 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiGR: Efficient Generative Slate Recommendation via Hierarchical Planning and Multi-Objective Preference Alignment
Dec 31, 2025Slate recommendation, where users are presented with a ranked list of items simultaneously, is widely adopted in online platforms. Recent advances in generative models have shown promise in slate recommendation by modeling sequences of discrete semantic IDs autoregressively. However, existing autoregressive approaches suffer from semantically entangled item tokenization and inefficient sequential decoding that lacks holistic slate planning. To address these limitations, we propose HiGR, an efficient generative slate recommendation framework that integrates hierarchical planning with listwise preference alignment. First, we propose an auto-encoder utilizing residual quantization and contrastive constraints to tokenize items into semantically structured IDs for controllable generation. Second, HiGR decouples generation into a list-level planning stage for global slate intent, followed by an item-level decoding stage for specific item selection. Third, we introduce a listwise preference alignment objective to directly optimize slate quality using implicit user feedback. Experiments on our large-scale commercial media platform demonstrate that HiGR delivers consistent improvements in both offline evaluations and online deployment. Specifically, it outperforms state-of-the-art methods by over 10% in offline recommendation quality with a 5x inference speedup, while further achieving a 1.22% and 1.73% increase in Average Watch Time and Average Video Views in online A/B tests.
MixDec Sampling: A Soft Link-based Sampling Method of Graph Neural Network for Recommendation
Feb 12, 2025Graph neural networks have been widely used in recent recommender systems, where negative sampling plays an important role. Existing negative sampling methods restrict the relationship between nodes as either hard positive pairs or hard negative pairs. This leads to the loss of structural information, and lacks the mechanism to generate positive pairs for nodes with few neighbors. To overcome limitations, we propose a novel soft link-based sampling method, namely MixDec Sampling, which consists of Mixup Sampling module and Decay Sampling module. The Mixup Sampling augments node features by synthesizing new nodes and soft links, which provides sufficient number of samples for nodes with few neighbors. The Decay Sampling strengthens the digestion of graph structure information by generating soft links for node embedding learning. To the best of our knowledge, we are the first to model sampling relationships between nodes by soft links in GNN-based recommender systems. Extensive experiments demonstrate that the proposed MixDec Sampling can significantly and consistently improve the recommendation performance of several representative GNN-based models on various recommendation benchmarks.
L^2CL: Embarrassingly Simple Layer-to-Layer Contrastive Learning for Graph Collaborative Filtering
Jul 19, 2024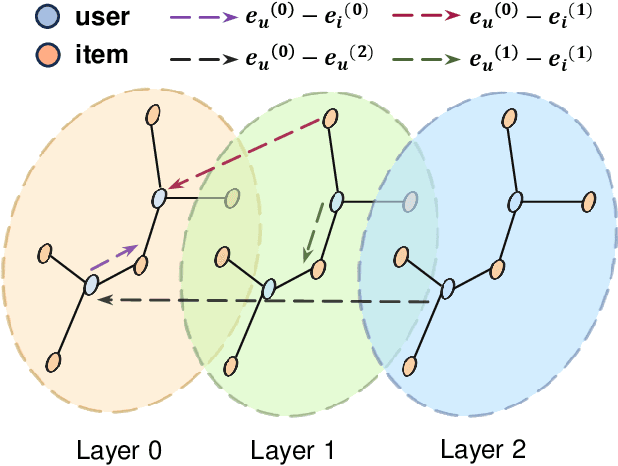
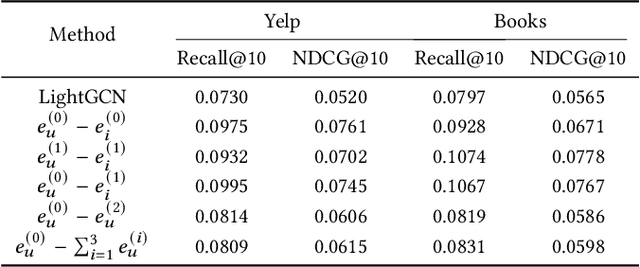
Graph neural networks (GNNs) have recently emerged as an effective approach to model neighborhood signals in collaborative filtering. Towards this research line, graph contrastive learning (GCL) demonstrates robust capabilities to address the supervision label shortage issue through generating massive self-supervised signals. Despite its effectiveness, GCL for recommendation suffers seriously from two main challenges: i) GCL relies on graph augmentation to generate semantically different views for contrasting, which could potentially disrupt key information and introduce unwanted noise; ii) current works for GCL primarily focus on contrasting representations using sophisticated networks architecture (usually deep) to capture high-order interactions, which leads to increased computational complexity and suboptimal training efficiency. To this end, we propose L2CL, a principled Layer-to-Layer Contrastive Learning framework that contrasts representations from different layers. By aligning the semantic similarities between different layers, L2CL enables the learning of complex structural relationships and gets rid of the noise perturbation in stochastic data augmentation. Surprisingly, we find that L2CL, using only one-hop contrastive learning paradigm, is able to capture intrinsic semantic structures and improve the quality of node representation, leading to a simple yet effective architecture. We also provide theoretical guarantees for L2CL in minimizing task-irrelevant information. Extensive experiments on five real-world datasets demonstrate the superiority of our model over various state-of-the-art collaborative filtering methods. Our code is available at https://github.com/downeykking/L2CL.
