 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLNet: Cross-View Correspondence Makes a Stronger Geo-Localizationer
Dec 16, 2025Image retrieval-based cross-view geo-localization (IRCVGL) aims to match images captured from significantly different viewpoints, such as satellite and street-level images. Existing methods predominantly rely on learning robust global representations or implicit feature alignment, which often fail to model explicit spatial correspondences crucial for accurate localization. In this work, we propose a novel correspondence-aware feature refinement framework, termed CLNet, that explicitly bridges the semantic and geometric gaps between different views. CLNet decomposes the view alignment process into three learnable and complementary modules: a Neural Correspondence Map (NCM) that spatially aligns cross-view features via latent correspondence fields; a Nonlinear Embedding Converter (NEC) that remaps features across perspectives using an MLP-based transformation; and a Global Feature Recalibration (GFR) module that reweights informative feature channels guided by learned spatial cues. The proposed CLNet can jointly capture both high-level semantics and fine-grained alignments. Extensive experiments on four public benchmarks, CVUSA, CVACT, VIGOR, and University-1652, demonstrate that our proposed CLNet achieves state-of-the-art performance while offering better interpretability and generalizability.
Semantic Localization Guiding Segment Anything Model For Reference Remote Sensing Image Segmentation
Jun 12, 2025The Reference Remote Sensing Image Segmentation (RRSIS) task generates segmentation masks for specified objects in images based on textual descriptions, which has attracted widespread attention and research interest. Current RRSIS methods rely on multi-modal fusion backbones and semantic segmentation heads but face challenges like dense annotation requirements and complex scene interpretation. To address these issues, we propose a framework named \textit{prompt-generated semantic localization guiding Segment Anything Model}(PSLG-SAM), which decomposes the RRSIS task into two stages: coarse localization and fine segmentation. In coarse localization stage, a visual grounding network roughly locates the text-described object. In fine segmentation stage, the coordinates from the first stage guide the Segment Anything Model (SAM), enhanced by a clustering-based foreground point generator and a mask boundary iterative optimization strategy for precise segmentation. Notably, the second stage can be train-free, significantly reducing the annotation data burden for the RRSIS task. Additionally, decomposing the RRSIS task into two stages allows for focusing on specific region segmentation, avoiding interference from complex scenes.We further contribute a high-quality, multi-category manually annotated dataset. Experimental validation on two datasets (RRSIS-D and RRSIS-M) demonstrates that PSLG-SAM achieves significant performance improvements and surpasses existing state-of-the-art models.Our code will be made publicly available.
Lightweight Adapter Learning for More Generalized Remote Sensing Change Detection
Apr 28, 2025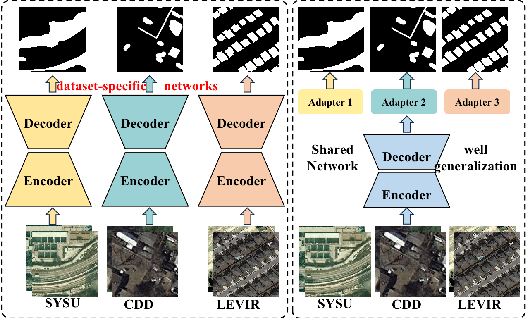

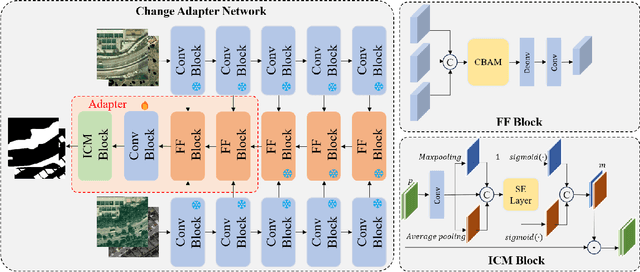
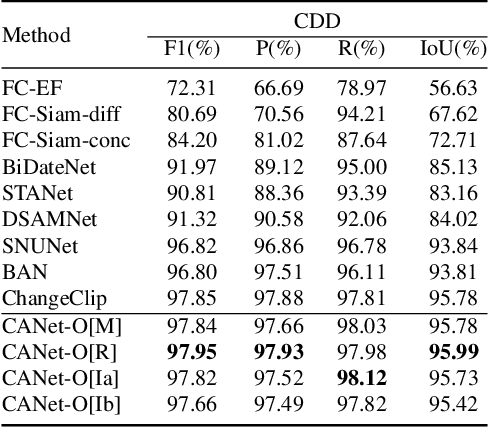
Deep learning methods have shown promising performances in remote sensing image change detection (CD). However, existing methods usually train a dataset-specific deep network for each dataset. Due to the significant differences in the data distribution and labeling between various datasets, the trained dataset-specific deep network has poor generalization performances on other datasets. To solve this problem, this paper proposes a change adapter network (CANet) for a more universal and generalized CD. CANet contains dataset-shared and dataset-specific learning modules. The former explores the discriminative features of images, and the latter designs a lightweight adapter model, to deal with the characteristics of different datasets in data distribution and labeling. The lightweight adapter can quickly generalize the deep network for new CD tasks with a small computation cost. Specifically, this paper proposes an interesting change region mask (ICM) in the adapter, which can adaptively focus on interested