 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Single-Granularity Prompts: A Multi-Scale Chain-of-Thought Prompt Learning for Graph
Oct 10, 2025The "pre-train, prompt'' paradigm, designed to bridge the gap between pre-training tasks and downstream objectives, has been extended from the NLP domain to the graph domain and has achieved remarkable progress. Current mainstream graph prompt-tuning methods modify input or output features using learnable prompt vectors. However, existing approaches are confined to single-granularity (e.g., node-level or subgraph-level) during prompt generation, overlooking the inherently multi-scale structural information in graph data, which limits the diversity of prompt semantics. To address this issue, we pioneer the integration of multi-scale information into graph prompt and propose a Multi-Scale Graph Chain-of-Thought (MSGCOT) prompting framework. Specifically, we design a lightweight, low-rank coarsening network to efficiently capture multi-scale structural features as hierarchical basis vectors for prompt generation. Subsequently, mimicking human cognition from coarse-to-fine granularity, we dynamically integrate multi-scale information at each reasoning step, forming a progressive coarse-to-fine prompt chain. Extensive experiments on eight benchmark datasets demonstrate that MSGCOT outperforms the state-of-the-art single-granularity graph prompt-tuning method, particularly in few-shot scenarios, showcasing superior performance.
Enhancing Homophily-Heterophily Separation: Relation-Aware Learning in Heterogeneous Graphs
Jun 26, 2025Real-world networks usually have a property of node heterophily, that is, the connected nodes usually have different features or different labels. This heterophily issue has been extensively studied in homogeneous graphs but remains under-explored in heterogeneous graphs, where there are multiple types of nodes and edges. Capturing node heterophily in heterogeneous graphs is very challenging since both node/edge heterogeneity and node heterophily should be carefully taken into consideration. Existing methods typically convert heterogeneous graphs into homogeneous ones to learn node heterophily, which will inevitably lose the potential heterophily conveyed by heterogeneous relations. To bridge this gap, we propose Relation-Aware Separation of Homophily and Heterophily (RASH), a novel contrastive learning framework that explicitly models high-order semantics of heterogeneous interactions and adaptively separates homophilic and heterophilic patterns. Particularly, RASH introduces dual heterogeneous hypergraphs to encode multi-relational bipartite subgraphs and dynamically constructs homophilic graphs and heterophilic graphs based on relation importance. A multi-relation contrastive loss is designed to align heterogeneous and homophilic/heterophilic views by maximizing mutual information. In this way, RASH simultaneously resolves the challenges of heterogeneity and heterophily in heterogeneous graphs. Extensive experiments on benchmark datasets demonstrate the effectiveness of RASH across various downstream tasks. The code is available at: https://github.com/zhengziyu77/RASH.
Discrepancy-Aware Graph Mask Auto-Encoder
Jun 24, 2025
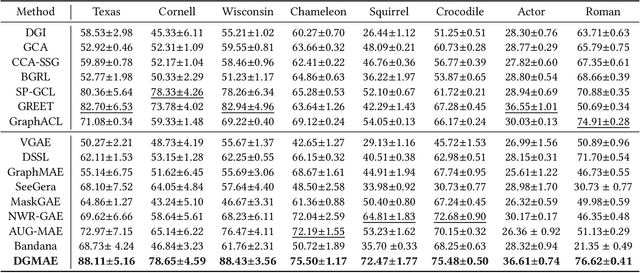
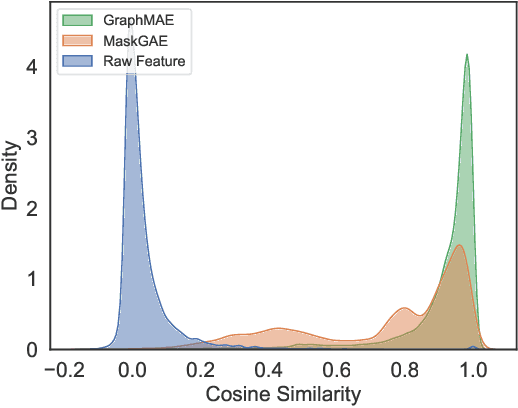
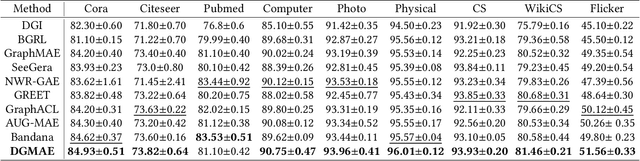
Masked Graph Auto-Encoder, a powerful graph self-supervised training paradigm, has recently shown superior performance in graph representation learning. Existing works typically rely on node contextual information to recover the masked information. However, they fail to generalize well to heterophilic graphs where connected nodes may be not similar, because they focus only on capturing the neighborhood information and ignoring the discrepancy information between different nodes, resulting in indistinguishable node representations. In this paper, to address this issue, we propose a Discrepancy-Aware Graph Mask Auto-Encoder (DGMAE). It obtains more distinguishable node representations by reconstructing the discrepancy information of neighboring nodes during the masking process. We conduct extensive experiments on 17 widely-used benchmark datasets. The results show that our DGMAE can effectively preserve the discrepancies of nodes in low-dimensional space. Moreover, DGMAE significantly outperforms state-of-the-art graph self-supervised learning methods on three graph analytic including tasks node classification, node clustering, and graph classification, demonstrating its remarkable superiority. The code of DGMAE is available at https://github.com/zhengziyu77/DGMAE.
