 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable Medical LLMs: Benchmarking and Enhancing Confidence Estimation of Large Language Models in Medical Consultation
Jan 22, 2026Large-scale language models (LLMs) often offer clinical judgments based on incomplete information, increasing the risk of misdiagnosis. Existing studies have primarily evaluated confidence in single-turn, static settings, overlooking the coupling between confidence and correctness as clinical evidence accumulates during real consultations, which limits their support for reliable decision-making. We propose the first benchmark for assessing confidence in multi-turn interaction during realistic medical consultations. Our benchmark unifies three types of medical data for open-ended diagnostic generation and introduces an information sufficiency gradient to characterize the confidence-correctness dynamics as evidence increases. We implement and compare 27 representative methods on this benchmark; two key insights emerge: (1) medical data amplifies the inherent limitations of token-level and consistency-level confidence methods, and (2) medical reasoning must be evaluated for both diagnostic accuracy and information completeness. Based on these insights, we present MedConf, an evidence-grounded linguistic self-assessment framework that constructs symptom profiles via retrieval-augmented generation, aligns patient information with supporting, missing, and contradictory relations, and aggregates them into an interpretable confidence estimate through weighted integration. Across two LLMs and three medical datasets, MedConf consistently outperforms state-of-the-art methods on both AUROC and Pearson correlation coefficient metrics, maintaining stable performance under conditions of information insufficiency and multimorbidity. These results demonstrate that information adequacy is a key determinant of credible medical confidence modeling, providing a new pathway toward building more reliable and interpretable large medical models.
Smile on the Face, Sadness in the Eyes: Bridging the Emotion Gap with a Multimodal Dataset of Eye and Facial Behaviors
Dec 18, 2025Emotion Recognition (ER) is the process of analyzing and identifying human emotions from sensing data. Currently, the field heavily relies on facial expression recognition (FER) because visual channel conveys rich emotional cues. However, facial expressions are often used as social tools rather than manifestations of genuine inner emotions. To understand and bridge this gap between FER and ER, we introduce eye behaviors as an important emotional cue and construct an Eye-behavior-aided Multimodal Emotion Recognition (EMER) dataset. To collect data with genuine emotions, spontaneous emotion induction paradigm is exploited with stimulus material, during which non-invasive eye behavior data, like eye movement sequences and eye fixation maps, is captured together with facial expression videos. To better illustrate the gap between ER and FER, multi-view emotion labels for mutimodal ER and FER are separately annotated. Furthermore, based on the new dataset, we design a simple yet effective Eye-behavior-aided MER Transformer (EMERT) that enhances ER by bridging the emotion gap. EMERT leverages modality-adversarial feature decoupling and a multitask Transformer to model eye behaviors as a strong complement to facial expressions. In the experiment, we introduce seven multimodal benchmark protocols for a variety of comprehensive evaluations of the EMER dataset. The results show that the EMERT outperforms other state-of-the-art multimodal methods by a great margin, revealing the importance of modeling eye behaviors for robust ER. To sum up, we provide a comprehensive analysis of the importance of eye behaviors in ER, advancing the study on addressing the gap between FER and ER for more robust ER performance. Our EMER dataset and the trained EMERT models will be publicly available at https://github.com/kejun1/EMER.