change objects and decrease the influence of labeling differences in various datasets. Moreover, CANet adopts a unique batch normalization layer for each dataset to deal with data distribution differences. Compared with existing deep learning methods, CANet can achieve satisfactory CD performances on various datasets simultaneously. Experimental results on several public datasets have verified the effectiveness and advantages of the proposed CANet on CD. CANet has a stronger generalization ability, smaller training costs (merely updating 4.1%-7.7% parameters), and better performances under limited training datasets than other deep learning methods, which also can be flexibly inserted with existing deep models.
Electricity Cost Minimization for Multi-Workflow Allocation in Geo-Distributed Data Centers
Apr 27, 2025Worldwide, Geo-distributed Data Centers (GDCs) provide computing and storage services for massive workflow applications, resulting in high electricity costs that vary depending on geographical locations and time. How to reduce electricity costs while satisfying the deadline constraints of workflow applications is important in GDCs, which is determined by the execution time of servers, power, and electricity price. Determining the completion time of workflows with different server frequencies can be challenging, especially in scenarios with heterogeneous computing resources in GDCs. Moreover, the electricity price is also different in geographical locations and may change dynamically. To address these challenges, we develop a geo-distributed system architecture and propose an Electricity Cost aware Multiple Workflows Scheduling algorithm (ECMWS) for servers of GDCs with fixed frequency and power. ECMWS comprises four stages, namely workflow sequencing, deadline partitioning, task sequencing, and resource allocation where two graph embedding models and a policy network are constructed to solve the Markov Decision Process (MDP). After statistically calibrating parameters and algorithm components over a comprehensive set of workflow instances, the proposed algorithms are compared with the state-of-the-art methods over two types of workflow instances. The experimental results demonstrate that our proposed algorithm significantly outperforms other algorithms, achieving an improvement of over 15\% while maintaining an acceptable computational time. The source codes are available at https://gitee.com/public-artifacts/ecmws-experiments.
Generalization-aware Remote Sensing Change Detection via Domain-agnostic Learning
Apr 01, 2025Change detection has essential significance for the region's development, in which pseudo-changes between bitemporal images induced by imaging environmental factors are key challenges. Existing transformation-based methods regard pseudo-changes as a kind of style shift and alleviate it by transforming bitemporal images into the same style using generative adversarial networks (GANs). However, their efforts are limited by two drawbacks: 1) Transformed images suffer from distortion that reduces feature discrimination. 2) Alignment hampers the model from learning domain-agnostic representations that degrades performance on scenes with domain shifts from the training data. Therefore, oriented from pseudo-changes caused by style differences, we present a generalizable domain-agnostic difference learning network (DonaNet). For the drawback 1), we argue for local-level statistics as style proxies to assist against domain shifts. For the drawback 2), DonaNet learns domain-agnostic representations by removing domain-specific style of encoded features and highlighting the class characteristics of objects. In the removal, we propose a domain difference removal module to reduce feature variance while preserving discriminative properties and propose its enhanced version to provide possibilities for eliminating more style by decorrelating the correlation between features. In the highlighting, we propose a cross-temporal generalization learning strategy to imitate latent domain shifts, thus enabling the model to extract feature representations more robust to shifts actively. Extensive experiments conducted on three public datasets demonstrate that DonaNet outperforms existing state-of-the-art methods with a smaller model size and is more robust to domain shift.