AGMixup: Adaptive Graph Mixup for Semi-supervised Node Classification
Dec 11, 2024



Mixup is a data augmentation technique that enhances model generalization by interpolating between data points using a mixing ratio $\lambda$ in the image domain. Recently, the concept of mixup has been adapted to the graph domain through node-centric interpolations. However, these approaches often fail to address the complexity of interconnected relationships, potentially damaging the graph's natural topology and undermining node interactions. Furthermore, current graph mixup methods employ a one-size-fits-all strategy with a randomly sampled $\lambda$ for all mixup pairs, ignoring the diverse needs of different pairs. This paper proposes an Adaptive Graph Mixup (AGMixup) framework for semi-supervised node classification. AGMixup introduces a subgraph-centric approach, which treats each subgraph similarly to how images are handled in Euclidean domains, thus facilitating a more natural integration of mixup into graph-based learning. We also propose an adaptive mechanism to tune the mixing ratio $\lambda$ for diverse mixup pairs, guided by the contextual similarity and uncertainty of the involved subgraphs. Extensive experiments across seven datasets on semi-supervised node classification benchmarks demonstrate AGMixup's superiority over state-of-the-art graph mixup methods. Source codes are available at \url{https://github.com/WeigangLu/AGMixup}.
* Accepted by AAAI 2025
Aligning Multiple Knowledge Graphs in a Single Pass
Aug 01, 2024



Entity alignment (EA) is to identify equivalent entities across different knowledge graphs (KGs), which can help fuse these KGs into a more comprehensive one. Previous EA methods mainly focus on aligning a pair of KGs, and to the best of our knowledge, no existing EA method considers aligning multiple (more than two) KGs. To fill this research gap, in this work, we study a novel problem of aligning multiple KGs and propose an effective framework named MultiEA to solve the problem. First, we embed the entities of all the candidate KGs into a common feature space by a shared KG encoder. Then, we explore three alignment strategies to minimize the distances among pre-aligned entities. In particular, we propose an innovative inference enhancement technique to improve the alignment performance by incorporating high-order similarities. Finally, to verify the effectiveness of MultiEA, we construct two new real-world benchmark datasets and conduct extensive experiments on them. The results show that our MultiEA can effectively and efficiently align multiple KGs in a single pass.
AdaGMLP: AdaBoosting GNN-to-MLP Knowledge Distillation
May 23, 2024


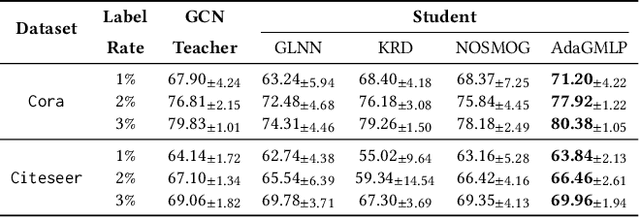
Graph Neural Networks (GNNs) have revolutionized graph-based machine learning, but their heavy computational demands pose challenges for latency-sensitive edge devices in practical industrial applications. In response, a new wave of methods, collectively known as GNN-to-MLP Knowledge Distillation, has emerged. They aim to transfer GNN-learned knowledge to a more efficient MLP student, which offers faster, resource-efficient inference while maintaining competitive performance compared to GNNs. However, these methods face significant challenges in situations with insufficient training data and incomplete test data, limiting their applicability in real-world applications. To address these challenges, we propose AdaGMLP, an AdaBoosting GNN-to-MLP Knowledge Distillation framework. It leverages an ensemble of diverse MLP students trained on different subsets of labeled nodes, addressing the issue of insufficient training data. Additionally, it incorporates a Node Alignment technique for robust predictions on test data with missing or incomplete features. Our experiments on seven benchmark datasets with different settings demonstrate that AdaGMLP outperforms existing G2M methods, making it suitable for a wide range of latency-sensitive real-world applications. We have submitted our code to the GitHub repository (https://github.com/WeigangLu/AdaGMLP-KDD24).