Cross-Sample Augmented Test-Time Adaptation for Personalized Intraoperative Hypotension Prediction
Dec 12, 2025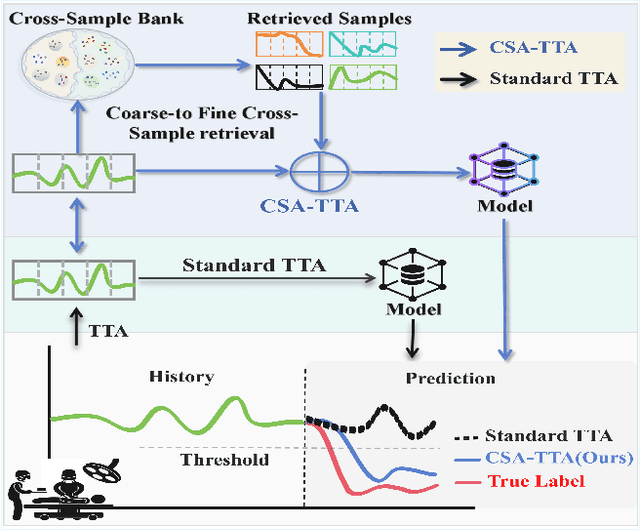
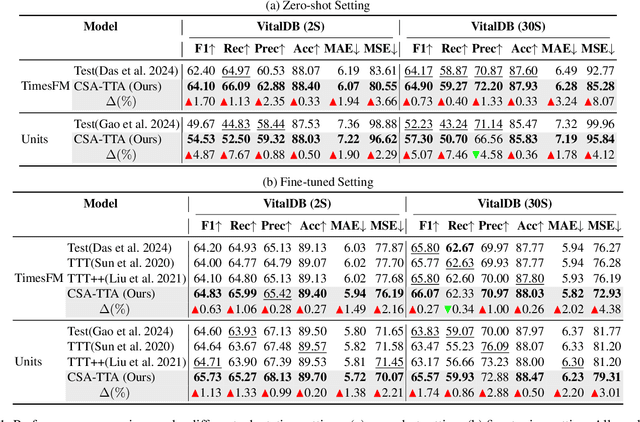
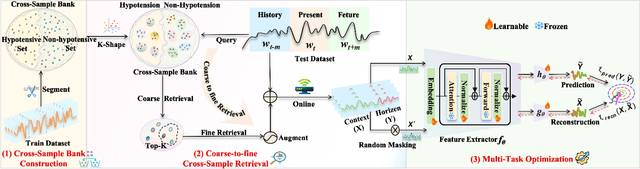
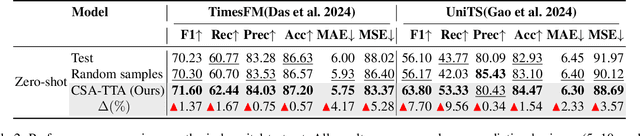
Intraoperative hypotension (IOH) poses significant surgical risks, but accurate prediction remains challenging due to patient-specific variability. While test-time adaptation (TTA) offers a promising approach for personalized prediction, the rarity of IOH events often leads to unreliable test-time training. To address this, we propose CSA-TTA, a novel Cross-Sample Augmented Test-Time Adaptation framework that enhances training by incorporating hypotension events from other individuals. Specifically, we first construct a cross-sample bank by segmenting historical data into hypotensive and non-hypotensive samples. Then, we introduce a coarse-to-fine retrieval strategy for building test-time training data: we initially apply K-Shape clustering to identify representative cluster centers and subsequently retrieve the top-K semantically similar samples based on the current patient signal. Additionally, we integrate both self-supervised masked reconstruction and retrospective sequence forecasting signals during training to enhance model adaptability to rapid and subtle intraoperative dynamics. We evaluate the proposed CSA-TTA on both the VitalDB dataset and a real-world in-hospital dataset by integrating it with state-of-the-art time series forecasting models, including TimesFM and UniTS. CSA-TTA consistently enhances performance across settings-for instance, on VitalDB, it improves Recall and F1 scores by +1.33% and +1.13%, respectively, under fine-tuning, and by +7.46% and +5.07% in zero-shot scenarios-demonstrating strong robustness and generalization.
ChartMaster: Advancing Chart-to-Code Generation with Real-World Charts and Chart Similarity Reinforcement Learning
Aug 25, 2025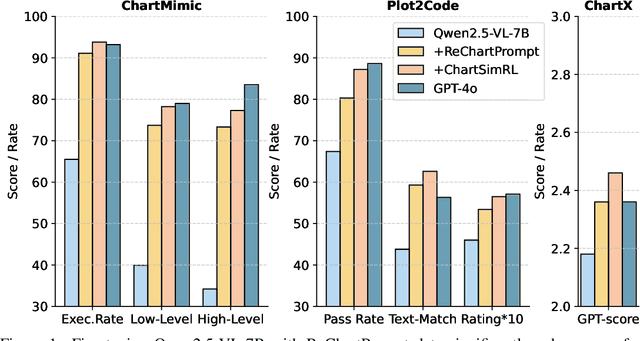

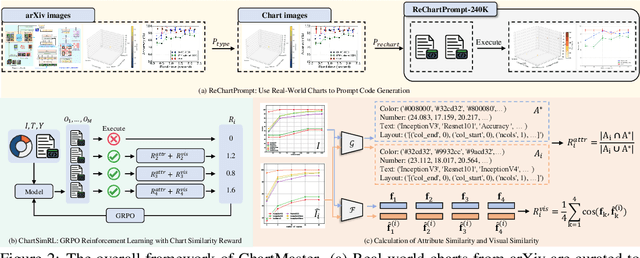

The chart-to-code generation task requires MLLMs to convert chart images into executable code. This task faces two major challenges: limited data diversity and insufficient maintenance of visual consistency between generated and original charts during training. Existing datasets mainly rely on seed data to prompt GPT models for code generation, resulting in homogeneous samples. To address this, we propose ReChartPrompt, which leverages real-world, human-designed charts from arXiv papers as prompts instead of synthetic seeds. Using the diverse styles and rich content of arXiv charts, we construct ReChartPrompt-240K, a large-scale and highly diverse dataset. Another challenge is that although SFT effectively improve code understanding, it often fails to ensure that generated charts are visually consistent with the originals. To address this, we propose ChartSimRL, a GRPO-based reinforcement learning algorithm guided by a novel chart similarity reward. This reward consists of attribute similarity, which measures the overlap of chart attributes such as layout and color between the generated and original charts, and visual similarity, which assesses similarity in texture and other overall visual features using convolutional neural networks. Unlike traditional text-based rewards such as accuracy or format rewards, our reward considers the multimodal nature of the chart-to-code task and effectively enhances the model's ability to accurately reproduce charts. By integrating ReChartPrompt and ChartSimRL, we develop the ChartMaster model, which achieves state-of-the-art results among 7B-parameter models and even rivals GPT-4o on various chart-to-code generation benchmarks. All resources are available at https://github.com/WentaoTan/ChartMaster.
