 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRS-Claw: Progressive Active Tool Exploration via Hierarchical Skill Trees for Remote Sensing Agents
May 13, 2026The rise of multi-modal large language models (MLLMs) is shifting remote sensing (RS) intelligence from "see" to "action", as OpenClaw-style frameworks enable agents to autonomously operate massive RS image-processing tools for complex tasks. Existing RS agents adopt a passive selection paradigm for tool invocation, relying on either full tool registration (Flat) or retrieval-augmented generation (RAG). However, in the massive and multi-source heterogeneous RS tool ecosystem, such passive mechanisms struggle to dynamically balance "context load" and "toolset completeness" throughout task reasoning, thus exhibiting inherent limitations: full tool registration triggers context space deficits during long-horizon tasks, whereas RAG retrieval may omit critical tools in essential steps. To overcome these bottlenecks, this paper redefines tool selection by arguing that the agent should act as an active explorer within the tool space. Based on this perspective, we propose RS-Claw, a novel RS agent architecture. By leveraging Skill encapsulation technology at the tool end, this architecture hierarchically structures tool descriptions, enabling the agent to execute on-demand sequential decision-making: initially selecting relevant skill branches by reading only tool summaries, then dynamically loading detailed descriptions, and ultimately achieving precise invocation. This active paradigm not only significantly liberates the agent's context space but also effectively ensures the accurate hit rate of critical tools during long-horizon reasoning. Systematic experiments on the Earth-Bench benchmark demonstrate that RS-Claw's active exploration mechanism effectively filters semantic noise and substantially frees up reasoning space, achieving an input token compression ratio of up to 86%, and comprehensively outperforming existing Flat and RAG baselines across complex reasoning evaluations.
MixDec Sampling: A Soft Link-based Sampling Method of Graph Neural Network for Recommendation
Feb 12, 2025Graph neural networks have been widely used in recent recommender systems, where negative sampling plays an important role. Existing negative sampling methods restrict the relationship between nodes as either hard positive pairs or hard negative pairs. This leads to the loss of structural information, and lacks the mechanism to generate positive pairs for nodes with few neighbors. To overcome limitations, we propose a novel soft link-based sampling method, namely MixDec Sampling, which consists of Mixup Sampling module and Decay Sampling module. The Mixup Sampling augments node features by synthesizing new nodes and soft links, which provides sufficient number of samples for nodes with few neighbors. The Decay Sampling strengthens the digestion of graph structure information by generating soft links for node embedding learning. To the best of our knowledge, we are the first to model sampling relationships between nodes by soft links in GNN-based recommender systems. Extensive experiments demonstrate that the proposed MixDec Sampling can significantly and consistently improve the recommendation performance of several representative GNN-based models on various recommendation benchmarks.
Mining Interest Trends and Adaptively Assigning SampleWeight for Session-based Recommendation
Jun 20, 2023Session-based Recommendation (SR) aims to predict users' next click based on their behavior within a short period, which is crucial for online platforms. However, most existing SR methods somewhat ignore the fact that user preference is not necessarily strongly related to the order of interactions. Moreover, they ignore the differences in importance between different samples, which limits the model-fitting performance. To tackle these issues, we put forward the method, Mining Interest Trends and Adaptively Assigning Sample Weight, abbreviated as MTAW. Specifically, we model users' instant interest based on their present behavior and all their previous behaviors. Meanwhile, we discriminatively integrate instant interests to capture the changing trend of user interest to make more personalized recommendations. Furthermore, we devise a novel loss function that dynamically weights the samples according to their prediction difficulty in the current epoch. Extensive experimental results on two benchmark datasets demonstrate the effectiveness and superiority of our method.
