 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIDE: A Vision-Driven Multi-View, Multi-Modal, Multi-Tasking Dataset for Assistive Driving Perception
Aug 01, 2023



Driver distraction has become a significant cause of severe traffic accidents over the past decade. Despite the growing development of vision-driven driver monitoring systems, the lack of comprehensive perception datasets restricts road safety and traffic security. In this paper, we present an AssIstive Driving pErception dataset (AIDE) that considers context information both inside and outside the vehicle in naturalistic scenarios. AIDE facilitates holistic driver monitoring through three distinctive characteristics, including multi-view settings of driver and scene, multi-modal annotations of face, body, posture, and gesture, and four pragmatic task designs for driving understanding. To thoroughly explore AIDE, we provide experimental benchmarks on three kinds of baseline frameworks via extensive methods. Moreover, two fusion strategies are introduced to give new insights into learning effective multi-stream/modal representations. We also systematically investigate the importance and rationality of the key components in AIDE and benchmarks. The project link is https://github.com/ydk122024/AIDE.
Learning Low-dimensional Manifolds for Scoring of Tissue Microarray Images
Feb 22, 2021
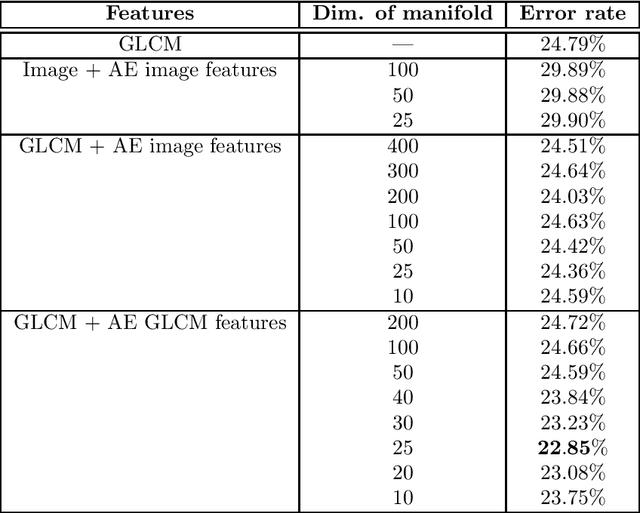
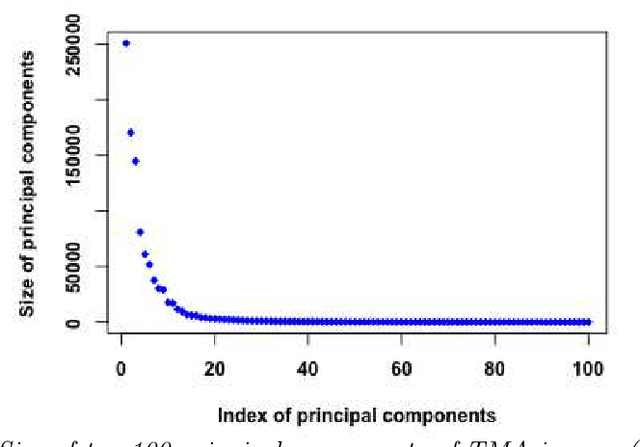
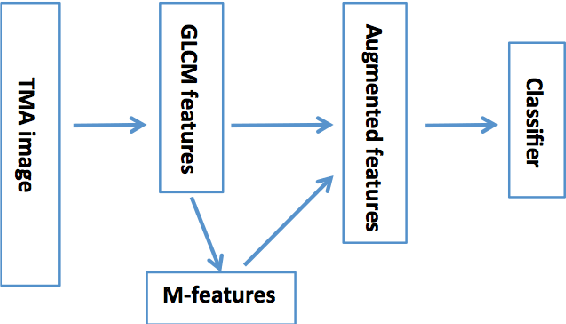
Tissue microarray (TMA) images have emerged as an important high-throughput tool for cancer study and the validation of biomarkers. Efforts have been dedicated to further improve the accuracy of TACOMA, a cutting-edge automatic scoring algorithm for TMA images. One major advance is due to deepTacoma, an algorithm that incorporates suitable deep representations of a group nature. Inspired by the recent advance in semi-supervised learning and deep learning, we propose mfTacoma to learn alternative deep representations in the context of TMA image scoring. In particular, mfTacoma learns the low-dimensional manifolds, a common latent structure in high dimensional data. Deep representation learning and manifold learning typically requires large data. By encoding deep representation of the manifolds as regularizing features, mfTacoma effectively leverages the manifold information that is potentially crude due to small data. Our experiments show that deep features by manifolds outperforms two alternatives -- deep features by linear manifolds with principal component analysis or by leveraging the group property.
