 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniScale: Synergistic Entire Space Data and Model Scaling for Search Ranking
Mar 25, 2026Recent advances in Large Language Models (LLMs) have inspired a surge of scaling law research in industrial search, advertising, and recommendation systems. However, existing approaches focus mainly on architectural improvements, overlooking the critical synergy between data and architecture design. We observe that scaling model parameters alone exhibits diminishing returns, i.e., the marginal gain in performance steadily declines as model size increases, and that the performance degradation caused by complex heterogeneous data distributions is often irrecoverable through model design alone. In this paper, we propose UniScale to address these limitation, a novel co-design framework that jointly optimizes data and architecture to unlock the full potential of model scaling, which includes two core parts: (1) ES$^3$ (Entire-Space Sample System), a high-quality data scaling system that expands the training signal beyond conventional sampling strategies from both intra-domain request contexts with global supervised signal constructed by hierarchical label attribution and cross-domain samples aligning with the essence of user decision under similar content exposure environment in search domain; and (2) HHSFT (Heterogeneous Hierarchical Sample Fusion Transformer), a novel architecture designed to effectively model the complex heterogeneous distribution of scaled data and to harness the entire space user behavior data with Heterogeneous Hierarchical Feature Interaction and Entire Space User Interest Fusion, thereby surpassing the performance ceiling of structure-only model tuning. Extensive experiments on large-scale real world E-commerce search platform demonstrate that UniScale achieves significant improvements through the synergistic co-design of data and architecture and exhibits clear scaling trends, delivering substantial gains in key business metrics.
KARMA: Knowledge-Action Regularized Multimodal Alignment for Personalized Search at Taobao
Mar 24, 2026Large Language Models (LLMs) are equipped with profound semantic knowledge, making them a natural choice for injecting semantic generalization into personalized search systems. However, in practice we find that directly fine-tuning LLMs on industrial personalized tasks (e.g. next item prediction) often yields suboptimal results. We attribute this bottleneck to a critical Knowledge--Action Gap: the inherent conflict between preserving pre-trained semantic knowledge and aligning with specific personalized actions by discriminative objectives. Empirically, action-only training objectives induce Semantic Collapse, such as attention ``sinks''. This degradation severely cripples the LLM's generalization, failing to bring improvements to personalized search systems. We propose KARMA (Knowledge--Action Regularized Multimodal Alignment), a unified framework that treats semantic reconstruction as a train-only regularizer. KARMA optimizes a next-interest embedding for retrieval (Action) while enforcing semantic decodability (Knowledge) through two complementary objectives: (i) history-conditioned semantic generation, which anchors optimization to the LLM's native next-token distribution, and (ii) embedding-conditioned semantic reconstruction, which constrains the interest embedding to remain semantically recoverable. On Taobao search system, KARMA mitigates semantic collapse (attention-sink analysis) and improves both action metrics and semantic fidelity. In ablations, semantic decodability yields up to +22.5 HR@200. With KARMA, we achieve +0.25 CTR AUC in ranking, +1.86 HR in pre-ranking and +2.51 HR in recalling. Deployed online with low inference overhead at ranking stage, KARMA drives +0.5% increase in Item Click.
SAEN-BGS: Energy-Efficient Spiking AutoEncoder Network for Background Subtraction
May 12, 2025Background subtraction (BGS) is utilized to detect moving objects in a video and is commonly employed at the onset of object tracking and human recognition processes. Nevertheless, existing BGS techniques utilizing deep learning still encounter challenges with various background noises in videos, including variations in lighting, shifts in camera angles, and disturbances like air turbulence or swaying trees. To address this problem, we design a spiking autoencoder network, termed SAEN-BGS, based on noise resilience and time-sequence sensitivity of spiking neural networks (SNNs) to enhance the separation of foreground and background. To eliminate unnecessary background noise and preserve the important foreground elements, we begin by creating the continuous spiking conv-and-dconv block, which serves as the fundamental building block for the decoder in SAEN-BGS. Moreover, in striving for enhanced energy efficiency, we introduce a novel self-distillation spiking supervised learning method grounded in ANN-to-SNN frameworks, resulting in decreased power consumption. In extensive experiments conducted on CDnet-2014 and DAVIS-2016 datasets, our approach demonstrates superior segmentation performance relative to other baseline methods, even when challenged by complex scenarios with dynamic backgrounds.