Knowledge Soft Integration for Multimodal Recommendation
May 12, 2023

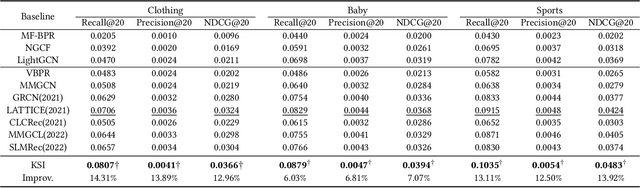

One of the main challenges in modern recommendation systems is how to effectively utilize multimodal content to achieve more personalized recommendations. Despite various proposed solutions, most of them overlook the mismatch between the knowledge gained from independent feature extraction processes and downstream recommendation tasks. Specifically, multimodal feature extraction processes do not incorporate prior knowledge relevant to recommendation tasks, while recommendation tasks often directly use these multimodal features as side information. This mismatch can lead to model fitting biases and performance degradation, which this paper refers to as the \textit{curse of knowledge} problem. To address this issue, we propose using knowledge soft integration to balance the utilization of multimodal features and the curse of knowledge problem it brings about. To achieve this, we put forward a Knowledge Soft Integration framework for the multimodal recommendation, abbreviated as KSI, which is composed of the Structure Efficiently Injection (SEI) module and the Semantic Soft Integration (SSI) module. In the SEI module, we model the modality correlation between items using Refined Graph Neural Network (RGNN), and introduce a regularization term to reduce the redundancy of user/item representations. In the SSI module, we design a self-supervised retrieval task to further indirectly integrate the semantic knowledge of multimodal features, and enhance the semantic discrimination of item representations. Extensive experiments on three benchmark datasets demonstrate the superiority of KSI and validate the effectiveness of its two modules.
Click-aware Structure Transfer with Sample Weight Assignment for Post-Click Conversion Rate Estimation
Apr 03, 2023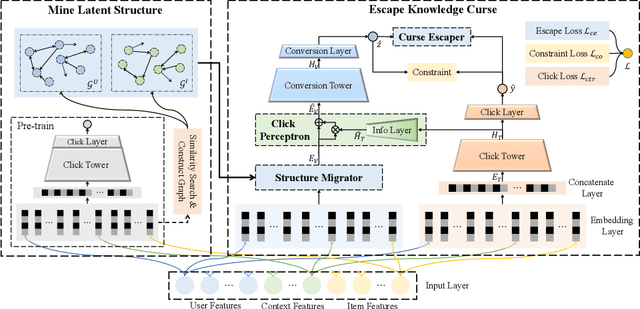

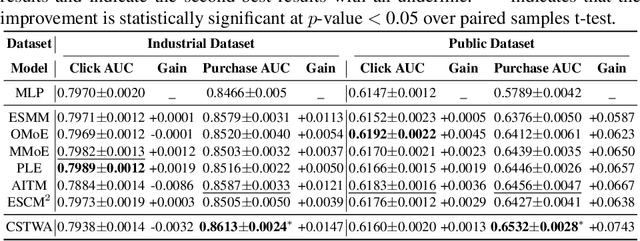
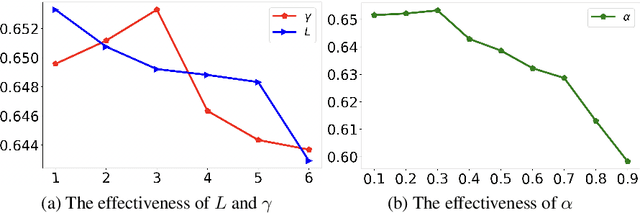
Post-click Conversion Rate (CVR) prediction task plays an essential role in industrial applications, such as recommendation and advertising. Conventional CVR methods typically suffer from the data sparsity problem as they rely only on samples where the user has clicked. To address this problem, researchers have introduced the method of multi-task learning, which utilizes non-clicked samples and shares feature representations of the Click-Through Rate (CTR) task with the CVR task. However, it should be noted that the CVR and CTR tasks are fundamentally different and may even be contradictory. Therefore, introducing a large amount of CTR information without distinction may drown out valuable information related to CVR. This phenomenon is called the curse of knowledge problem in this paper. To tackle this issue, we argue that a trade-off should be achieved between the introduction of large amounts of auxiliary information and the protection of valuable information related to CVR. Hence, we propose a Click-aware Structure Transfer model with sample Weight Assignment, abbreviated as CSTWA. It pays more attention to the latent structure information, which can filter the input information that is related to CVR, instead of directly sharing feature representations. Meanwhile, to capture the representation conflict between CTR and CVR, we calibrate the representation layer and reweight the discriminant layer to excavate the click bias information from the CTR tower. Moreover, it incorporates a sample weight assignment algorithm biased towards CVR modeling, to make the knowledge from CTR would not mislead the CVR. Extensive experiments on industrial and public datasets have demonstrated that CSTWA significantly outperforms widely used and competitive models.