Domain Adaptation with Incomplete Target Domains
Dec 03, 2020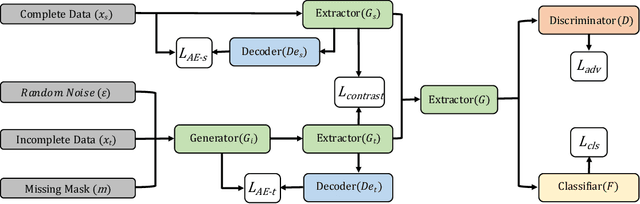
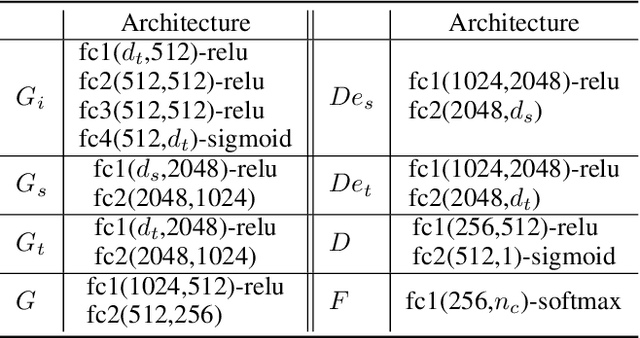
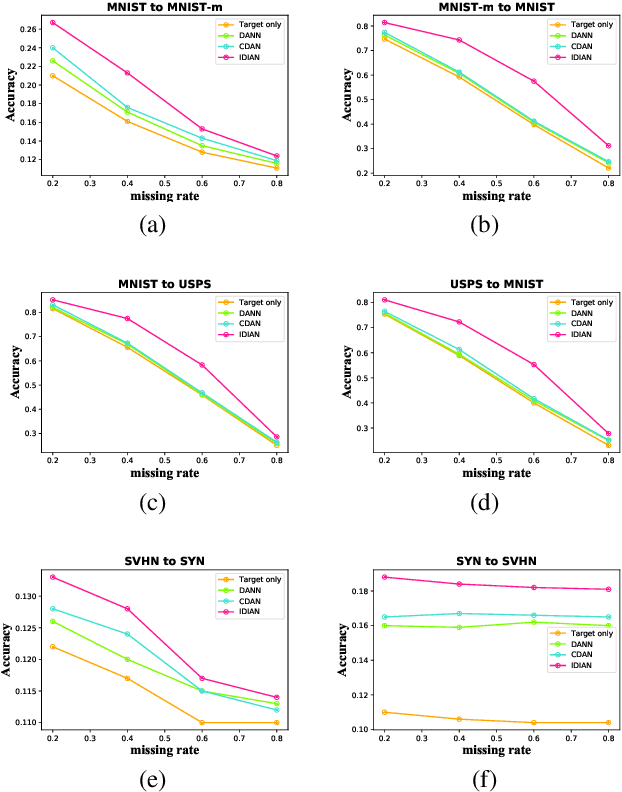

Domain adaptation, as a task of reducing the annotation cost in a target domain by exploiting the existing labeled data in an auxiliary source domain, has received a lot of attention in the research community. However, the standard domain adaptation has assumed perfectly observed data in both domains, while in real world applications the existence of missing data can be prevalent. In this paper, we tackle a more challenging domain adaptation scenario where one has an incomplete target domain with partially observed data. We propose an Incomplete Data Imputation based Adversarial Network (IDIAN) model to address this new domain adaptation challenge. In the proposed model, we design a data imputation module to fill the missing feature values based on the partial observations in the target domain, while aligning the two domains via deep adversarial adaption. We conduct experiments on both cross-domain benchmark tasks and a real world adaptation task with imperfect target domains. The experimental results demonstrate the effectiveness of the proposed method.