Bi-Level Optimization for Self-Supervised AI-Generated Face Detection
Jul 30, 2025



AI-generated face detectors trained via supervised learning typically rely on synthesized images from specific generators, limiting their generalization to emerging generative techniques. To overcome this limitation, we introduce a self-supervised method based on bi-level optimization. In the inner loop, we pretrain a vision encoder only on photographic face images using a set of linearly weighted pretext tasks: classification of categorical exchangeable image file format (EXIF) tags, ranking of ordinal EXIF tags, and detection of artificial face manipulations. The outer loop then optimizes the relative weights of these pretext tasks to enhance the coarse-grained detection of manipulated faces, serving as a proxy task for identifying AI-generated faces. In doing so, it aligns self-supervised learning more closely with the ultimate goal of AI-generated face detection. Once pretrained, the encoder remains fixed, and AI-generated faces are detected either as anomalies under a Gaussian mixture model fitted to photographic face features or by a lightweight two-layer perceptron serving as a binary classifier. Extensive experiments demonstrate that our detectors significantly outperform existing approaches in both one-class and binary classification settings, exhibiting strong generalization to unseen generators.
Re-Initialization Token Learning for Tool-Augmented Large Language Models
Jun 17, 2025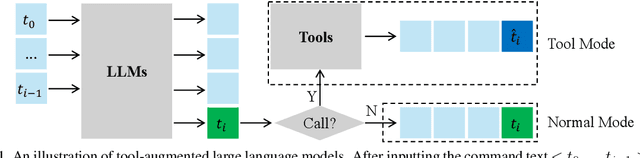
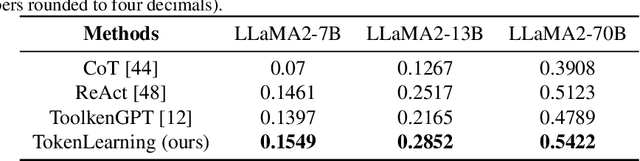
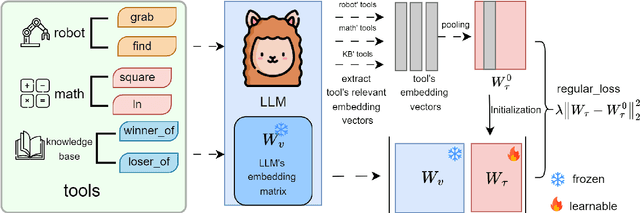
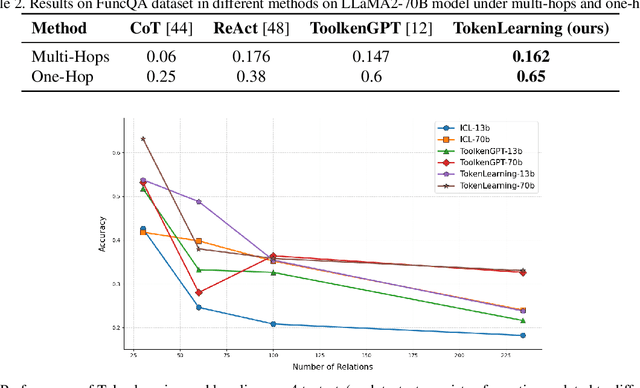
Large language models have demonstrated exceptional performance, yet struggle with complex tasks such as numerical reasoning, plan generation. Integrating external tools, such as calculators and databases, into large language models (LLMs) is crucial for enhancing problem-solving capabilities. Current methods assign a unique token to each tool, enabling LLMs to call tools through token prediction-similar to word generation. However, this approach fails to account for the relationship between tool and word tokens, limiting adaptability within pre-trained LLMs. To address this issue, we propose a novel token learning method that aligns tool tokens with the existing word embedding space from the perspective of initialization, thereby enhancing model performance. We begin by constructing prior token embeddings for each tool based on the tool's name or description, which are used to initialize and regularize the learnable tool token embeddings. This ensures the learned embeddings are well-aligned with the word token space, improving tool call accuracy. We evaluate the method on tasks such as numerical reasoning, knowledge-based question answering, and embodied plan generation using GSM8K-XL, FuncQA, KAMEL, and VirtualHome datasets. The results demonstrate clear improvements over recent baselines, including CoT, REACT, ICL, and ToolkenGPT, indicating that our approach effectively augments LLMs with tools through relevant tokens across diverse domains.