Searching Transferable Mixed-Precision Quantization Policy through Large Margin Regularization
Feb 14, 2023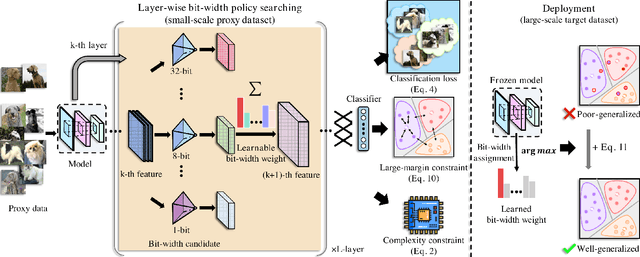
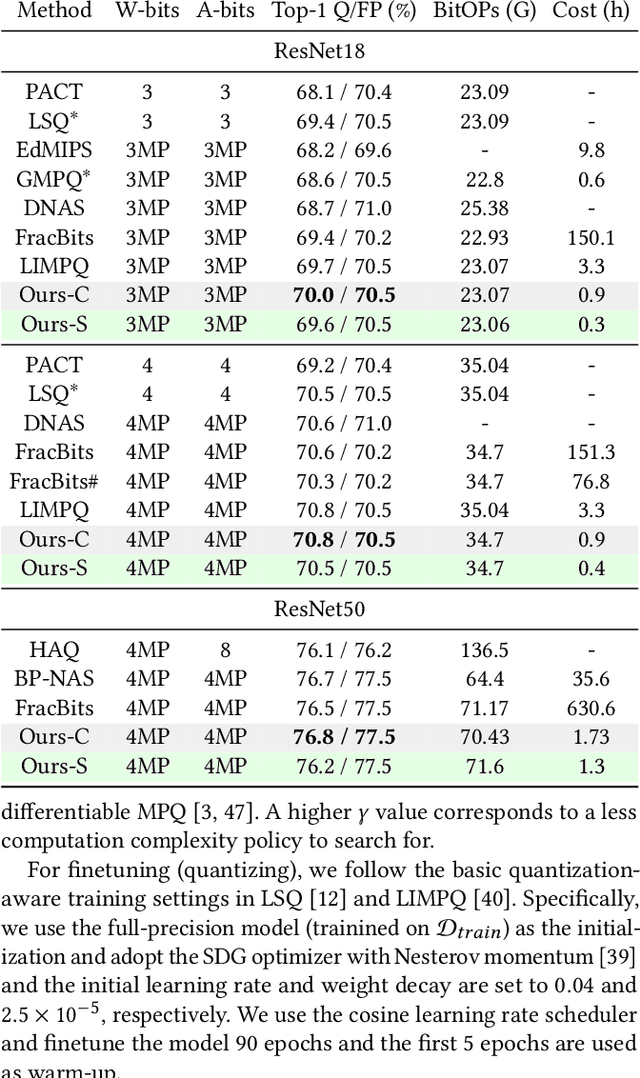

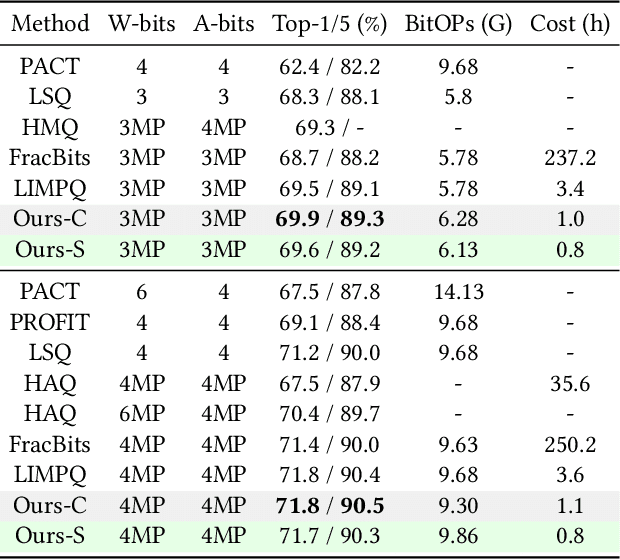
Mixed-precision quantization (MPQ) suffers from time-consuming policy search process (i.e., the bit-width assignment for each layer) on large-scale datasets (e.g., ISLVRC-2012), which heavily limits its practicability in real-world deployment scenarios. In this paper, we propose to search the effective MPQ policy by using a small proxy dataset for the model trained on a large-scale one. It breaks the routine that requires a consistent dataset at model training and MPQ policy search time, which can improve the MPQ searching efficiency significantly. However, the discrepant data distributions bring difficulties in searching for such a transferable MPQ policy. Motivated by the observation that quantization narrows the class margin and blurs the decision boundary, we search the policy that guarantees a general and dataset-independent property: discriminability of feature representations. Namely, we seek the policy that can robustly keep the intra-class compactness and inter-class