during prompt generation, overlooking the inherently multi-scale structural information in graph data, which limits the diversity of prompt semantics. To address this issue, we pioneer the integration of multi-scale information into graph prompt and propose a Multi-Scale Graph Chain-of-Thought (MSGCOT) prompting framework. Specifically, we design a lightweight, low-rank coarsening network to efficiently capture multi-scale structural features as hierarchical basis vectors for prompt generation. Subsequently, mimicking human cognition from coarse-to-fine granularity, we dynamically integrate multi-scale information at each reasoning step, forming a progressive coarse-to-fine prompt chain. Extensive experiments on eight benchmark datasets demonstrate that MSGCOT outperforms the state-of-the-art single-granularity graph prompt-tuning method, particularly in few-shot scenarios, showcasing superior performance.
Enhancing Homophily-Heterophily Separation: Relation-Aware Learning in Heterogeneous Graphs
Jun 26, 2025Real-world networks usually have a property of node heterophily, that is, the connected nodes usually have different features or different labels. This heterophily issue has been extensively studied in homogeneous graphs but remains under-explored in heterogeneous graphs, where there are multiple types of nodes and edges. Capturing node heterophily in heterogeneous graphs is very challenging since both node/edge heterogeneity and node heterophily should be carefully taken into consideration. Existing methods typically convert heterogeneous graphs into homogeneous ones to learn node heterophily, which will inevitably lose the potential heterophily conveyed by heterogeneous relations. To bridge this gap, we propose Relation-Aware Separation of Homophily and Heterophily (RASH), a novel contrastive learning framework that explicitly models high-order semantics of heterogeneous interactions and adaptively separates homophilic and heterophilic patterns. Particularly, RASH introduces dual heterogeneous hypergraphs to encode multi-relational bipartite subgraphs and dynamically constructs homophilic graphs and heterophilic graphs based on relation importance. A multi-relation contrastive loss is designed to align heterogeneous and homophilic/heterophilic views by maximizing mutual information. In this way, RASH simultaneously resolves the challenges of heterogeneity and heterophily in heterogeneous graphs. Extensive experiments on benchmark datasets demonstrate the effectiveness of RASH across various downstream tasks. The code is available at: https://github.com/zhengziyu77/RASH.
Discrepancy-Aware Graph Mask Auto-Encoder
Jun 24, 2025
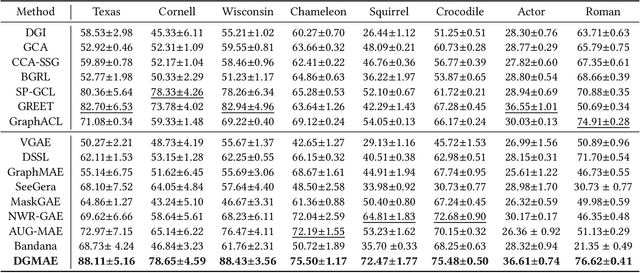
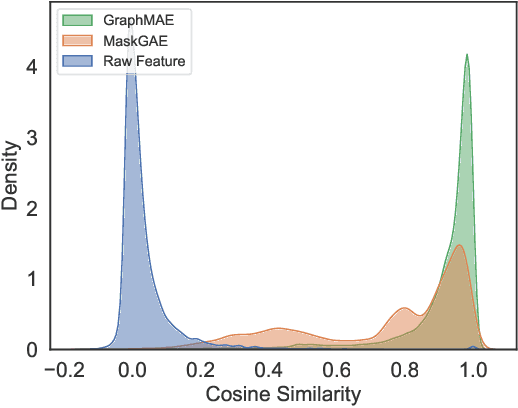
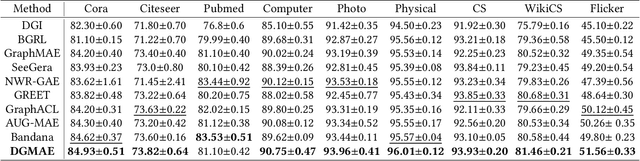
Masked Graph Auto-Encoder, a powerful graph self-supervised training paradigm, has recently shown superior performance in graph representation learning. Existing works typically rely on node contextual information to recover the masked information. However, they fail to generalize well to heterophilic graphs where connected nodes may be not similar, because they focus only on capturing the neighborhood information and ignoring the discrepancy information between different nodes, resulting in indistinguishable node representations. In this paper, to address this issue, we propose a Discrepancy-Aware Graph Mask Auto-Encoder (DGMAE). It obtains more distinguishable node representations by reconstructing the discrepancy information of neighboring nodes during the masking process. We conduct extensive experiments on 17 widely-used benchmark datasets. The results show that our DGMAE can effectively preserve the discrepancies of nodes in low-dimensional space. Moreover, DGMAE significantly outperforms state-of-the-art graph self-supervised learning methods on three graph analytic including tasks node classification, node clustering, and graph classification, demonstrating its remarkable superiority. The code of DGMAE is available at https://github.com/zhengziyu77/DGMAE.
AGMixup: Adaptive Graph Mixup for Semi-supervised Node Classification
Dec 11, 2024



