 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modality Sensing in mmWave Beamforming for Connected Vehicles Using Deep Learning
Apr 08, 2025



Beamforming techniques are considered as essential parts to compensate severe path losses in millimeter-wave (mmWave) communications. In particular, these techniques adopt large antenna arrays and formulate narrow beams to obtain satisfactory received powers. However, performing accurate beam alignment over narrow beams for efficient link configuration by traditional standard defined beam selection approaches, which mainly rely on channel state information and beam sweeping through exhaustive searching, imposes computational and communications overheads. And, such resulting overheads limit their potential use in vehicle-to-infrastructure (V2I) and vehicle-to-vehicle (V2V) communications involving highly dynamic scenarios. In comparison, utilizing out-of-band contextual information, such as sensing data obtained from sensor devices, provides a better alternative to reduce overheads. This paper presents a deep learning-based solution for utilizing the multi-modality sensing data for predicting the optimal beams having sufficient mmWave received powers so that the best V2I and V2V line-of-sight links can be ensured proactively. The proposed solution has been tested on real-world measured mmWave sensing and communication data, and the results show that it can achieve up to 98.19% accuracies while predicting top-13 beams. Correspondingly, when compared to existing been sweeping approach, the beam sweeping searching space and time overheads are greatly shortened roughly by 79.67% and 91.89%, respectively which confirm a promising solution for beamforming in mmWave enabled communications.
* 15 Pages
Position Aware 60 GHz mmWave Beamforming for V2V Communications Utilizing Deep Learning
Feb 02, 2024



Beamforming techniques are considered as essential parts to compensate the severe path loss in millimeter-wave (mmWave) communications by adopting large antenna arrays and formulating narrow beams to obtain satisfactory received powers. However, performing accurate beam alignment over such narrow beams for efficient link configuration by traditional beam selection approaches, mainly relied on channel state information, typically impose significant latency and computing overheads, which is often infeasible in vehicle-to-vehicle (V2V) communications like highly dynamic scenarios. In contrast, utilizing out-of-band contextual information, such as vehicular position information, is a potential alternative to reduce such overheads. In this context, this paper presents a deep learning-based solution on utilizing the vehicular position information for predicting the optimal beams having sufficient mmWave received powers so that the best V2V line-of-sight links can be ensured proactively. After experimental evaluation of the proposed solution on real-world measured mmWave sensing and communications datasets, the results show that the solution can achieve up to 84.58% of received power of link status on average, which confirm a promising solution for beamforming in mmWave at 60 GHz enabled V2V communications.
Masked Multi-Step Probabilistic Forecasting for Short-to-Mid-Term Electricity Demand
Feb 14, 2023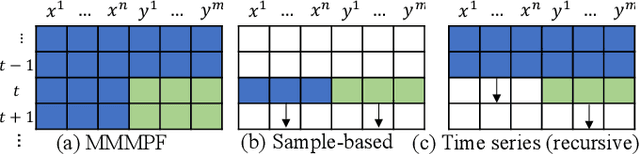
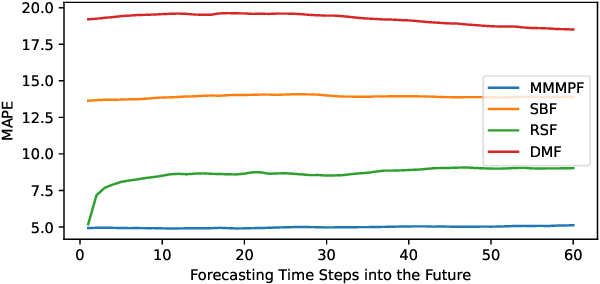
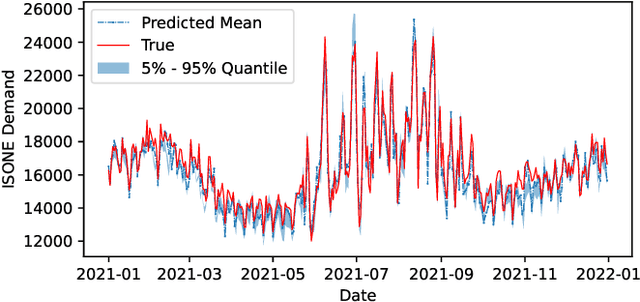
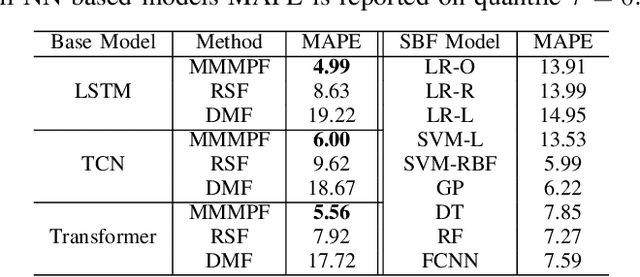
Predicting the demand for electricity with uncertainty helps in planning and operation of the grid to provide reliable supply of power to the consumers. Machine learning (ML)-based demand forecasting approaches can be categorized into (1) sample-based approaches, where each forecast is made independently, and (2) time series regression approaches, where some historical load and other feature information is used. When making a short-to-mid-term electricity demand forecast, some future information is available, such as the weather forecast and calendar variables. However, in existing forecasting models this future information is not fully incorporated. To overcome this limitation of existing approaches, we propose Masked Multi-Step Multivariate Probabilistic Forecasting (MMMPF), a novel and general framework to train any neural network model capable of generating a sequence of outputs, that combines both the temporal information from the past and the known information about the future to make probabilistic predictions. Experiments are performed on a real-world dataset for short-to-mid-term electricity demand forecasting for multiple regions and compared with various ML methods. They show that the proposed MMMPF framework outperforms not only sample-based methods but also existing time-series forecasting models with the exact same base models. Models trainded with MMMPF can also generate desired quantiles to capture uncertainty and enable probabilistic planning for grid of the future.
Multi-Objective Personalized Product Retrieval in Taobao Search
Oct 09, 2022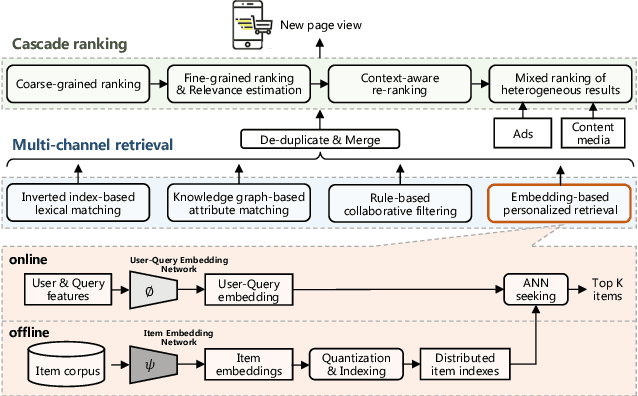

