 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorDP3: 3D Affordance Guided Sparse Diffusion Policy for Robotic Manipulation
Jun 24, 2025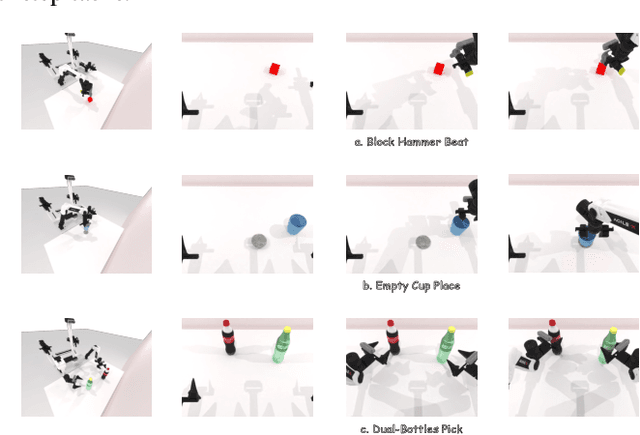

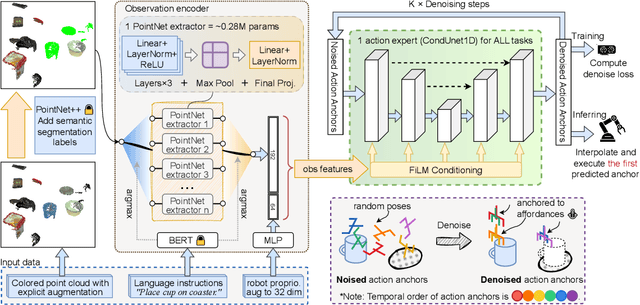
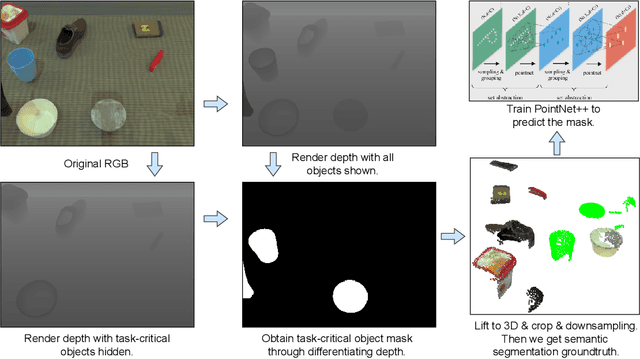
We present AnchorDP3, a diffusion policy framework for dual-arm robotic manipulation that achieves state-of-the-art performance in highly randomized environments. AnchorDP3 integrates three key innovations: (1) Simulator-Supervised Semantic Segmentation, using rendered ground truth to explicitly segment task-critical objects within the point cloud, which provides strong affordance priors; (2) Task-Conditioned Feature Encoders, lightweight modules processing augmented point clouds per task, enabling efficient multi-task learning through a shared diffusion-based action expert; (3) Affordance-Anchored Keypose Diffusion with Full State Supervision, replacing dense trajectory prediction with sparse, geometrically meaningful action anchors, i.e., keyposes such as pre-grasp pose, grasp pose directly anchored to affordances, drastically simplifying the prediction space; the action expert is forced to predict both robot joint angles and end-effector poses simultaneously, which exploits geometric consistency to accelerate convergence and boost accuracy. Trained on large-scale, procedurally generated simulation data, AnchorDP3 achieves a 98.7% average success rate in the RoboTwin benchmark across diverse tasks under extreme randomization of objects, clutter, table height, lighting, and backgrounds. This framework, when integrated with the RoboTwin real-to-sim pipeline, has the potential to enable fully autonomous generation of deployable visuomotor policies from only scene and instruction, totally eliminating human demonstrations from learning manipulation skills.
DREMnet: An Interpretable Denoising Framework for Semi-Airborne Transient Electromagnetic Signal
Mar 28, 2025
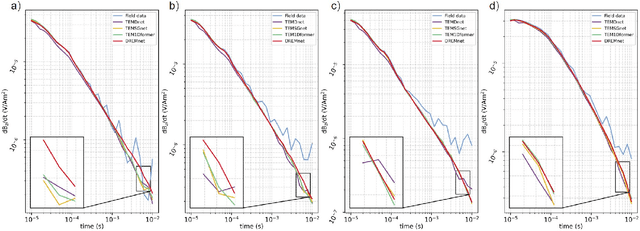