Reverse Prompt: Cracking the Recipe Inside Text-to-Image Generation
Mar 25, 2025Text-to-image generation has become increasingly popular, but achieving the desired images often requires extensive prompt engineering. In this paper, we explore how to decode textual prompts from reference images, a process we refer to as image reverse prompt engineering. This technique enables us to gain insights from reference images, understand the creative processes of great artists, and generate impressive new images. To address this challenge, we propose a method known as automatic reverse prompt optimization (ARPO). Specifically, our method refines an initial prompt into a high-quality prompt through an iteratively imitative gradient prompt optimization process: 1) generating a recreated image from the current prompt to instantiate its guidance capability; 2) producing textual gradients, which are candidate prompts intended to reduce the difference between the recreated image and the reference image; 3) updating the current prompt with textual gradients using a greedy search method to maximize the CLIP similarity between prompt and reference image. We compare ARPO with several baseline methods, including handcrafted techniques, gradient-based prompt tuning methods, image captioning, and data-driven selection method. Both quantitative and qualitative results demonstrate that our ARPO converges quickly to generate high-quality reverse prompts. More importantly, we can easily create novel images with diverse styles and content by directly editing these reverse prompts. Code will be made publicly available.
End-to-End HOI Reconstruction Transformer with Graph-based Encoding
Mar 08, 2025



With the diversification of human-object interaction (HOI) applications and the success of capturing human meshes, HOI reconstruction has gained widespread attention. Existing mainstream HOI reconstruction methods often rely on explicitly modeling interactions between humans and objects. However, such a way leads to a natural conflict between 3D mesh reconstruction, which emphasizes global structure, and fine-grained contact reconstruction, which focuses on local details. To address the limitations of explicit modeling, we propose the End-to-End HOI Reconstruction Transformer with Graph-based Encoding (HOI-TG). It implicitly learns the interaction between humans and objects by leveraging self-attention mechanisms. Within the transformer architecture, we devise graph residual blocks to aggregate the topology among vertices of different spatial structures. This dual focus effectively balances global and local representations. Without bells and whistles, HOI-TG achieves state-of-the-art performance on BEHAVE and InterCap datasets. Particularly on the challenging InterCap dataset, our method improves the reconstruction results for human and object meshes by 8.9% and 8.6%, respectively.
An Atomic Skill Library Construction Method for Data-Efficient Embodied Manipulation
Jan 25, 2025



Embodied manipulation is a fundamental ability in the realm of embodied artificial intelligence. Although current embodied manipulation models show certain generalizations in specific settings, they struggle in new environments and tasks due to the complexity and diversity of real-world scenarios. The traditional end-to-end data collection and training manner leads to significant data demands, which we call ``data explosion''. To address the issue, we introduce a three-wheeled data-driven method to build an atomic skill library. We divide tasks into subtasks using the Vision-Language Planning (VLP). Then, atomic skill definitions are formed by abstracting the subtasks. Finally, an atomic skill library is constructed via data collection and Vision-Language-Action (VLA) fine-tuning. As the atomic skill library expands dynamically with the three-wheel update strategy, the range of tasks it can cover grows naturally. In this way, our method shifts focus from end-to-end tasks to atomic skills, significantly reducing data costs while maintaining high performance and enabling efficient adaptation to new tasks. Extensive experiments in real-world settings demonstrate the effectiveness and efficiency of our approach.
Leveraging Metamemory Mechanisms for Enhanced Data-Free Code Generation in LLMs
Jan 14, 2025



Automated code generation using large language models (LLMs) has gained attention due to its efficiency and adaptability. However, real-world coding tasks or benchmarks like HumanEval and StudentEval often lack dedicated training datasets, challenging existing few-shot prompting approaches that rely on reference examples. Inspired by human metamemory-a cognitive process involving recall and evaluation-we present a novel framework (namely M^2WF) for improving LLMs' one-time code generation. This approach enables LLMs to autonomously generate, evaluate, and utilize synthetic examples to enhance reliability and performance. Unlike prior methods, it minimizes dependency on curated data and adapts flexibly to various coding scenarios. Our experiments demonstrate significant improvements in coding benchmarks, offering a scalable and robust solution for data-free environments. The code and framework will be publicly available on GitHub and HuggingFace.