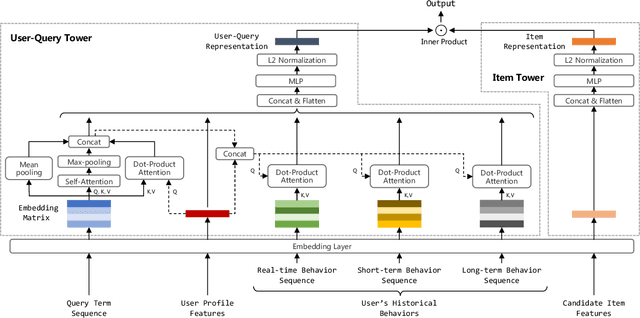

In large-scale e-commerce platforms like Taobao, it is a big challenge to retrieve products that satisfy users from billions of candidates. This has been a common concern of academia and industry. Recently, plenty of works in this domain have achieved significant improvements by enhancing embedding-based retrieval (EBR) methods, including the Multi-Grained Deep Semantic Product Retrieval (MGDSPR) model [16] in Taobao search engine. However, we find that MGDSPR still has problems of poor relevance and weak personalization compared to other retrieval methods in our online system, such as lexical matching and collaborative filtering. These problems promote us to further strengthen the capabilities of our EBR model in both relevance estimation and personalized retrieval. In this paper, we propose a novel Multi-Objective Personalized Product Retrieval (MOPPR) model with four hierarchical optimization objectives: relevance, exposure, click and purchase. We construct entire-space multi-positive samples to train MOPPR, rather than the single-positive samples for existing EBR models.We adopt a modified softmax loss for optimizing multiple objectives. Results of extensive offline and online experiments show that MOPPR outperforms the baseline MGDSPR on evaluation metrics of relevance estimation and personalized retrieval. MOPPR achieves 0.96% transaction and 1.29% GMV improvements in a 28-day online A/B test. Since the Double-11 shopping festival of 2021, MOPPR has been fully deployed in mobile Taobao search, replacing the previous MGDSPR. Finally, we discuss several advanced topics of our deeper explorations on multi-objective retrieval and ranking to contribute to the community.
Masked Multi-Step Multivariate Time Series Forecasting with Future Information
Sep 28, 2022