Interpretable Deep Learning Paradigm for Airborne Transient Electromagnetic Inversion
Mar 28, 2025



The extraction of geoelectric structural information from airborne transient electromagnetic(ATEM)data primarily involves data processing and inversion. Conventional methods rely on empirical parameter selection, making it difficult to process complex field data with high noise levels. Additionally, inversion computations are time consuming and often suffer from multiple local minima. Existing deep learning-based approaches separate the data processing steps, where independently trained denoising networks struggle to ensure the reliability of subsequent inversions. Moreover, end to end networks lack interpretability. To address these issues, we propose a unified and interpretable deep learning inversion paradigm based on disentangled representation learning. The network explicitly decomposes noisy data into noise and signal factors, completing the entire data processing workflow based on the signal factors while incorporating physical information for guidance. This approach enhances the network's reliability and interpretability. The inversion results on field data demonstrate that our method can directly use noisy data to accurately reconstruct the subsurface electrical structure. Furthermore, it effectively processes data severely affected by environmental noise, which traditional methods struggle with, yielding improved lateral structural resolution.
DREMnet: An Interpretable Denoising Framework for Semi-Airborne Transient Electromagnetic Signal
Mar 28, 2025
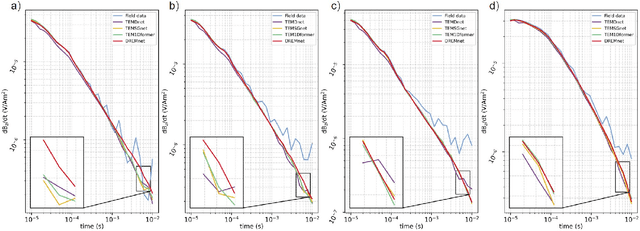


The semi-airborne transient electromagnetic method (SATEM) is capable of conducting rapid surveys over large-scale and hard-to-reach areas. However, the acquired signals are often contaminated by complex noise, which can compromise the accuracy of subsequent inversion interpretations. Traditional denoising techniques primarily rely on parameter selection strategies, which are insufficient for processing field data in noisy environments. With the advent of deep learning, various neural networks have been employed for SATEM signal denoising. However, existing deep learning methods typically use single-mapping learning approaches that struggle to effectively separate signal from noise. These methods capture only partial information and lack interpretability. To overcome these limitations, we propose an interpretable decoupled representation learning framework, termed DREMnet, that disentangles data into content and context factors, enabling robust and interpretable denoising in complex conditions. To address the limitations of CNN and Transformer architectures, we utilize the RWKV architecture for data processing and introduce the Contextual-WKV mechanism, which allows unidirectional WKV to perform bidirectional signal modeling. Our proposed Covering Embedding technique retains the strong local perception of convolutional networks through stacked embedding. Experimental results on test datasets demonstrate that the DREMnet method outperforms existing techniques, with processed field data that more accurately reflects the theoretical signal, offering improved identification of subsurface electrical structures.
ChangeDiff: A Multi-Temporal Change Detection Data Generator with Flexible Text Prompts via Diffusion Model
Dec 20, 2024