No More Tuning: Prioritized Multi-Task Learning with Lagrangian Differential Multiplier Methods
Dec 16, 2024



Given the ubiquity of multi-task in practical systems, Multi-Task Learning (MTL) has found widespread application across diverse domains. In real-world scenarios, these tasks often have different priorities. For instance, In web search, relevance is often prioritized over other metrics, such as click-through rates or user engagement. Existing frameworks pay insufficient attention to the prioritization among different tasks, which typically adjust task-specific loss function weights to differentiate task priorities. However, this approach encounters challenges as the number of tasks grows, leading to exponential increases in hyper-parameter tuning complexity. Furthermore, the simultaneous optimization of multiple objectives can negatively impact the performance of high-priority tasks due to interference from lower-priority tasks. In this paper, we introduce a novel multi-task learning framework employing Lagrangian Differential Multiplier Methods for step-wise multi-task optimization. It is designed to boost the performance of high-priority tasks without interference from other tasks. Its primary advantage lies in its ability to automatically optimize multiple objectives without requiring balancing hyper-parameters for different tasks, thereby eliminating the need for manual tuning. Additionally, we provide theoretical analysis demonstrating that our method ensures optimization guarantees, enhancing the reliability of the process. We demonstrate its effectiveness through experiments on multiple public datasets and its application in Taobao search, a large-scale industrial search ranking system, resulting in significant improvements across various business metrics.