* Accepted by KDD 2024
NodeMixup: Tackling Under-Reaching for Graph Neural Networks
Dec 21, 2023Graph Neural Networks (GNNs) have become mainstream methods for solving the semi-supervised node classification problem. However, due to the uneven location distribution of labeled nodes in the graph, labeled nodes are only accessible to a small portion of unlabeled nodes, leading to the \emph{under-reaching} issue. In this study, we firstly reveal under-reaching by conducting an empirical investigation on various well-known graphs. Then, we demonstrate that under-reaching results in unsatisfactory distribution alignment between labeled and unlabeled nodes through systematic experimental analysis, significantly degrading GNNs' performance. To tackle under-reaching for GNNs, we propose an architecture-agnostic method dubbed NodeMixup. The fundamental idea is to (1) increase the reachability of labeled nodes by labeled-unlabeled pairs mixup, (2) leverage graph structures via fusing the neighbor connections of intra-class node pairs to improve performance gains of mixup, and (3) use neighbor label distribution similarity incorporating node degrees to determine sampling weights for node mixup. Extensive experiments demonstrate the efficacy of NodeMixup in assisting GNNs in handling under-reaching. The source code is available at \url{https://github.com/WeigangLu/NodeMixup}.
Pseudo Contrastive Learning for Graph-based Semi-supervised Learning
Feb 19, 2023



Pseudo Labeling is a technique used to improve the performance of semi-supervised Graph Neural Networks (GNNs) by generating additional pseudo-labels based on confident predictions. However, the quality of generated pseudo-labels has long been a concern due to the sensitivity of the classification objective to given labels. To avoid the untrustworthy classification supervision indicating ``a node belongs to a specific class,'' we favor the fault-tolerant contrasting supervision demonstrating ``two nodes do not belong to the same class.'' Thus, the problem of generating high-quality pseudo-labels is then transformed into a relaxed version, i.e., finding reliable contrasting pairs. To achieve this, we propose a general framework for GNNs, termed Pseudo Contrastive Learning (PCL). It separates two nodes whose positive and negative pseudo-labels target the same class. To incorporate topological knowledge into learning, we devise a topologically weighted contrastive loss that spends more effort separating negative pairs with smaller topological distances. Additionally, to alleviate the heavy reliance on data augmentation, we augment nodes only by applying dropout to the encoded representations. Theoretically, we prove that PCL with the lightweight augmentation works like a representation regularizer to effectively learn separation between negative pairs. Experimentally, we employ PCL on various models, which consistently outperform their counterparts using other popular general techniques on five real-world graphs.
Self-supervised Heterogeneous Graph Pre-training Based on Structural Clustering
Oct 19, 2022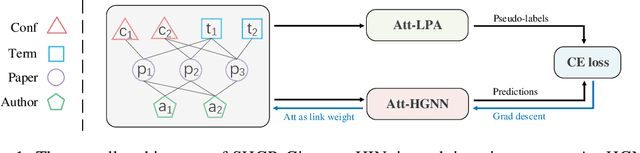

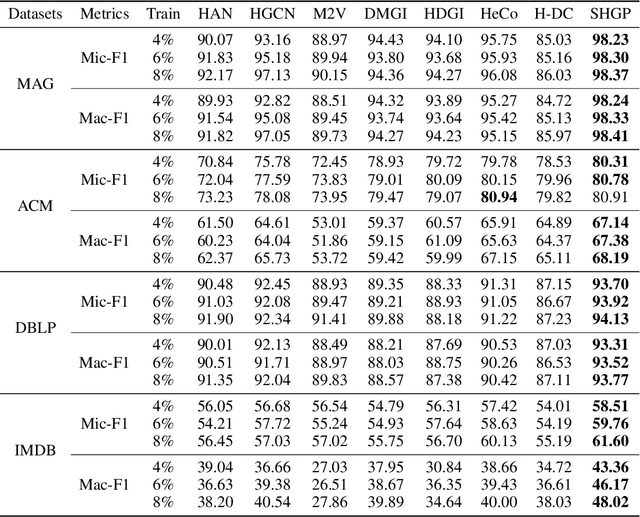
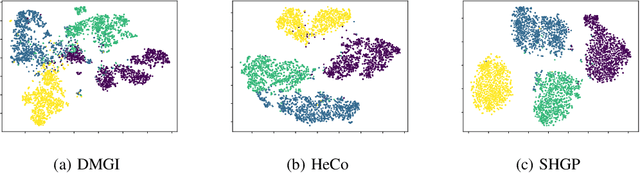
Recent self-supervised pre-training methods on Heterogeneous Information Networks (HINs) have shown promising competitiveness over traditional semi-supervised Heterogeneous Graph Neural Networks (HGNNs). Unfortunately, their performance heavily depends on careful customization of various strategies for generating high-quality positive examples and negative examples, which notably limits their flexibility and generalization ability. In this work, we present SHGP, a novel Self-supervised Heterogeneous Graph Pre-training approach, which does not need to generate any positive examples or negative examples. It consists of two modules that share the same attention-aggregation scheme. In each iteration, the Att-LPA module produces pseudo-labels through structural clustering, which serve as the self-supervision signals to guide the Att-HGNN module to learn object embeddings and attention coefficients. The two modules can effectively utilize and enhance each other, promoting the model to learn discriminative embeddings. Extensive experiments on four real-world datasets demonstrate the superior effectiveness of SHGP against state-of-the-art unsupervised baselines and even semi-supervised baselines. We release our source code at: https://github.com/kepsail/SHGP.
