 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEviRank: Evidence-Based Confidence Estimation for LLM-Based Ranking
Jun 03, 2026Large Language Models show promise for recommendation, but they raise reliability concerns due to limited domain coverage and inherent stochasticity. Existing uncertainty quantification methods persist two fundamental challenges: (1) the global confidence score designed for question answering fails to reveal which positions are unreliable in ranking list; (2) fine-grained confidence extracted from model internals exhibits uniformly low values across all positions, making it impossible to filter unreliable predictions. To tackle the challenges, we propose an evidence-based confidence estimation for LLM-based ranking (EviRank). We extract three complementary evidences from a single forward pass and aggregate them via reliable opinion aggregation. Furthermore, we recognize that ranking positions are inherently unequal, and introduce a position-aware calibration. Lastly, the calibrated confidence guides ranking optimization. Experiments on three datasets demonstrate that our method achieves state-of-the-art performance on both recommendation and uncertainty quantification.
MDGMIX: Boundary-Aware Subgraph Mixing for Multi-Domain Graph Pre-Training
May 25, 2026Multi-domain graph pre-training is a crucial step in constructing foundational graph models with cross-domain generalization capabilities. However, existing methods predominantly rely on jointly training all source domain graphs, resulting in high computational costs. Furthermore, it remains unclear whether all source domain graph data contribute equally to effective transfer. This paper empirically reveals significant data redundancy in multi-domain graph pre-training. Based on this finding, we propose the Multi-domain Graph Pre-training Framework, MDGMIX, which combines boundary-aware subgraph mixing with hierarchical discrimination. By selecting boundary nodes to construct challenging mixed-domain subgraphs, MDGMIX employs coarse-grained domain discrimination and fine-grained domain decomposition losses to decouple shared patterns from domain-specific patterns. During adaptation, MDGMIX employs a lightweight prompt weighting mechanism to transfer source domain knowledge. Extensive experiments demonstrate that MDGMIX consistently outperforms strong baselines in few-shot classification tasks while exhibiting superior time and memory efficiency. The code is available at: https://github.com/zhengziyu77/MDGMIX.
Are Independently Estimated View Uncertainties Comparable? Unified Routing for Trusted Multi-View Classification
Apr 10, 2026Trusted multi-view classification typically relies on a view-wise evidential fusion process: each view independently produces class evidence and uncertainty, and the final prediction is obtained by aggregating these independent opinions. While this design is modular and uncertainty-aware, it implicitly assumes that evidence from different views is numerically comparable. In practice, however, this assumption is fragile. Different views often differ in feature space, noise level, and semantic granularity, while independently trained branches are optimized only for prediction correctness, without any constraint enforcing cross-view consistency in evidence strength. As a result, the uncertainty used for fusion can be dominated by branch-specific scale bias rather than true sample-level reliability. To address this issue, we propose Trusted Multi-view learning with Unified Routing (TMUR), which decouples view-specific evidence extraction from fusion arbitration. TMUR uses view-private experts and one collaborative expert, and employs a unified router that observes the global multi-view context to generate sample-level expert weights. Soft load-balancing and diversity regularization further encourage balanced expert utilization and more discriminative expert specialization. We also provide theoretical analysis showing why independent evidential supervision does not identify a common cross-view evidence scale, and why unified global routing is preferable to branch-local arbitration when reliability is sample-dependent.
AdaMuS: Adaptive Multi-view Sparsity Learning for Dimensionally Unbalanced Data
Mar 18, 2026Multi-view learning primarily aims to fuse multiple features to describe data comprehensively. Most prior studies implicitly assume that different views share similar dimensions. In practice, however, severe dimensional disparities often exist among different views, leading to the unbalanced multi-view learning issue. For example, in emotion recognition tasks, video frames often reach dimensions of $10^6$, while physiological signals comprise only $10^1$ dimensions. Existing methods typically face two main challenges for this problem: (1) They often bias towards high-dimensional data, overlooking the low-dimensional views. (2) They struggle to effectively align representations under extreme dimensional imbalance, which introduces severe redundancy into the low-dimensional ones. To address these issues, we propose the Adaptive Multi-view Sparsity Learning (AdaMuS) framework. First, to prevent ignoring the information of low-dimensional views, we construct view-specific encoders to map them into a unified dimensional space. Given that mapping low-dimensional data to a high-dimensional space often causes severe overfitting, we design a parameter-free pruning method to adaptively remove redundant parameters in the encoders. Furthermore, we propose a sparse fusion paradigm that flexibly suppresses redundant dimensions and effectively aligns each view. Additionally, to learn representations with stronger generalization, we propose a self-supervised learning paradigm that obtains supervision information by constructing similarity graphs. Extensive evaluations on a synthetic toy dataset and seven real-world benchmarks demonstrate that AdaMuS consistently achieves superior performance and exhibits strong generalization across both classification and semantic segmentation tasks.