SiamSeg: Self-Training with Contrastive Learning for Unsupervised Domain Adaptation in Remote Sensing
Oct 17, 2024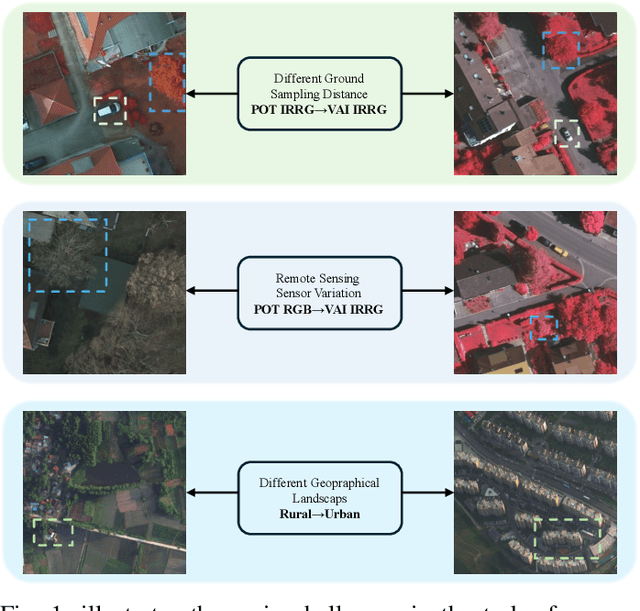
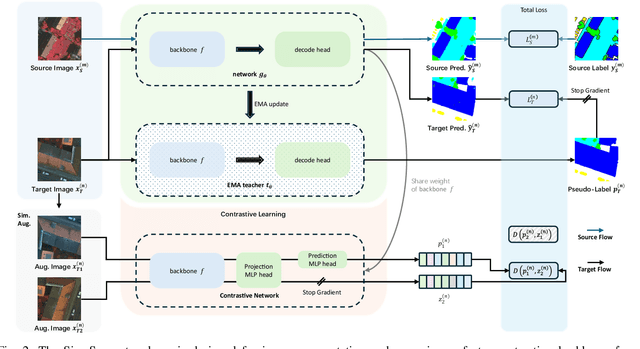
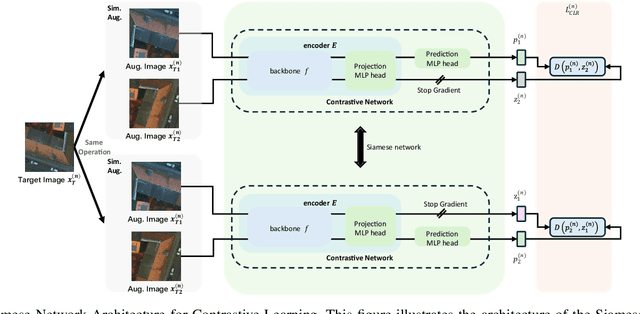
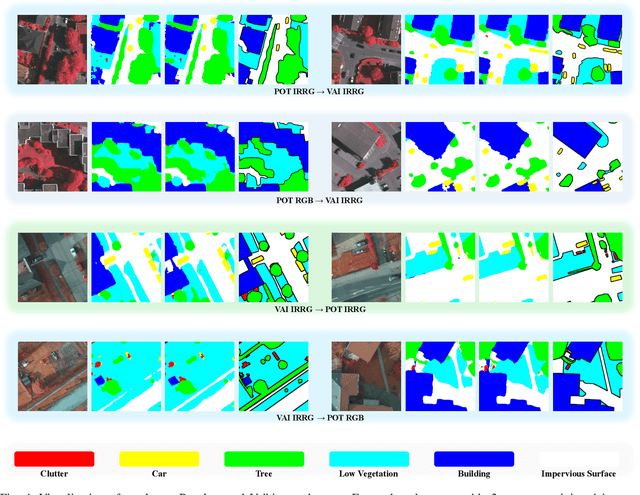
Semantic segmentation of remote sensing (RS) images is a challenging task with significant potential across various applications. Deep learning, especially supervised learning with large-scale labeled datasets, has greatly advanced this field. However, acquiring high-quality labeled data is expensive and time-consuming. Moreover, variations in ground sampling distance (GSD), imaging equipment, and geographic diversity contribute to domain shifts between datasets, which pose significant challenges to models trained solely on source domain data, leading to poor cross-domain performance. Domain shift is well-known for undermining a model's generalization ability in the target domain. To address this, unsupervised domain adaptation (UDA) has emerged as a promising solution, enabling models to learn from unlabeled target domain data while training on labeled source domain data. Recent advancements, particularly in self-supervised learning via pseudo-label generation, have shown potential in mitigating domain discrepancies. Strategies combining source and target domain images with their true and pseudo labels for self-supervised training have been effective in addressing domain bias. Despite progress in computer vision, the application of pseudo-labeling methods to RS image segmentation remains underexplored.