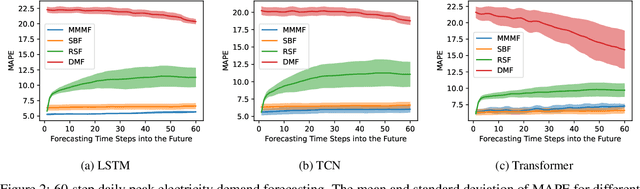

In this paper, we introduce Masked Multi-Step Multivariate Forecasting (MMMF), a novel and general self-supervised learning framework for time series forecasting with known future information. In many real-world forecasting scenarios, some future information is known, e.g., the weather information when making a short-to-mid-term electricity demand forecast, or the oil price forecasts when making an airplane departure forecast. Existing machine learning forecasting frameworks can be categorized into (1) sample-based approaches where each forecast is made independently, and (2) time series regression approaches where the future information is not fully incorporated. To overcome the limitations of existing approaches, we propose MMMF, a framework to train any neural network model capable of generating a sequence of outputs, that combines both the temporal information from the past and the known information about the future to make better predictions. Experiments are performed on two real-world datasets for (1) mid-term electricity demand forecasting, and (2) two-month ahead flight departures forecasting. They show that the proposed MMMF framework outperforms not only sample-based methods but also existing time series forecasting models with the exact same base models. Furthermore, once a neural network model is trained with MMMF, its inference speed is similar to that of the same model trained with traditional regression formulations, thus making MMMF a better alternative to existing regression-trained time series forecasting models if there is some available future information.
Fast communication-efficient spectral clustering over distributed data
May 05, 2019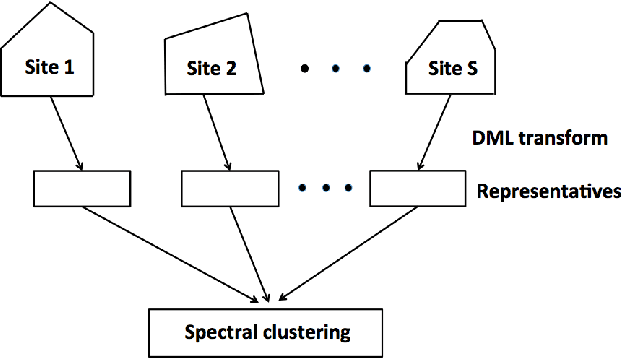
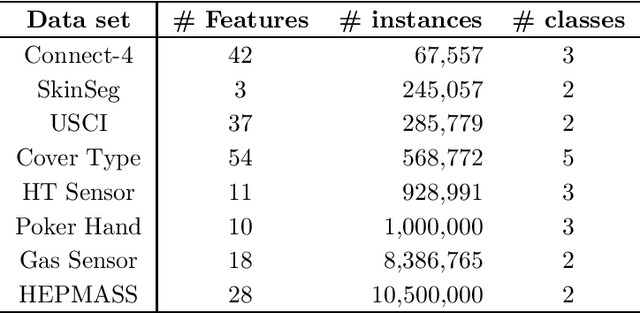
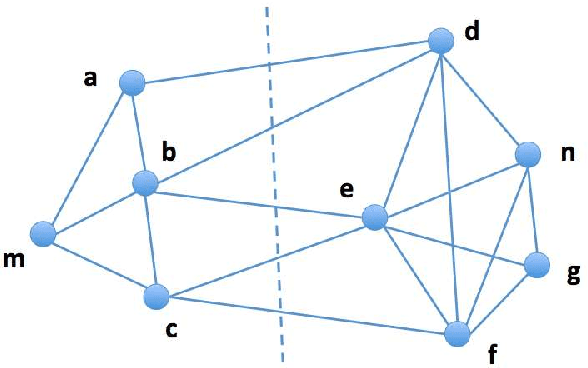
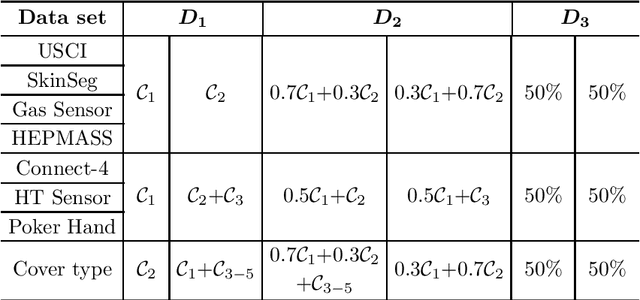
The last decades have seen a surge of interests in distributed computing thanks to advances in clustered computing and big data technology. Existing distributed algorithms typically assume {\it all the data are already in one place}, and divide the data and conquer on multiple machines. However, it is increasingly often that the data are located at a number of distributed sites, and one wishes to compute over all the data with low communication overhead. For spectral clustering, we propose a novel framework that enables its computation over such distributed data, with "minimal" communications while a major speedup in computation. The loss in accuracy is negligible compared to the non-distributed setting. Our approach allows local parallel computing at where the data are located, thus turns the distributed nature of the data into a blessing; the speedup is most substantial when the data are evenly distributed across sites. Experiments on synthetic and large UC Irvine datasets show almost no loss in accuracy with our approach while about 2x speedup under various settings with two distributed sites. As the transmitted data need not be in their original form, our framework readily addresses the privacy concern for data sharing in distributed computing.
* 27 pages, 7 figures
K-nearest Neighbor Search by Random Projection Forests
Dec 31, 2018