Olapa-MCoT: Enhancing the Chinese Mathematical Reasoning Capability of LLMs
Dec 29, 2023CoT (Chain-of-Thought) is a way to solve reasoning problems for LLMs . Recently, many researches appear for improving the CoT capability of LLMs. In this work, we also proposed Olapa-MCoT, which is a LLMs based on llama2-13B PLM for finetuning and alignment learning. During the alignment training, we proposed the SimRRHF algorithm and Incorrect Data Relearning and mainly focused on optimizing the Chinese mathematical reasoning ability of Olapa-MCoT. The experiment achieved significant results, with the accuracy of Chinese mathematical reasoning up to 50%, 36% rise compared to llama2-13B. In addition, the accuracy of English reasoning ability also increased by nearly 4%.
OlaGPT: Empowering LLMs With Human-like Problem-Solving Abilities
May 23, 2023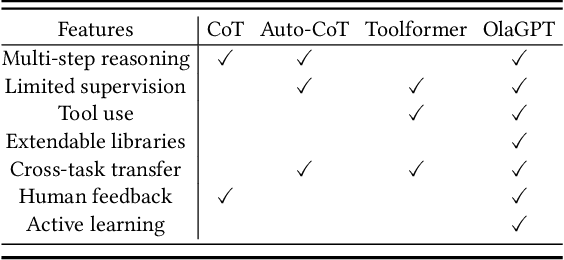
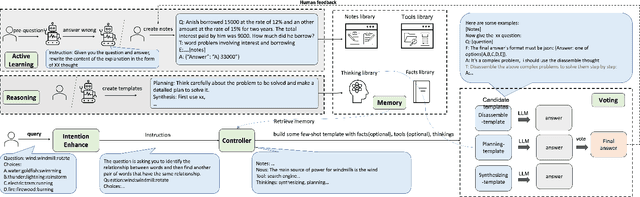
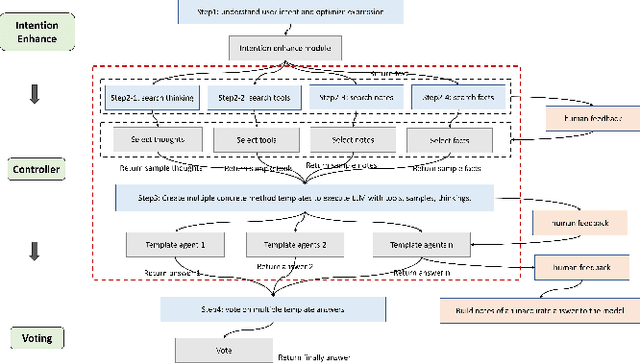

In most current research, large language models (LLMs) are able to perform reasoning tasks by generating chains of thought through the guidance of specific prompts. However, there still exists a significant discrepancy between their capability in solving complex reasoning problems and that of humans. At present, most approaches focus on chains of thought (COT) and tool use, without considering the adoption and application of human cognitive frameworks. It is well-known that when confronting complex reasoning challenges, humans typically employ various cognitive abilities, and necessitate interaction with all aspects of tools, knowledge, and the external environment information to accomplish intricate tasks. This paper introduces a novel intelligent framework, referred to as OlaGPT. OlaGPT carefully studied a cognitive architecture framework, and propose to simulate certain aspects of human cognition. The framework involves approximating different cognitive modules, including attention, memory, reasoning, learning, and corresponding scheduling and decision-making mechanisms. Inspired by the active learning mechanism of human beings, it proposes a learning unit to record previous mistakes and expert opinions, and dynamically refer to them to strengthen their ability to solve similar problems. The paper also outlines common effective reasoning frameworks for human problem-solving and designs Chain-of-Thought (COT) templates accordingly. A comprehensive decision-making mechanism is also proposed to maximize model accuracy. The efficacy of OlaGPT has been stringently evaluated on multiple reasoning datasets, and the experimental outcomes reveal that OlaGPT surpasses state-of-the-art benchmarks, demonstrating its superior performance. Our implementation of OlaGPT is available on GitHub: \url{https://github.com/oladata-team/OlaGPT}.