Rethinking the Role of Pre-ranking in Large-scale E-Commerce Searching System
May 23, 2023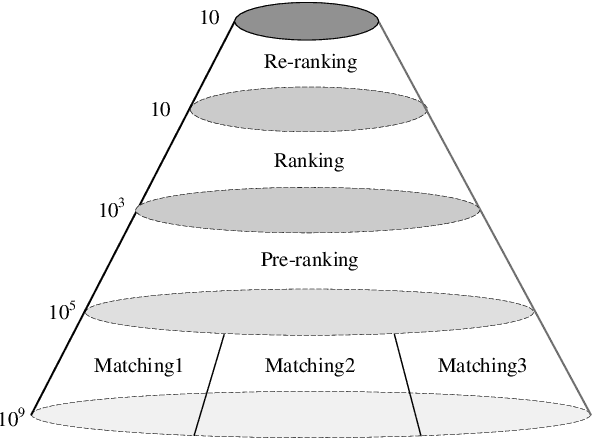
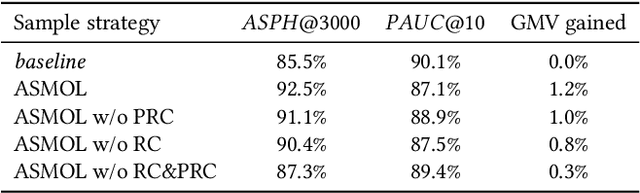
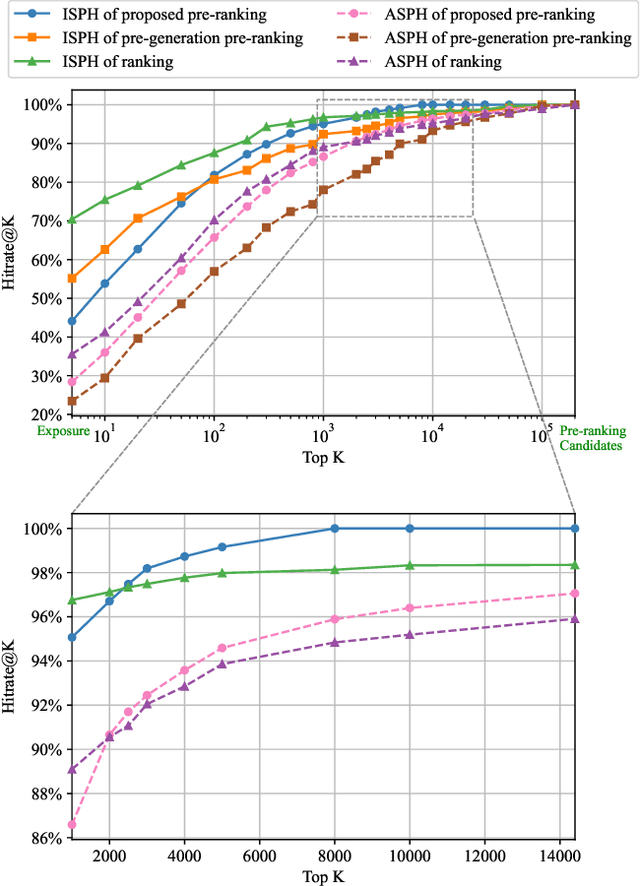
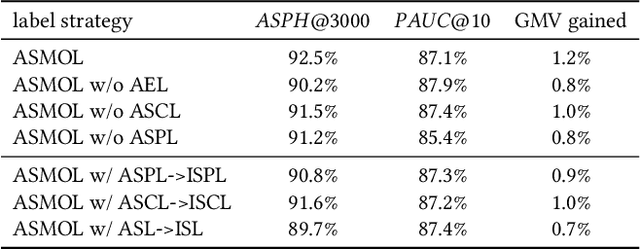
E-commerce search systems such as Taobao Search, the largest e-commerce searching system in China, aim at providing users with the most preferred items (e.g., products). Due to the massive data and limited time for response, a typical industrial ranking system consists of three or more modules, including matching, pre-ranking, and ranking. The pre-ranking is widely considered a mini-ranking module, as it needs to rank hundreds of times more items than the ranking under limited latency. Existing researches focus on building a lighter model that imitates the ranking model. As such, the metric of a pre-ranking model follows the ranking model using Area Under ROC (AUC) for offline evaluation. However, such a metric is inconsistent with online A/B tests in practice, so engineers have to perform costly online tests to reach a convincing conclusion. In our work, we rethink the role of the pre-ranking. We argue that the primary goal of the pre-ranking stage is to return an optimal unordered set rather than an ordered list of items because it is the ranking that determines the final exposures. Since AUC measures the quality of an ordered item list, it is not suitable for evaluating the quality of the output unordered set. This paper proposes a new evaluation metric called All-Scenario Hitrate (ASH) for pre-ranking. ASH is proven effective in the offline evaluation and consistent with online A/B tests based on numerous experiments in Taobao Search. We also introduce an all-scenario-based multi-objective learning framework (ASMOL), which improves the ASH significantly. Surprisingly, the new pre-ranking model can outperforms the ranking model when outputting thousands of items. The phenomenon validates that the pre-ranking stage should not imitate the ranking blindly. With the improvements in ASH consistently translating to online improvement, it makes a 1.2% GMV improvement on Taobao Search.