Data-driven deep learning models have enabled tremendous progress in change detection (CD) with the support of pixel-level annotations. However, collecting diverse data and manually annotating them is costly, laborious, and knowledge-intensive. Existing generative methods for CD data synthesis show competitive potential in addressing this issue but still face the following limitations: 1) difficulty in flexibly controlling change events, 2) dependence on additional data to train the data generators, 3) focus on specific change detection tasks. To this end, this paper focuses on the semantic CD (SCD) task and develops a multi-temporal SCD data generator ChangeDiff by exploring powerful diffusion models. ChangeDiff innovatively generates change data in two steps: first, it uses text prompts and a text-to-layout (T2L) model to create continuous layouts, and then it employs layout-to-image (L2I) to convert these layouts into images. Specifically, we propose multi-class distribution-guided text prompts (MCDG-TP), allowing for layouts to be generated flexibly through controllable classes and their corresponding ratios. Subsequently, to generalize the T2L model to the proposed MCDG-TP, a class distribution refinement loss is further designed as training supervision. %For the former, a multi-classdistribution-guided text prompt (MCDG-TP) is proposed to complement via controllable classes and ratios. To generalize the text-to-image diffusion model to the proposed MCDG-TP, a class distribution refinement loss is designed as training supervision. For the latter, MCDG-TP in three modes is proposed to synthesize new layout masks from various texts. Our generated data shows significant progress in temporal continuity, spatial diversity, and quality realism, empowering change detectors with accuracy and transferability. The code is available at https://github.com/DZhaoXd/ChangeDiff
SiamSeg: Self-Training with Contrastive Learning for Unsupervised Domain Adaptation in Remote Sensing
Oct 17, 2024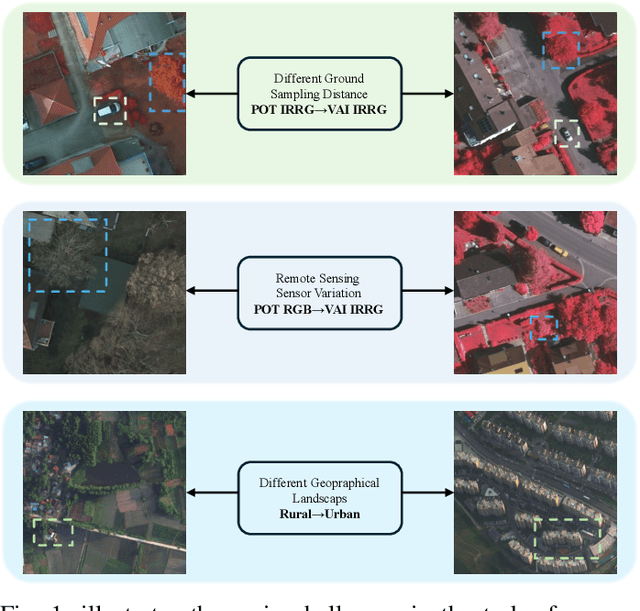
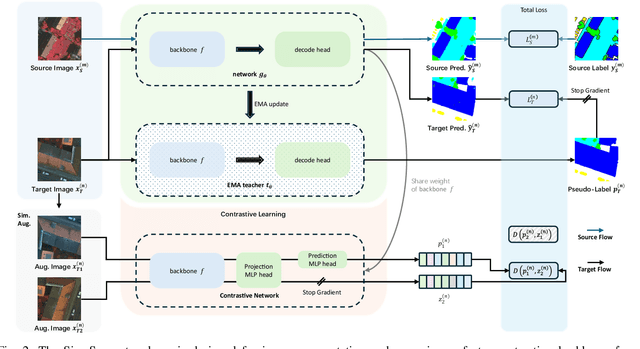
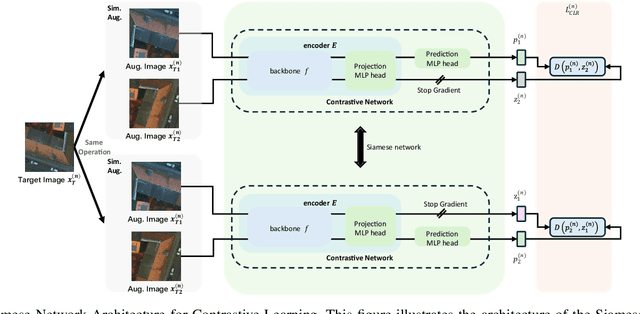
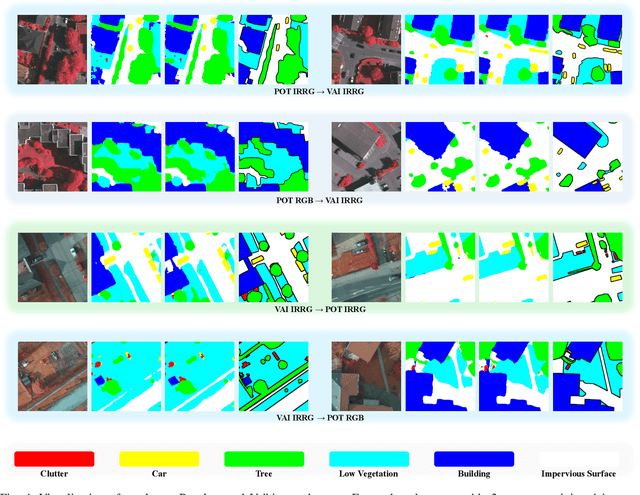
Semantic segmentation of remote sensing (RS) images is a challenging task with significant potential across various applications. Deep learning, especially supervised learning with large-scale labeled datasets, has greatly advanced this field. However, acquiring high-quality labeled data is expensive and time-consuming. Moreover, variations in ground sampling distance (GSD), imaging equipment, and geographic diversity contribute to domain shifts between datasets, which pose significant challenges to models trained solely on source domain data, leading to poor cross-domain performance. Domain shift is well-known for undermining a model's generalization ability in the target domain. To address this, unsupervised domain adaptation (UDA) has emerged as a promising solution, enabling models to learn from unlabeled target domain data while training on labeled source domain data. Recent advancements, particularly in self-supervised learning via pseudo-label generation, have shown potential in mitigating domain discrepancies. Strategies combining source and target domain images with their true and pseudo labels for self-supervised training have been effective in addressing domain bias. Despite progress in computer vision, the application of pseudo-labeling methods to RS image segmentation remains underexplored.
