 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVSpeech: An Integrated and Scalable Pipeline for Human-Like Speech Modeling with Paralinguistic Vocalizations
Aug 06, 2025Paralinguistic vocalizations-including non-verbal sounds like laughter and breathing, as well as lexicalized interjections such as "uhm" and "oh"-are integral to natural spoken communication. Despite their importance in conveying affect, intent, and interactional cues, such cues remain largely overlooked in conventional automatic speech recognition (ASR) and text-to-speech (TTS) systems. We present NVSpeech, an integrated and scalable pipeline that bridges the recognition and synthesis of paralinguistic vocalizations, encompassing dataset construction, ASR modeling, and controllable TTS. (1) We introduce a manually annotated dataset of 48,430 human-spoken utterances with 18 word-level paralinguistic categories. (2) We develop the paralinguistic-aware ASR model, which treats paralinguistic cues as inline decodable tokens (e.g., "You're so funny [Laughter]"), enabling joint lexical and non-verbal transcription. This model is then used to automatically annotate a large corpus, the first large-scale Chinese dataset of 174,179 utterances (573 hours) with word-level alignment and paralingustic cues. (3) We finetune zero-shot TTS models on both human- and auto-labeled data to enable explicit control over paralinguistic vocalizations, allowing context-aware insertion at arbitrary token positions for human-like speech synthesis. By unifying the recognition and generation of paralinguistic vocalizations, NVSpeech offers the first open, large-scale, word-level annotated pipeline for expressive speech modeling in Mandarin, integrating recognition and synthesis in a scalable and controllable manner. Dataset and audio demos are available at https://nvspeech170k.github.io/.
AGMixup: Adaptive Graph Mixup for Semi-supervised Node Classification
Dec 11, 2024



Mixup is a data augmentation technique that enhances model generalization by interpolating between data points using a mixing ratio $\lambda$ in the image domain. Recently, the concept of mixup has been adapted to the graph domain through node-centric interpolations. However, these approaches often fail to address the complexity of interconnected relationships, potentially damaging the graph's natural topology and undermining node interactions. Furthermore, current graph mixup methods employ a one-size-fits-all strategy with a randomly sampled $\lambda$ for all mixup pairs, ignoring the diverse needs of different pairs. This paper proposes an Adaptive Graph Mixup (AGMixup) framework for semi-supervised node classification. AGMixup introduces a subgraph-centric approach, which treats each subgraph similarly to how images are handled in Euclidean domains, thus facilitating a more natural integration of mixup into graph-based learning. We also propose an adaptive mechanism to tune the mixing ratio $\lambda$ for diverse mixup pairs, guided by the contextual similarity and uncertainty of the involved subgraphs. Extensive experiments across seven datasets on semi-supervised node classification benchmarks demonstrate AGMixup's superiority over state-of-the-art graph mixup methods. Source codes are available at \url{https://github.com/WeigangLu/AGMixup}.
* Accepted by AAAI 2025
Entropy Induced Pruning Framework for Convolutional Neural Networks
Aug 13, 2022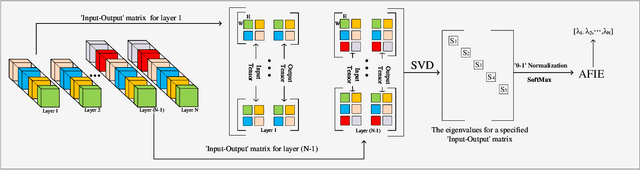
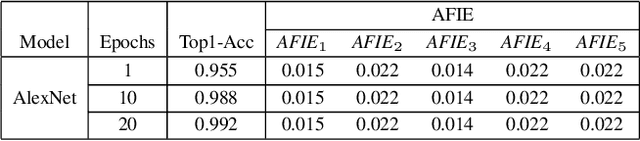
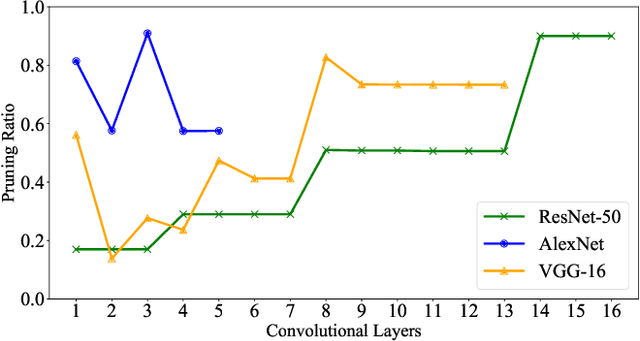

Structured pruning techniques have achieved great compression performance on convolutional neural networks for image classification task. However, the majority of existing methods are weight-oriented, and their pruning results may be unsatisfactory when the original model is trained poorly. That is, a fully-trained model is required to provide useful weight information. This may be time-consuming, and the pruning results are sensitive to the updating process of model parameters. In this paper, we propose a metric named Average Filter Information Entropy (AFIE) to measure the importance of each filter. It is calculated by three major steps, i.e., low-rank decomposition of the "input-output" matrix of each convolutional layer, normalization of the obtained eigenvalues, and calculation of filter importance based on information entropy. By leveraging the proposed AFIE, the proposed framework is able to yield a stable importance evaluation of each filter no matter whether the original model is trained fully. We implement our AFIE based on AlexNet, VGG-16, and ResNet-50, and test them on MNIST, CIFAR-10, and ImageNet, respectively. The experimental results are encouraging. We surprisingly observe that for our methods, even when the original model is only trained with one epoch, the importance evaluation of each filter keeps identical to the results when the model is fully-trained. This indicates that the proposed pruning strategy can perform effectively at the beginning stage of the training process for the original model.
SBPF: Sensitiveness Based Pruning Framework For Convolutional Neural Network On Image Classification
Aug 09, 2022



Pruning techniques are used comprehensively to compress convolutional neural networks (CNNs) on image classification. However, the majority of pruning methods require a well pre-trained model to provide useful supporting parameters, such as C1-norm, BatchNorm value and gradient information, which may lead to inconsistency of filter evaluation if the parameters of the pre-trained model are not well optimized. Therefore, we propose a sensitiveness based method to evaluate the importance of each layer from the perspective of inference accuracy by adding extra damage for the original model. Because the performance of the accuracy is determined by the distribution of parameters across all layers rather than individual parameter, the sensitiveness based method will be robust to update of parameters. Namely, we can obtain similar importance evaluation of each convolutional layer between the imperfect-trained and fully trained models. For VGG-16 on CIFAR-10, even when the original model is only trained with 50 epochs, we can get same evaluation of layer importance as the results when the model is trained fully. Then we will remove filters proportional from each layer by the quantified sensitiveness. Our sensitiveness based pruning framework is verified efficiently on VGG-16, a customized Conv-4 and ResNet-18 with CIFAR-10, MNIST and CIFAR-100, respectively.