Multi-Objective Personalized Product Retrieval in Taobao Search
Oct 09, 2022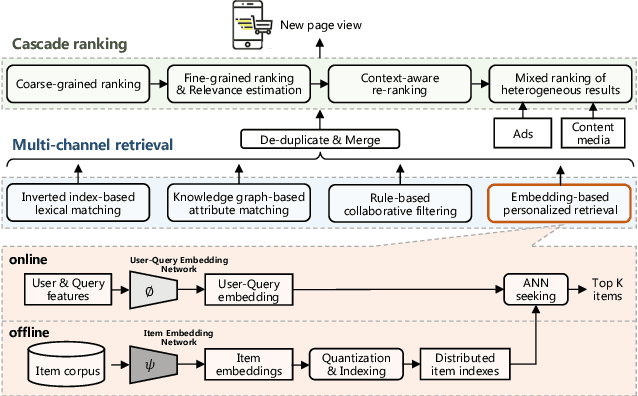

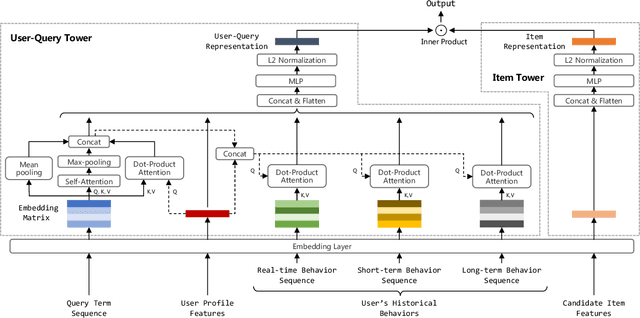

In large-scale e-commerce platforms like Taobao, it is a big challenge to retrieve products that satisfy users from billions of candidates. This has been a common concern of academia and industry. Recently, plenty of works in this domain have achieved significant improvements by enhancing embedding-based retrieval (EBR) methods, including the Multi-Grained Deep Semantic Product Retrieval (MGDSPR) model [16] in Taobao search engine. However, we find that MGDSPR still has problems of poor relevance and weak personalization compared to other retrieval methods in our online system, such as lexical matching and collaborative filtering. These problems promote us to further strengthen the capabilities of our EBR model in both relevance estimation and personalized retrieval. In this paper, we propose a novel Multi-Objective Personalized Product Retrieval (MOPPR) model with four hierarchical optimization objectives: relevance, exposure, click and purchase. We construct entire-space multi-positive samples to train MOPPR, rather than the single-positive samples for existing EBR models.We adopt a modified softmax loss for optimizing multiple objectives. Results of extensive offline and online experiments show that MOPPR outperforms the baseline MGDSPR on evaluation metrics of relevance estimation and personalized retrieval. MOPPR achieves 0.96% transaction and 1.29% GMV improvements in a 28-day online A/B test. Since the Double-11 shopping festival of 2021, MOPPR has been fully deployed in mobile Taobao search, replacing the previous MGDSPR. Finally, we discuss several advanced topics of our deeper explorations on multi-objective retrieval and ranking to contribute to the community.
