 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataLadder: A Simulation-Enabled Interconversion Toolchain for the Embodied Data Pyramid
Jun 15, 2026Generalist robot policies require trustworthy evaluation and robot-usable training data, but both are difficult to scale with physical robots alone. Real-robot trials and demonstrations remain the most faithful source of deployment signals, yet they are slow, costly, and hard to reproduce. We present DataLadder, a simulation-enabled interconversion toolchain for human-robot aligned model evaluation and data generation, denoted as Robot $\rightleftharpoons$ Simulation $\rightleftharpoons$ Human. On the one hand, the Robot $\rightarrow$ Simulation $\rightarrow$ Human pathway supports human-robot aligned model evaluation by reconstructing real-robot tabletop organization tasks as calibrated digital twins for scalable evaluation, while using human embodied feedback to inspect and refine the naturalness of simulated motions. On the other hand, the Human $\rightarrow$ Simulation $\rightarrow$ Robot pathway supports human-robot aligned data generation: it lifts ego-centric human demonstrations into simulation, checks them under robot physical constraints, and converts them into robot-centered trajectories, annotations, and visual observations. Together, these pathways use the JoySim simulator as both a scalable evaluation layer and a physical consistency filter for robot data generation. We further package the core reconstruction, simulation, rendering, and realism-augmentation modules as cloud services on JD Cloud, turning the system into reusable infrastructure for robot data generation and model evaluation.
Embodied3DBench: Benchmarking Low-Level Embodied Spatial Intelligence of Vision Language Models
May 27, 2026Are current Vision Language Models (VLMs) ready to comprehend and reason about complex embodied interactions in 3D environments? We introduce Embodied3DBench, a robot-centric benchmark targeting low-level spatial intelligence in embodied 3D environments. To systematically evaluate these foundational perceptual capabilities, the benchmark includes 6 task categories divided into two core groups: Spatial Structural Understanding (Grounding, Spatial Relation Prediction, and Multi-view Correspondence) and Interaction-Oriented Perception (Affordance Prediction, Grasp Point Prediction, and Trajectory Prediction). The benchmark spans 12 subcategories and contains over 21k high-quality question-answer pairs. We evaluate 13 state-of-the-art models, and the results show that while current models exhibit relatively strong high-level spatial reasoning, such as understanding object-to-object positional relations, they remain fragile in interaction-oriented perception, highlighting a significant lack of robust 3D-aware interaction priors. To actively bridge this capability gap revealed by our benchmark, we further synthesize a large-scale training dataset comprising 1.3M QA pairs. Notably, fine-tuning on this dataset yields significant improvements in low-level spatial intelligence. Ultimately, Embodied3DBench fills a critical gap by providing both a systematic evaluation framework and a scalable data solution, setting a clear target for the development of interaction-aware multimodal systems.
JoyAI-RA 0.1: A Foundation Model for Robotic Autonomy
Apr 22, 2026Robotic autonomy in open-world environments is fundamentally limited by insufficient data diversity and poor cross-embodiment generalization. Existing robotic datasets are often limited in scale and task coverage, while relatively large differences across robot embodiments impede effective behavior knowledge transfer. To address these challenges, we propose JoyAI-RA, a vision-language-action (VLA) embodied foundation model tailored for generalizable robotic manipulation. JoyAI-RA presents a multi-source multi-level pretraining framework that integrates web data, large-scale egocentric human manipulation videos, simulation-generated trajectories, and real-robot data. Through training on heterogeneous multi-source data with explicit action-space unification, JoyAI-RA effectively bridges embodiment gaps, particularly between human manipulation and robotic control, thereby enhancing cross-embodiment behavior learning. JoyAI-RA outperforms state-of-the-art methods in both simulation and real-world benchmarks, especially on diverse tasks with generalization demands.
HiPolicy: Hierarchical Multi-Frequency Action Chunking for Policy Learning
Apr 07, 2026Robotic imitation learning faces a fundamental trade-off between modeling long-horizon dependencies and enabling fine-grained closed-loop control. Existing fixed-frequency action chunking approaches struggle to achieve both. Building on this insight, we propose HiPolicy, a hierarchical multi-frequency action chunking framework that jointly predicts action sequences at different frequencies to capture both coarse high-level plans and precise reactive motions. We extract and fuse hierarchical features from history observations aligned to each frequency for multi-frequency chunk generation, and introduce an entropy-guided execution mechanism that adaptively balances long-horizon planning with fine-grained control based on action uncertainty. Experiments on diverse simulated benchmarks and real-world manipulation tasks show that HiPolicy can be seamlessly integrated into existing 2D and 3D generative policies, delivering consistent improvements in performance while significantly enhancing execution efficiency.
AnchorDP3: 3D Affordance Guided Sparse Diffusion Policy for Robotic Manipulation
Jun 24, 2025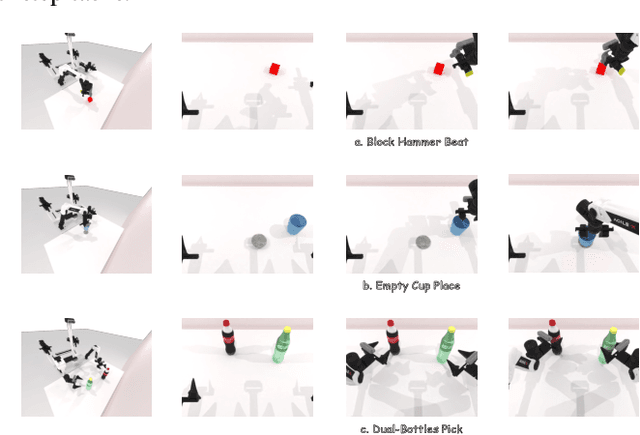