A Transductive Multi-Head Model for Cross-Domain Few-Shot Learning
Jun 08, 2020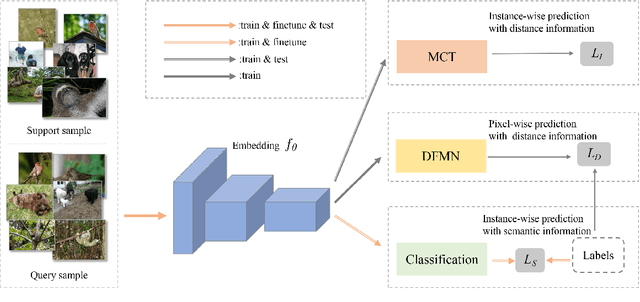
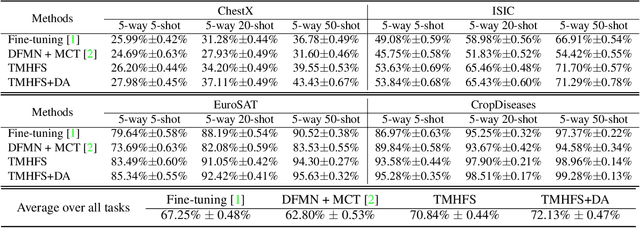
In this paper, we present a new method, Transductive Multi-Head Few-Shot learning (TMHFS), to address the Cross-Domain Few-Shot Learning (CD-FSL) challenge. The TMHFS method extends the Meta-Confidence Transduction (MCT) and Dense Feature-Matching Networks (DFMN) method [2] by introducing a new prediction head, i.e, an instance-wise global classification network based on semantic information, after the common feature embedding network. We train the embedding network with the multiple heads, i.e,, the MCT loss, the DFMN loss and the semantic classifier loss, simultaneously in the source domain. For the few-shot learning in the target domain, we first perform fine-tuning on the embedding network with only the semantic global classifier and the support instances, and then use the MCT part to predict labels of the query set with the fine-tuned embedding network. Moreover, we further exploit data augmentation techniques during the fine-tuning and test stages to improve the prediction performance. The experimental results demonstrate that the proposed methods greatly outperform the strong baseline, fine-tuning, on four different target domains.