GeneAnnotator: A Semi-automatic Annotation Tool for Visual Scene Graph
Sep 06, 2021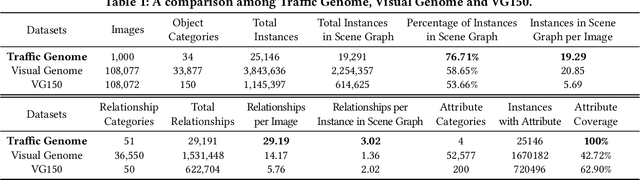
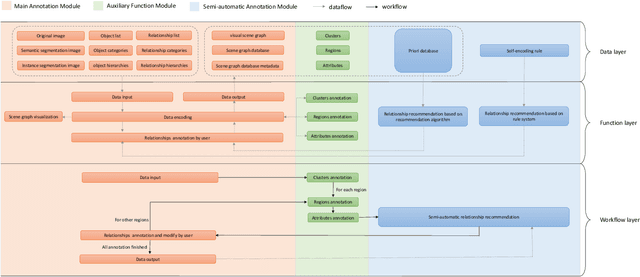
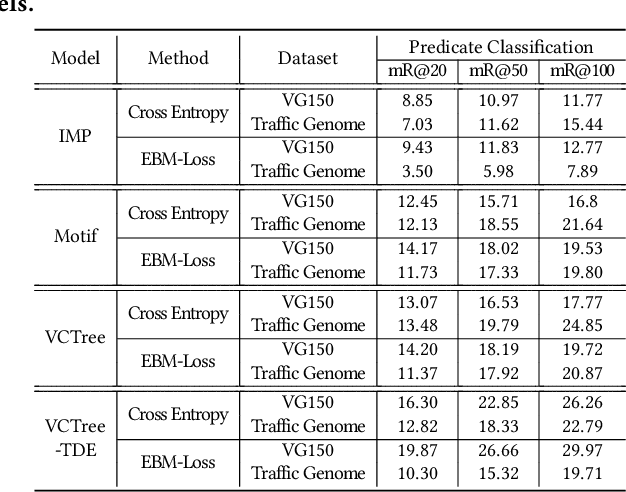
In this manuscript, we introduce a semi-automatic scene graph annotation tool for images, the GeneAnnotator. This software allows human annotators to describe the existing relationships between participators in the visual scene in the form of directed graphs, hence enabling the learning and reasoning on visual relationships, e.g., image captioning, VQA and scene graph generation, etc. The annotations for certain image datasets could either be merged in a single VG150 data-format file to support most existing models for scene graph learning or transformed into a separated annotation file for each single image to build customized datasets. Moreover, GeneAnnotator provides a rule-based relationship recommending algorithm to reduce the heavy annotation workload. With GeneAnnotator, we propose Traffic Genome, a comprehensive scene graph dataset with 1000 diverse traffic images, which in return validates the effectiveness of the proposed software for scene graph annotation. The project source code, with usage examples and sample data is available at https://github.com/Milomilo0320/A-Semi-automatic-Annotation-Software-for-Scene-Graph, under the Apache open-source license.
Spike-Timing-Dependent Back Propagation in Deep Spiking Neural Networks
Mar 26, 2020



The success of Deep Neural Networks (DNNs) can be attributed to its deep structure, that learns invariant feature representation at multiple levels of abstraction. Brain-inspired Spiking Neural Networks (SNNs) use spatiotemporal spike patterns to encode and transmit information, which is biologically realistic, and suitable for ultra-low-power event-driven neuromorphic implementation. Therefore, Deep Spiking Neural Networks (DSNNs) represent a promising direction in artificial intelligence, with the potential to benefit from the best of both worlds. However, the training of DSNNs is challenging because standard error back-propagation (BP) algorithms are not directly applicable. In this paper, we first establish an understanding of why error back-propagation does not work well in DSNNs. To address this problem, we propose a simple yet efficient Rectified Linear Postsynaptic Potential function (ReL-PSP) for spiking neurons and propose a Spike-Timing-Dependent Back-Propagation (STDBP) learning algorithm for DSNNs. In the proposed learning algorithm, the timing of individual spikes is used to carry information (temporal coding), and learning (back-propagation) is performed based on spike timing in an event-driven manner. Experimental results demonstrate that the proposed learning algorithm achieves state-of-the-art performance in spike time based learning algorithms of SNNs. This work investigates the contribution of dynamics in spike timing to information encoding, synaptic plasticity and decision making, providing a new perspective to design of future DSNNs.