Differentiable Geometric Indexing for End-to-End Generative Retrieval
Mar 11, 2026Generative Retrieval (GR) has emerged as a promising paradigm to unify indexing and search within a single probabilistic framework. However, existing approaches suffer from two intrinsic conflicts: (1) an Optimization Blockage, where the non-differentiable nature of discrete indexing creates a gradient blockage, decoupling index construction from the downstream retrieval objective; and (2) a Geometric Conflict, where standard unnormalized inner-product objectives induce norm-inflation instability, causing popular "hub" items to geometrically overshadow relevant long-tail items. To systematically resolve these misalignments, we propose Differentiable Geometric Indexing (DGI). First, to bridge the optimization gap, DGI enforces Operational Unification. It employs Soft Teacher Forcing via Gumbel-Softmax to establish a fully differentiable pathway, combined with Symmetric Weight Sharing to effectively align the quantizer's indexing space with the retriever's decoding space. Second, to restore geometric fidelity, DGI introduces Isotropic Geometric Optimization. We replace inner-product logits with scaled cosine similarity on the unit hypersphere to effectively decouple popularity bias from semantic relevance. Extensive experiments on large-scale industry search datasets and online e-commerce platform demonstrate that DGI outperforms competitive sparse, dense, and generative baselines. Notably, DGI exhibits superior robustness in long-tail scenarios, validating the necessity of harmonizing structural differentiability with geometric isotropy.
Simple Yet Effective Selective Imputation for Incomplete Multi-view Clustering
Dec 11, 2025Incomplete multi-view data, where different views suffer from missing and unbalanced observations, pose significant challenges for clustering. Existing imputation-based methods attempt to estimate missing views to restore data associations, but indiscriminate imputation often introduces noise and bias, especially when the available information is insufficient. Imputation-free methods avoid this risk by relying solely on observed data, but struggle under severe incompleteness due to the lack of cross-view complementarity. To address this issue, we propose Informativeness-based Selective imputation Multi-View Clustering (ISMVC). Our method evaluates the imputation-relevant informativeness of each missing position based on intra-view similarity and cross-view consistency, and selectively imputes only when sufficient support is available. Furthermore, we integrate this selection with a variational autoencoder equipped with a mixture-of-Gaussians prior to learn clustering-friendly latent representations. By performing distribution-level imputation, ISMVC not only stabilizes the aggregation of posterior distributions but also explicitly models imputation uncertainty, enabling robust fusion and preventing overconfident reconstructions. Compared with existing cautious imputation strategies that depend on training dynamics or model feedback, our method is lightweight, data-driven, and model-agnostic. It can be readily integrated into existing IMC models as a plug-in module. Extensive experiments on multiple benchmark datasets under a more realistic and challenging unbalanced missing scenario demonstrate that our method outperforms both imputation-based and imputation-free approaches.
Beyond Single-Granularity Prompts: A Multi-Scale Chain-of-Thought Prompt Learning for Graph
Oct 10, 2025The "pre-train, prompt'' paradigm, designed to bridge the gap between pre-training tasks and downstream objectives, has been extended from the NLP domain to the graph domain and has achieved remarkable progress. Current mainstream graph prompt-tuning methods modify input or output features using learnable prompt vectors. However, existing approaches are confined to single-granularity (e.g., node-level or subgraph-level) during prompt generation, overlooking the inherently multi-scale structural information in graph data, which limits the diversity of prompt semantics. To address this issue, we pioneer the integration of multi-scale information into graph prompt and propose a Multi-Scale Graph Chain-of-Thought (MSGCOT) prompting framework. Specifically, we design a lightweight, low-rank coarsening network to efficiently capture multi-scale structural features as hierarchical basis vectors for prompt generation. Subsequently, mimicking human cognition from coarse-to-fine granularity, we dynamically integrate multi-scale information at each reasoning step, forming a progressive coarse-to-fine prompt chain. Extensive experiments on eight benchmark datasets demonstrate that MSGCOT outperforms the state-of-the-art single-granularity graph prompt-tuning method, particularly in few-shot scenarios, showcasing superior performance.
Gradient Rectification for Robust Calibration under Distribution Shift
Aug 27, 2025Deep neural networks often produce overconfident predictions, undermining their reliability in safety-critical applications. This miscalibration is further exacerbated under distribution shift, where test data deviates from the training distribution due to environmental or acquisition changes. While existing approaches improve calibration through training-time regularization or post-hoc adjustment, their reliance on access to or simulation of target domains limits their practicality in real-world scenarios. In this paper, we propose a novel calibration framework that operates without access to target domain information. From a frequency-domain perspective, we identify that distribution shifts often distort high-frequency visual cues exploited by deep models, and introduce a low-frequency filtering strategy to encourage reliance on domain-invariant features. However, such information loss may degrade In-Distribution (ID) calibration performance. Therefore, we further propose a gradient-based rectification mechanism that enforces ID calibration as a hard constraint during optimization. Experiments on synthetic and real-world shifted datasets, including CIFAR-10/100-C and WILDS, demonstrate that our method significantly improves calibration under distribution shift while maintaining strong in-distribution performance.