Feature Transformation Ensemble Model with Batch Spectral Regularization for Cross-Domain Few-Shot Classification
May 21, 2020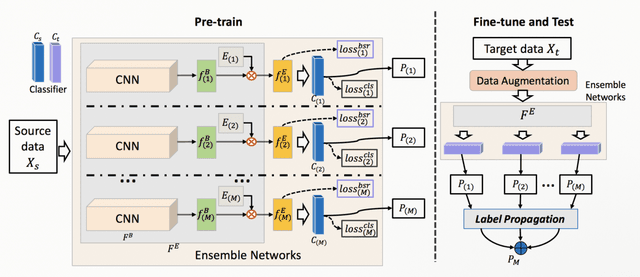
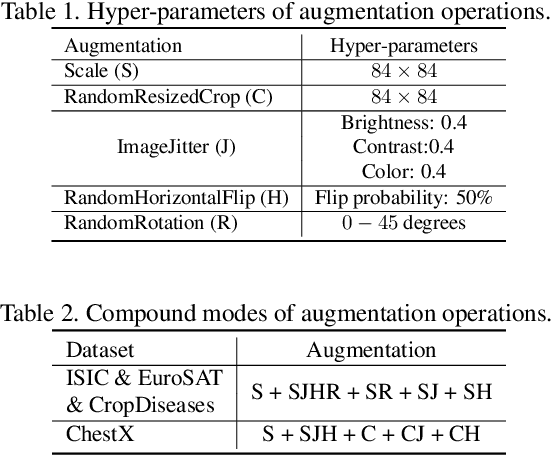
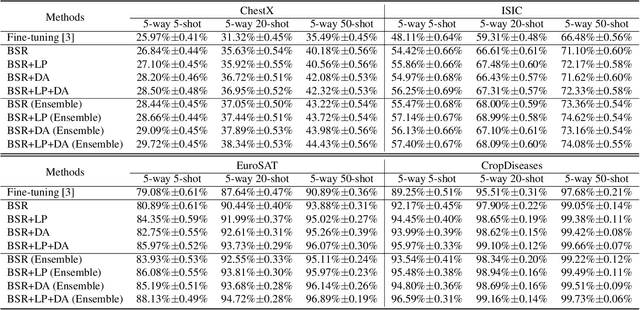
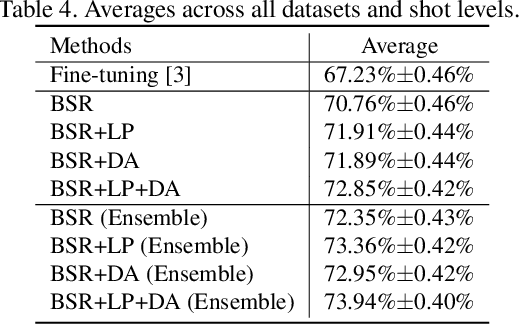
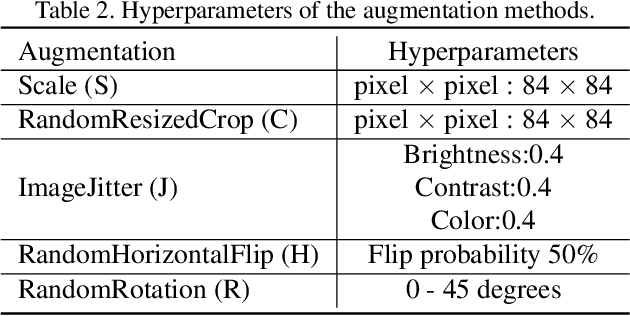
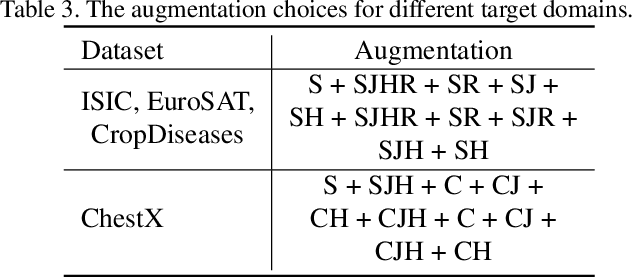
In this paper, we propose a feature transformation ensemble model with batch spectral regularization for the Cross-domain few-shot learning (CD-FSL) challenge. Specifically, we proposes to construct an ensemble prediction model by performing diverse feature transformations after a feature extraction network. On each branch prediction network of the model we use a batch spectral regularization term to suppress the singular values of the feature matrix during pre-training to improve the generalization ability of the model. The proposed model can then be fine tuned in the target domain to address few-shot classification. We also further apply label propagation, entropy minimization and data augmentation to mitigate the shortage of labeled data in target domains. Experiments are conducted on a number of CD-FSL benchmark tasks with four target domains and the results demonstrate the superiority of our proposed model.