Mixup is a data augmentation technique that enhances model generalization by interpolating between data points using a mixing ratio $\lambda$ in the image domain. Recently, the concept of mixup has been adapted to the graph domain through node-centric interpolations. However, these approaches often fail to address the complexity of interconnected relationships, potentially damaging the graph's natural topology and undermining node interactions. Furthermore, current graph mixup methods employ a one-size-fits-all strategy with a randomly sampled $\lambda$ for all mixup pairs, ignoring the diverse needs of different pairs. This paper proposes an Adaptive Graph Mixup (AGMixup) framework for semi-supervised node classification. AGMixup introduces a subgraph-centric approach, which treats each subgraph similarly to how images are handled in Euclidean domains, thus facilitating a more natural integration of mixup into graph-based learning. We also propose an adaptive mechanism to tune the mixing ratio $\lambda$ for diverse mixup pairs, guided by the contextual similarity and uncertainty of the involved subgraphs. Extensive experiments across seven datasets on semi-supervised node classification benchmarks demonstrate AGMixup's superiority over state-of-the-art graph mixup methods. Source codes are available at \url{https://github.com/WeigangLu/AGMixup}.
* Accepted by AAAI 2025
StreamAdapter: Efficient Test Time Adaptation from Contextual Streams
Nov 14, 2024



In-context learning (ICL) allows large language models (LLMs) to adapt to new tasks directly from the given demonstrations without requiring gradient updates. While recent advances have expanded context windows to accommodate more demonstrations, this approach increases inference costs without necessarily improving performance. To mitigate these issues, We propose StreamAdapter, a novel approach that directly updates model parameters from context at test time, eliminating the need for explicit in-context demonstrations. StreamAdapter employs context mapping and weight absorption mechanisms to dynamically transform ICL demonstrations into parameter updates with minimal additional parameters. By reducing reliance on numerous in-context examples, StreamAdapter significantly reduce inference costs and allows for efficient inference with constant time complexity, regardless of demonstration count. Extensive experiments across diverse tasks and model architectures demonstrate that StreamAdapter achieves comparable or superior adaptation capability to ICL while requiring significantly fewer demonstrations. The superior task adaptation and context encoding capabilities of StreamAdapter on both language understanding and generation tasks provides a new perspective for adapting LLMs at test time using context, allowing for more efficient adaptation across scenarios and more cost-effective inference
Token-level Proximal Policy Optimization for Query Generation
Nov 01, 2024Query generation is a critical task for web search engines (e.g. Google, Bing) and recommendation systems. Recently, state-of-the-art query generation methods leverage Large Language Models (LLMs) for their strong capabilities in context understanding and text generation. However, they still face challenges in generating high-quality queries in terms of inferring user intent based on their web search interaction history. In this paper, we propose Token-level Proximal Policy Optimization (TPPO), a noval approach designed to empower LLMs perform better in query generation through fine-tuning. TPPO is based on the Reinforcement Learning from AI Feedback (RLAIF) paradigm, consisting of a token-level reward model and a token-level proximal policy optimization module to address the sparse reward challenge in traditional RLAIF frameworks. To evaluate the effectiveness and robustness of TPPO, we conducted experiments on both open-source dataset and an industrial dataset that was collected from a globally-used search engine. The experimental results demonstrate that TPPO significantly improves the performance of query generation for LLMs and outperforms its existing competitors.
MTL-LoRA: Low-Rank Adaptation for Multi-Task Learning
Oct 15, 2024