Enhancing Homophily-Heterophily Separation: Relation-Aware Learning in Heterogeneous Graphs
Jun 26, 2025Real-world networks usually have a property of node heterophily, that is, the connected nodes usually have different features or different labels. This heterophily issue has been extensively studied in homogeneous graphs but remains under-explored in heterogeneous graphs, where there are multiple types of nodes and edges. Capturing node heterophily in heterogeneous graphs is very challenging since both node/edge heterogeneity and node heterophily should be carefully taken into consideration. Existing methods typically convert heterogeneous graphs into homogeneous ones to learn node heterophily, which will inevitably lose the potential heterophily conveyed by heterogeneous relations. To bridge this gap, we propose Relation-Aware Separation of Homophily and Heterophily (RASH), a novel contrastive learning framework that explicitly models high-order semantics of heterogeneous interactions and adaptively separates homophilic and heterophilic patterns. Particularly, RASH introduces dual heterogeneous hypergraphs to encode multi-relational bipartite subgraphs and dynamically constructs homophilic graphs and heterophilic graphs based on relation importance. A multi-relation contrastive loss is designed to align heterogeneous and homophilic/heterophilic views by maximizing mutual information. In this way, RASH simultaneously resolves the challenges of heterogeneity and heterophily in heterogeneous graphs. Extensive experiments on benchmark datasets demonstrate the effectiveness of RASH across various downstream tasks. The code is available at: https://github.com/zhengziyu77/RASH.
Discrepancy-Aware Graph Mask Auto-Encoder
Jun 24, 2025
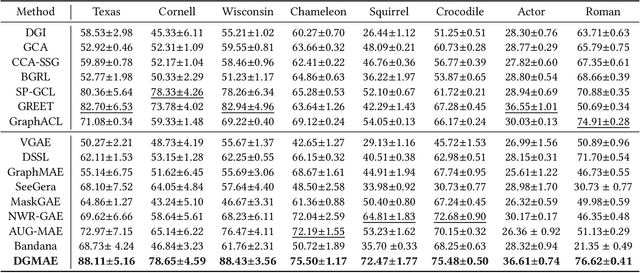
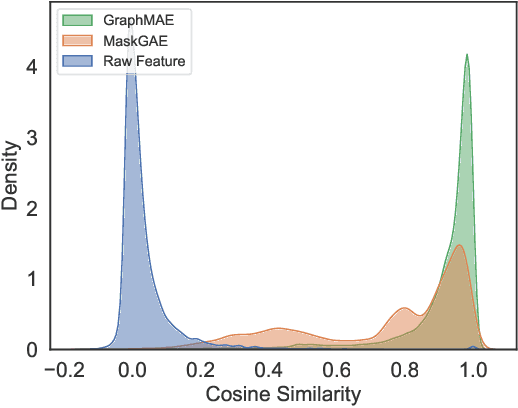
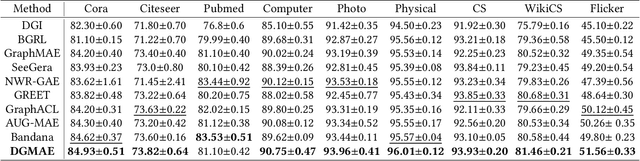
Masked Graph Auto-Encoder, a powerful graph self-supervised training paradigm, has recently shown superior performance in graph representation learning. Existing works typically rely on node contextual information to recover the masked information. However, they fail to generalize well to heterophilic graphs where connected nodes may be not similar, because they focus only on capturing the neighborhood information and ignoring the discrepancy information between different nodes, resulting in indistinguishable node representations. In this paper, to address this issue, we propose a Discrepancy-Aware Graph Mask Auto-Encoder (DGMAE). It obtains more distinguishable node representations by reconstructing the discrepancy information of neighboring nodes during the masking process. We conduct extensive experiments on 17 widely-used benchmark datasets. The results show that our DGMAE can effectively preserve the discrepancies of nodes in low-dimensional space. Moreover, DGMAE significantly outperforms state-of-the-art graph self-supervised learning methods on three graph analytic including tasks node classification, node clustering, and graph classification, demonstrating its remarkable superiority. The code of DGMAE is available at https://github.com/zhengziyu77/DGMAE.