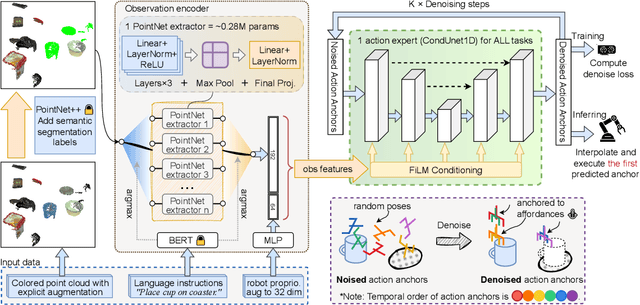
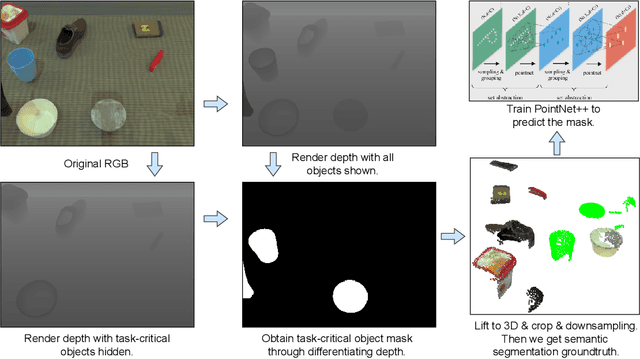
We present AnchorDP3, a diffusion policy framework for dual-arm robotic manipulation that achieves state-of-the-art performance in highly randomized environments. AnchorDP3 integrates three key innovations: (1) Simulator-Supervised Semantic Segmentation, using rendered ground truth to explicitly segment task-critical objects within the point cloud, which provides strong affordance priors; (2) Task-Conditioned Feature Encoders, lightweight modules processing augmented point clouds per task, enabling efficient multi-task learning through a shared diffusion-based action expert; (3) Affordance-Anchored Keypose Diffusion with Full State Supervision, replacing dense trajectory prediction with sparse, geometrically meaningful action anchors, i.e., keyposes such as pre-grasp pose, grasp pose directly anchored to affordances, drastically simplifying the prediction space; the action expert is forced to predict both robot joint angles and end-effector poses simultaneously, which exploits geometric consistency to accelerate convergence and boost accuracy. Trained on large-scale, procedurally generated simulation data, AnchorDP3 achieves a 98.7% average success rate in the RoboTwin benchmark across diverse tasks under extreme randomization of objects, clutter, table height, lighting, and backgrounds. This framework, when integrated with the RoboTwin real-to-sim pipeline, has the potential to enable fully autonomous generation of deployable visuomotor policies from only scene and instruction, totally eliminating human demonstrations from learning manipulation skills.
End-to-End HOI Reconstruction Transformer with Graph-based Encoding
Mar 08, 2025



With the diversification of human-object interaction (HOI) applications and the success of capturing human meshes, HOI reconstruction has gained widespread attention. Existing mainstream HOI reconstruction methods often rely on explicitly modeling interactions between humans and objects. However, such a way leads to a natural conflict between 3D mesh reconstruction, which emphasizes global structure, and fine-grained contact reconstruction, which focuses on local details. To address the limitations of explicit modeling, we propose the End-to-End HOI Reconstruction Transformer with Graph-based Encoding (HOI-TG). It implicitly learns the interaction between humans and objects by leveraging self-attention mechanisms. Within the transformer architecture, we devise graph residual blocks to aggregate the topology among vertices of different spatial structures. This dual focus effectively balances global and local representations. Without bells and whistles, HOI-TG achieves state-of-the-art performance on BEHAVE and InterCap datasets. Particularly on the challenging InterCap dataset, our method improves the reconstruction results for human and object meshes by 8.9% and 8.6%, respectively.
An Atomic Skill Library Construction Method for Data-Efficient Embodied Manipulation
Jan 25, 2025