3-D Magnetotelluric Deep Learning Inversion Guided by Pseudo-Physical Information
Oct 12, 2024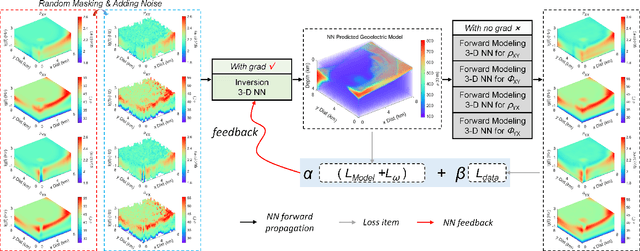
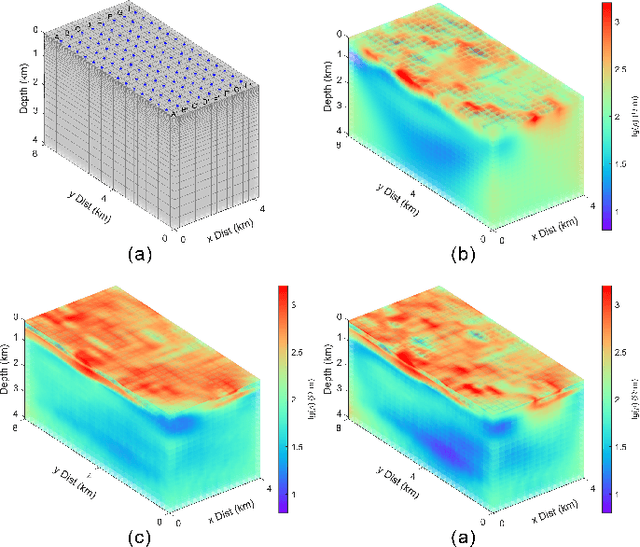
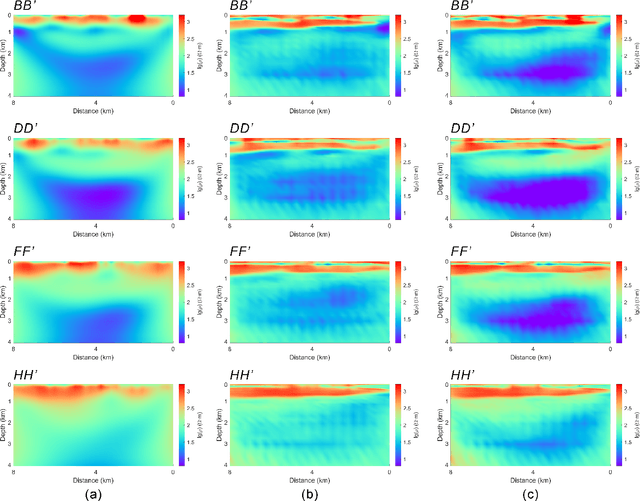
Magnetotelluric deep learning (DL) inversion methods based on joint data-driven and physics-driven have become a hot topic in recent years. When mapping observation data (or forward modeling data) to the resistivity model using neural networks (NNs), incorporating the error (loss) term of the inversion resistivity's forward modeling response--which introduces physical information about electromagnetic field propagation--can significantly enhance the inversion accuracy. To efficiently achieve data-physical dual-driven MT deep learning inversion for large-scale 3-D MT data, we propose using DL forward modeling networks to compute this portion of the loss. This approach introduces pseudo-physical information through the forward modeling of NN simulation, further guiding the inversion network fitting. Specifically, we first pre-train the forward modeling networks as fixed forward modeling operators, then transfer and integrate them into the inversion network training, and finally optimize the inversion network by minimizing the multinomial loss. Theoretical experimental results indicate that despite some simulation errors in DL forward modeling, the introduced pseudo-physical information still enhances inversion accuracy and significantly mitigates the overfitting problem during training. Additionally, we propose a new input mode that involves masking and adding noise to the data, simulating the field data environment of 3-D MT inversion, thereby making the method more flexible and effective for practical applications.