Domain Adaptation with Incomplete Target Domains
Dec 03, 2020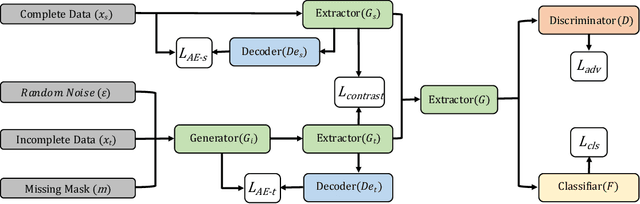
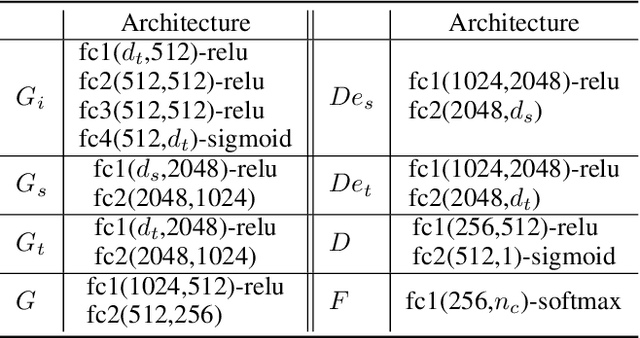
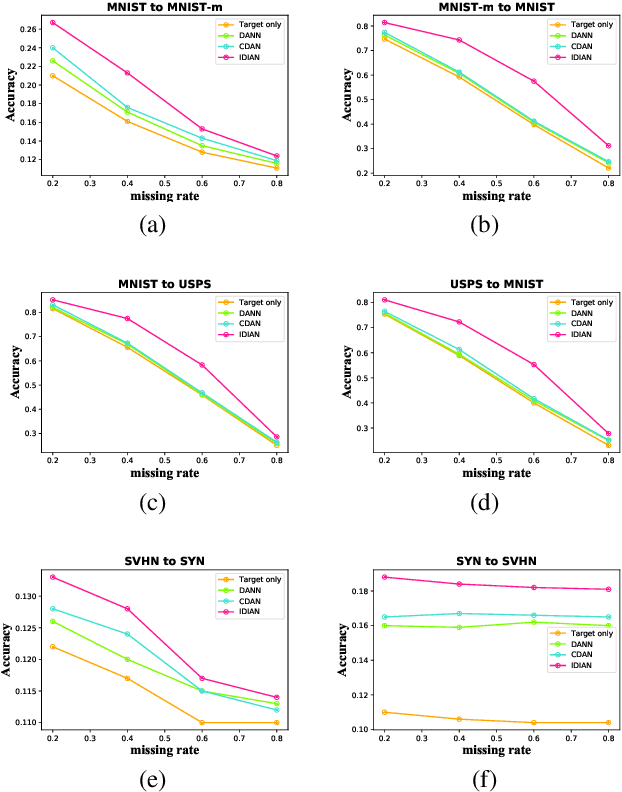

Domain adaptation, as a task of reducing the annotation cost in a target domain by exploiting the existing labeled data in an auxiliary source domain, has received a lot of attention in the research community. However, the standard domain adaptation has assumed perfectly observed data in both domains, while in real world applications the existence of missing data can be prevalent. In this paper, we tackle a more challenging domain adaptation scenario where one has an incomplete target domain with partially observed data. We propose an Incomplete Data Imputation based Adversarial Network (IDIAN) model to address this new domain adaptation challenge. In the proposed model, we design a data imputation module to fill the missing feature values based on the partial observations in the target domain, while aligning the two domains via deep adversarial adaption. We conduct experiments on both cross-domain benchmark tasks and a real world adaptation task with imperfect target domains. The experimental results demonstrate the effectiveness of the proposed method.