Embodied manipulation is a fundamental ability in the realm of embodied artificial intelligence. Although current embodied manipulation models show certain generalizations in specific settings, they struggle in new environments and tasks due to the complexity and diversity of real-world scenarios. The traditional end-to-end data collection and training manner leads to significant data demands, which we call ``data explosion''. To address the issue, we introduce a three-wheeled data-driven method to build an atomic skill library. We divide tasks into subtasks using the Vision-Language Planning (VLP). Then, atomic skill definitions are formed by abstracting the subtasks. Finally, an atomic skill library is constructed via data collection and Vision-Language-Action (VLA) fine-tuning. As the atomic skill library expands dynamically with the three-wheel update strategy, the range of tasks it can cover grows naturally. In this way, our method shifts focus from end-to-end tasks to atomic skills, significantly reducing data costs while maintaining high performance and enabling efficient adaptation to new tasks. Extensive experiments in real-world settings demonstrate the effectiveness and efficiency of our approach.
Preferred-Action-Optimized Diffusion Policies for Offline Reinforcement Learning
May 29, 2024



Offline reinforcement learning (RL) aims to learn optimal policies from previously collected datasets. Recently, due to their powerful representational capabilities, diffusion models have shown significant potential as policy models for offline RL issues. However, previous offline RL algorithms based on diffusion policies generally adopt weighted regression to improve the policy. This approach optimizes the policy only using the collected actions and is sensitive to Q-values, which limits the potential for further performance enhancement. To this end, we propose a novel preferred-action-optimized diffusion policy for offline RL. In particular, an expressive conditional diffusion model is utilized to represent the diverse distribution of a behavior policy. Meanwhile, based on the diffusion model, preferred actions within the same behavior distribution are automatically generated through the critic function. Moreover, an anti-noise preference optimization is designed to achieve policy improvement by using the preferred actions, which can adapt to noise-preferred actions for stable training. Extensive experiments demonstrate that the proposed method provides competitive or superior performance compared to previous state-of-the-art offline RL methods, particularly in sparse reward tasks such as Kitchen and AntMaze. Additionally, we empirically prove the effectiveness of anti-noise preference optimization.
Empowering Embodied Manipulation: A Bimanual-Mobile Robot Manipulation Dataset for Household Tasks
May 29, 2024



As Embodied AI advances, it increasingly enables robots to handle the complexity of household manipulation tasks more effectively. However, the application of robots in these settings remains limited due to the scarcity of bimanual-mobile robot manipulation datasets. Existing datasets either focus solely on simple grasping tasks using single-arm robots without mobility, or collect sensor data limited to a narrow scope of sensory inputs. As a result, these datasets often fail to encapsulate the intricate and dynamic nature of real-world tasks that bimanual-mobile robots are expected to perform. To address these limitations, we introduce BRMData, a Bimanual-mobile Robot Manipulation Dataset designed specifically for household applications. The dataset includes 10 diverse household tasks, ranging from simple single-arm manipulation to more complex dual-arm and mobile manipulations. It is collected using multi-view and depth-sensing data acquisition strategies. Human-robot interactions and multi-object manipulations are integrated into the task designs to closely simulate real-world household applications. Moreover, we present a Manipulation Efficiency Score (MES) metric to evaluate both the precision and efficiency of robot manipulation methods. BRMData aims to drive the development of versatile robot manipulation technologies, specifically focusing on advancing imitation learning methods from human demonstrations. The dataset is now open-sourced and available at https://embodiedrobot.github.io/, enhancing research and development efforts in the field of Embodied Manipulation.
RaP-Net: A Region-wise and Point-wise Weighting Network to Extract Robust Keypoints for Indoor Localization
Dec 01, 2020

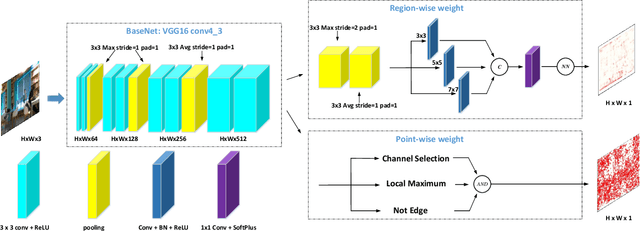
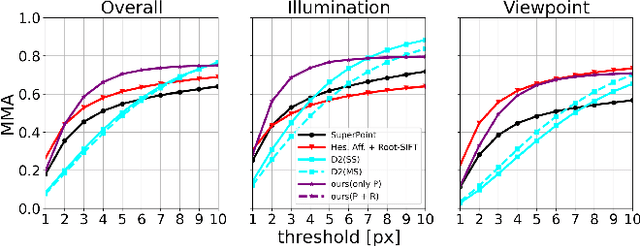
Image keypoint extraction is an important step for visual localization. The localization in indoor environment is challenging for that there may be many unreliable features on dynamic or repetitive objects. Such kind of reliability cannot be well learned by existing Convolutional Neural Network (CNN) based feature extractors. We propose a novel network, RaP-Net, which explicitly addresses feature invariability with a region-wise predictor, and combines it with a point-wise predictor to select reliable keypoints in an image. We also build a new dataset, OpenLORIS-Location, to train this network. The dataset contains 1553 indoor images with location labels. There are various scene changes between images on the same location, which can help a network to learn the invariability in typical indoor scenes. Experimental results show that the proposed RaP-Net trained with the OpenLORIS-Location dataset significantly outperforms existing CNN-based keypoint extraction algorithms for indoor localization. The code and data are available at https://github.com/ivipsourcecode/RaP-Net.