The semi-airborne transient electromagnetic method (SATEM) is capable of conducting rapid surveys over large-scale and hard-to-reach areas. However, the acquired signals are often contaminated by complex noise, which can compromise the accuracy of subsequent inversion interpretations. Traditional denoising techniques primarily rely on parameter selection strategies, which are insufficient for processing field data in noisy environments. With the advent of deep learning, various neural networks have been employed for SATEM signal denoising. However, existing deep learning methods typically use single-mapping learning approaches that struggle to effectively separate signal from noise. These methods capture only partial information and lack interpretability. To overcome these limitations, we propose an interpretable decoupled representation learning framework, termed DREMnet, that disentangles data into content and context factors, enabling robust and interpretable denoising in complex conditions. To address the limitations of CNN and Transformer architectures, we utilize the RWKV architecture for data processing and introduce the Contextual-WKV mechanism, which allows unidirectional WKV to perform bidirectional signal modeling. Our proposed Covering Embedding technique retains the strong local perception of convolutional networks through stacked embedding. Experimental results on test datasets demonstrate that the DREMnet method outperforms existing techniques, with processed field data that more accurately reflects the theoretical signal, offering improved identification of subsurface electrical structures.
OmniManip: Towards General Robotic Manipulation via Object-Centric Interaction Primitives as Spatial Constraints
Jan 07, 2025



The development of general robotic systems capable of manipulating in unstructured environments is a significant challenge. While Vision-Language Models(VLM) excel in high-level commonsense reasoning, they lack the fine-grained 3D spatial understanding required for precise manipulation tasks. Fine-tuning VLM on robotic datasets to create Vision-Language-Action Models(VLA) is a potential solution, but it is hindered by high data collection costs and generalization issues. To address these challenges, we propose a novel object-centric representation that bridges the gap between VLM's high-level reasoning and the low-level precision required for manipulation. Our key insight is that an object's canonical space, defined by its functional affordances, provides a structured and semantically meaningful way to describe interaction primitives, such as points and directions. These primitives act as a bridge, translating VLM's commonsense reasoning into actionable 3D spatial constraints. In this context, we introduce a dual closed-loop, open-vocabulary robotic manipulation system: one loop for high-level planning through primitive resampling, interaction rendering and VLM checking, and another for low-level execution via 6D pose tracking. This design ensures robust, real-time control without requiring VLM fine-tuning. Extensive experiments demonstrate strong zero-shot generalization across diverse robotic manipulation tasks, highlighting the potential of this approach for automating large-scale simulation data generation.
Cascade Attentive Dropout for Weakly Supervised Object Detection
Nov 20, 2020

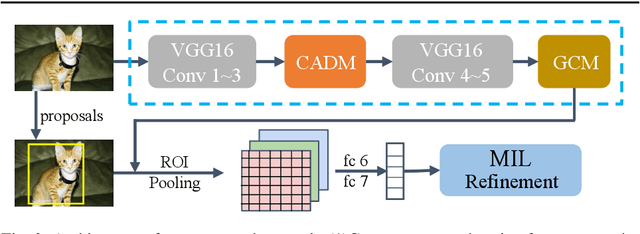

Weakly supervised object detection (WSOD) aims to classify and locate objects with only image-level supervision. Many WSOD approaches adopt multiple instance learning as the initial model, which is prone to converge to the most discriminative object regions while ignoring the whole object, and therefore reduce the model detection performance. In this paper, a novel cascade attentive dropout strategy is proposed to alleviate the part domination problem, together with an improved global context module. We purposely discard attentive elements in both channel and space dimensions, and capture the inter-pixel and inter-channel dependencies to induce the model to better understand the global context. Extensive experiments have been conducted on the challenging PASCAL VOC 2007 benchmarks, which achieve 49.8% mAP and 66.0% CorLoc, outperforming state-of-the-arts.