Parameter-efficient fine-tuning (PEFT) has been widely employed for domain adaptation, with LoRA being one of the most prominent methods due to its simplicity and effectiveness. However, in multi-task learning (MTL) scenarios, LoRA tends to obscure the distinction between tasks by projecting sparse high-dimensional features from different tasks into the same dense low-dimensional intrinsic space. This leads to task interference and suboptimal performance for LoRA and its variants. To tackle this challenge, we propose MTL-LoRA, which retains the advantages of low-rank adaptation while significantly enhancing multi-task learning capabilities. MTL-LoRA augments LoRA by incorporating additional task-adaptive parameters that differentiate task-specific information and effectively capture shared knowledge across various tasks within low-dimensional spaces. This approach enables large language models (LLMs) pre-trained on general corpus to adapt to different target task domains with a limited number of trainable parameters. Comprehensive experimental results, including evaluations on public academic benchmarks for natural language understanding, commonsense reasoning, and image-text understanding, as well as real-world industrial text Ads relevance datasets, demonstrate that MTL-LoRA outperforms LoRA and its various variants with comparable or even fewer learnable parameters in multitask learning.
RLRF4Rec: Reinforcement Learning from Recsys Feedback for Enhanced Recommendation Reranking
Oct 08, 2024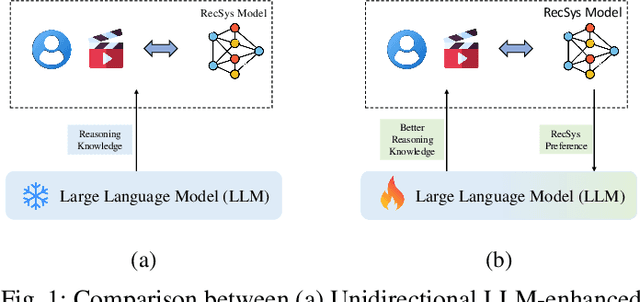



Large Language Models (LLMs) have demonstrated remarkable performance across diverse domains, prompting researchers to explore their potential for use in recommendation systems. Initial attempts have leveraged the exceptional capabilities of LLMs, such as rich knowledge and strong generalization through In-context Learning, which involves phrasing the recommendation task as prompts. Nevertheless, the performance of LLMs in recommendation tasks remains suboptimal due to a substantial disparity between the training tasks for LLMs and recommendation tasks and inadequate recommendation data during pre-training. This paper introduces RLRF4Rec, a novel framework integrating Reinforcement Learning from Recsys Feedback for Enhanced Recommendation Reranking(RLRF4Rec) with LLMs to address these challenges. Specifically, We first have the LLM generate inferred user preferences based on user interaction history, which is then used to augment traditional ID-based sequence recommendation models. Subsequently, we trained a reward model based on knowledge augmentation recommendation models to evaluate the quality of the reasoning knowledge from LLM. We then select the best and worst responses from the N samples to construct a dataset for LLM tuning. Finally, we design a structure alignment strategy with Direct Preference Optimization(DPO). We validate the effectiveness of RLRF4Rec through extensive experiments, demonstrating significant improvements in recommendation re-ranking metrics compared to baselines. This demonstrates that our approach significantly improves the capability of LLMs to respond to instructions within recommender systems.
Aligning Multiple Knowledge Graphs in a Single Pass
Aug 01, 2024



Entity alignment (EA) is to identify equivalent entities across different knowledge graphs (KGs), which can help fuse these KGs into a more comprehensive one. Previous EA methods mainly focus on aligning a pair of KGs, and to the best of our knowledge, no existing EA method considers aligning multiple (more than two) KGs. To fill this research gap, in this work, we study a novel problem of aligning multiple KGs and propose an effective framework named MultiEA to solve the problem. First, we embed the entities of all the candidate KGs into a common feature space by a shared KG encoder. Then, we explore three alignment strategies to minimize the distances among pre-aligned entities. In particular, we propose an innovative inference enhancement technique to improve the alignment performance by incorporating high-order similarities. Finally, to verify the effectiveness of MultiEA, we construct two new real-world benchmark datasets and conduct extensive experiments on them. The results show that our MultiEA can effectively and efficiently align multiple KGs in a single pass.
You Can't Ignore Either: Unifying Structure and Feature Denoising for Robust Graph Learning
Aug 01, 2024Recent research on the robustness of Graph Neural Networks (GNNs) under noises or attacks has attracted great attention due to its importance in real-world applications. Most previous methods explore a single noise source, recovering corrupt node embedding by reliable structures bias or developing structure learning with reliable node features. However, the noises and attacks may come from both structures and features in graphs, making the graph denoising a dilemma and challenging problem. In this paper, we develop a unified graph denoising (UGD) framework to unravel the deadlock between structure and feature denoising. Specifically, a high-order neighborhood proximity evaluation method is proposed to recognize noisy edges, considering features may be perturbed simultaneously. Moreover, we propose to refine noisy features with reconstruction based on a graph auto-encoder. An iterative updating algorithm is further designed to optimize the framework and acquire a clean graph, thus enabling robust graph learning for downstream tasks. Our UGD framework is self-supervised and can be easily implemented as a plug-and-play module. We carry out extensive experiments, which proves the effectiveness and advantages of our method. Code is avalaible at https://github.com/YoungTimmy/UGD.