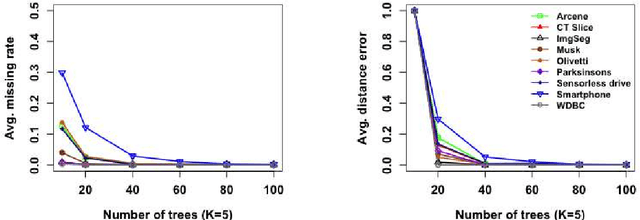
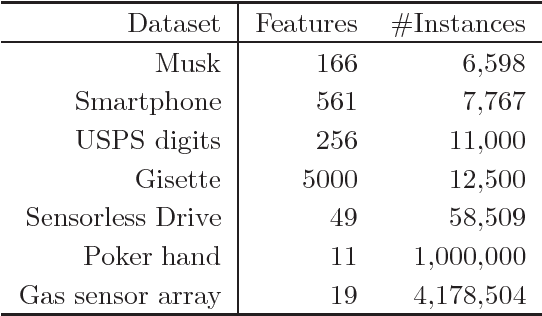
K-nearest neighbor (kNN) search has wide applications in many areas, including data mining, machine learning, statistics and many applied domains. Inspired by the success of ensemble methods and the flexibility of tree-based methodology, we propose random projection forests (rpForests), for kNN search. rpForests finds kNNs by aggregating results from an ensemble of random projection trees with each constructed recursively through a series of carefully chosen random projections. rpForests achieves a remarkable accuracy in terms of fast decay in the missing rate of kNNs and that of discrepancy in the kNN distances. rpForests has a very low computational complexity. The ensemble nature of rpForests makes it easily run in parallel on multicore or clustered computers; the running time is expected to be nearly inversely proportional to the number of cores or machines. We give theoretical insights by showing the exponential decay of the probability that neighboring points would be separated by ensemble random projection trees when the ensemble size increases. Our theory can be used to refine the choice of random projections in the growth of trees, and experiments show that the effect is remarkable.
Automatic Objects Removal for Scene Completion
Jan 23, 2015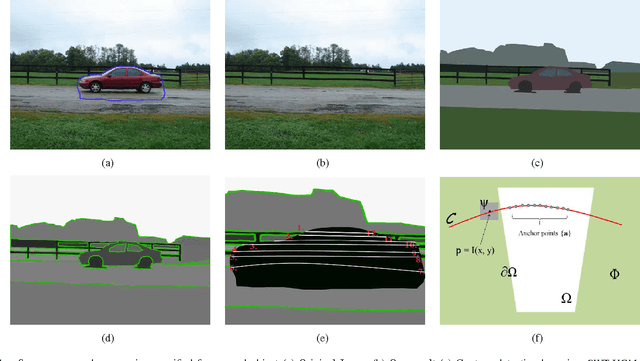

With the explosive growth of web-based cameras and mobile devices, billions of photographs are uploaded to the internet. We can trivially collect a huge number of photo streams for various goals, such as 3D scene reconstruction and other big data applications. However, this is not an easy task due to the fact the retrieved photos are neither aligned nor calibrated. Furthermore, with the occlusion of unexpected foreground objects like people, vehicles, it is even more challenging to find feature correspondences and reconstruct realistic scenes. In this paper, we propose a structure based image completion algorithm for object removal that produces visually plausible content with consistent structure and scene texture. We use an edge matching technique to infer the potential structure of the unknown region. Driven by the estimated structure, texture synthesis is performed automatically along the estimated curves. We evaluate the proposed method on different types of images: from highly structured indoor environment to the natural scenes. Our experimental results demonstrate satisfactory performance that can be potentially used for subsequent big data processing: 3D scene reconstruction and location recognition.