Mutual Learning Network for Multi-Source Domain Adaptation
Mar 29, 2020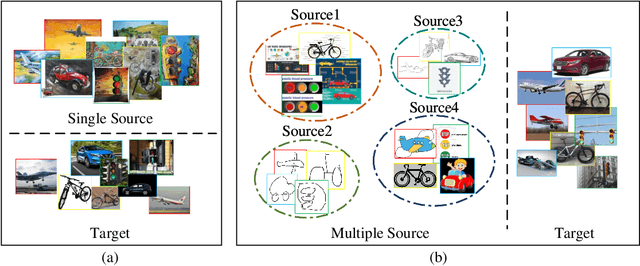

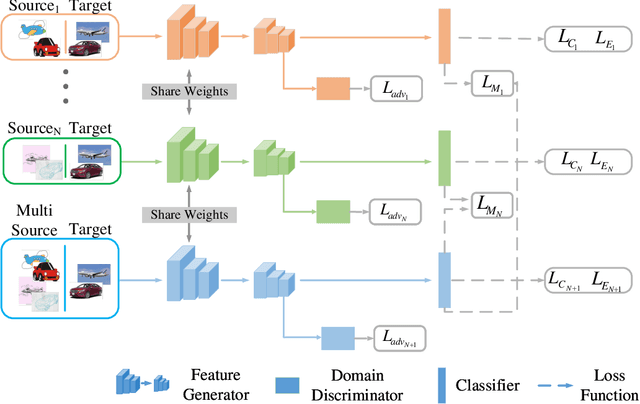
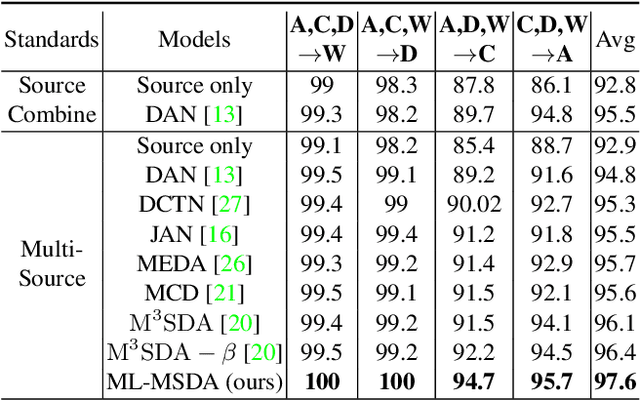
Early Unsupervised Domain Adaptation (UDA) methods have mostly assumed the setting of a single source domain, where all the labeled source data come from the same distribution. However, in practice the labeled data can come from multiple source domains with different distributions. In such scenarios, the single source domain adaptation methods can fail due to the existence of domain shifts across different source domains and multi-source domain adaptation methods need to be designed. In this paper, we propose a novel multi-source domain adaptation method, Mutual Learning Network for Multiple Source Domain Adaptation (ML-MSDA). Under the framework of mutual learning, the proposed method pairs the target domain with each single source domain to train a conditional adversarial domain adaptation network as a branch network, while taking the pair of the combined multi-source domain and target domain to train a conditional adversarial adaptive network as the guidance network. The multiple branch networks are aligned with the guidance network to achieve mutual learning by enforcing JS-divergence regularization over their prediction probability distributions on the corresponding target data. We conduct extensive experiments on multiple multi-source domain adaptation benchmark datasets. The results show the proposed ML-MSDA method outperforms the comparison methods and achieves the state-of-the-art performance.
K-nearest Neighbor Search by Random Projection Forests
Dec 31, 2018

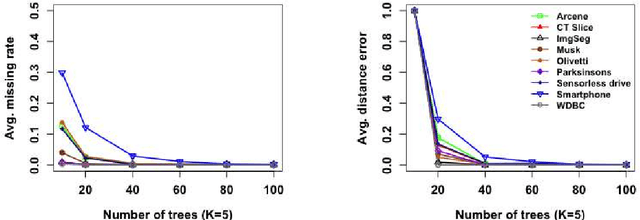
K-nearest neighbor (kNN) search has wide applications in many areas, including data mining, machine learning, statistics and many applied domains. Inspired by the success of ensemble methods and the flexibility of tree-based methodology, we propose random projection forests (rpForests), for kNN search. rpForests finds kNNs by aggregating results from an ensemble of random projection trees with each constructed recursively through a series of carefully chosen random projections. rpForests achieves a remarkable accuracy in terms of fast decay in the missing rate of kNNs and that of discrepancy in the kNN distances. rpForests has a very low computational complexity. The ensemble nature of rpForests makes it easily run in parallel on multicore or clustered computers; the running time is expected to be nearly inversely proportional to the number of cores or machines. We give theoretical insights by showing the exponential decay of the probability that neighboring points would be separated by ensemble random projection trees when the ensemble size increases. Our theory can be used to refine the choice of random projections in the growth of trees, and experiments show that the effect is remarkable.