An Improved Normed-Deformable Convolution for Crowd Counting
Jun 16, 2022
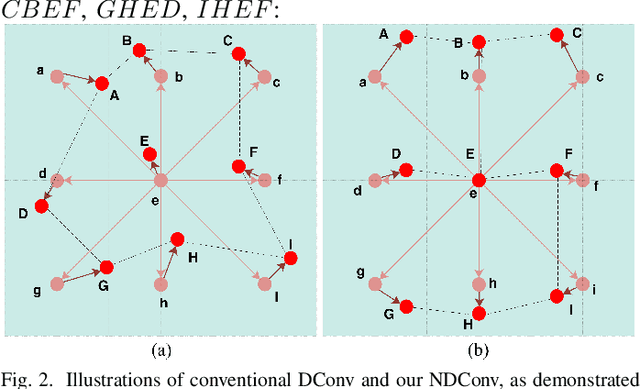
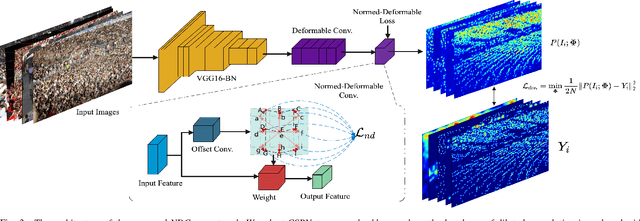
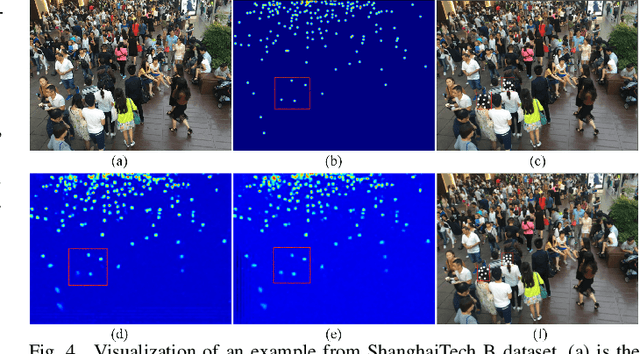
In recent years, crowd counting has become an important issue in computer vision. In most methods, the density maps are generated by convolving with a Gaussian kernel from the ground-truth dot maps which are marked around the center of human heads. Due to the fixed geometric structures in CNNs and indistinct head-scale information, the head features are obtained incompletely. Deformable convolution is proposed to exploit the scale-adaptive capabilities for CNN features in the heads. By learning the coordinate offsets of the sampling points, it is tractable to improve the ability to adjust the receptive field. However, the heads are not uniformly covered by the sampling points in the deformable convolution, resulting in loss of head information. To handle the non-uniformed sampling, an improved Normed-Deformable Convolution (\textit{i.e.,}NDConv) implemented by Normed-Deformable loss (\textit{i.e.,}NDloss) is proposed in this paper. The offsets of the sampling points which are constrained by NDloss tend to be more even. Then, the features in the heads are obtained more completely, leading to better performance. Especially, the proposed NDConv is a light-weight module which shares similar computation burden with Deformable Convolution. In the extensive experiments, our method outperforms state-of-the-art methods on ShanghaiTech A, ShanghaiTech B, UCF\_QNRF, and UCF\_CC\_50 dataset, achieving 61.4, 7.8, 91.2, and 167.2 MAE, respectively. The code is available at https://github.com/bingshuangzhuzi/NDConv