separation. Our method offers several advantages, i.e., high proxy data utilization, no extra hyper-parameter tuning for approximating the relationship between full-precision and quantized model and high searching efficiency. We search high-quality MPQ policies with the proxy dataset that has only 4% of the data scale compared to the large-scale target dataset, achieving the same accuracy as searching directly on the latter, and improving the MPQ searching efficiency by up to 300 times.
Global Mixup: Eliminating Ambiguity with Clustering
Jun 06, 2022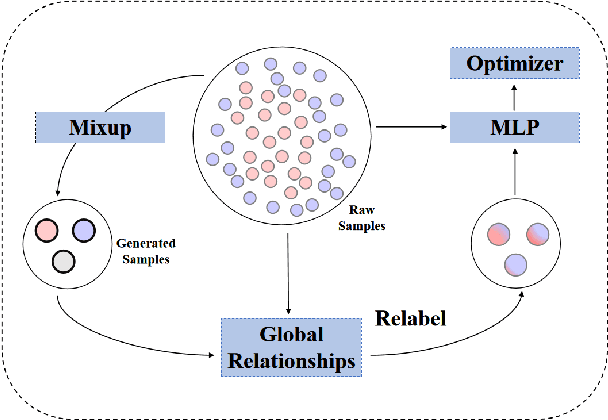
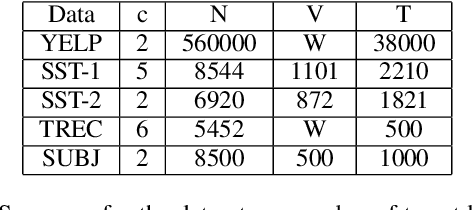
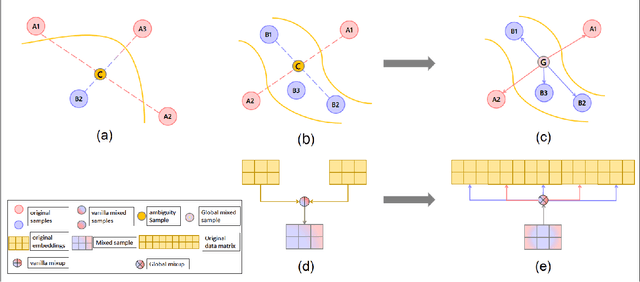
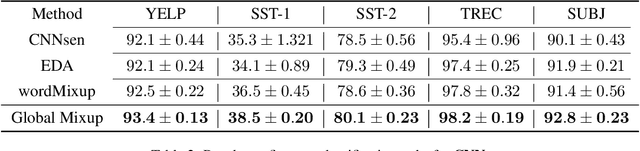
Data augmentation with \textbf{Mixup} has been proven an effective method to regularize the current deep neural networks. Mixup generates virtual samples and corresponding labels at once through linear interpolation. However, this one-stage generation paradigm and the use of linear interpolation have the following two defects: (1) The label of the generated sample is directly combined from the labels of the original sample pairs without reasonable judgment, which makes the labels likely to be ambiguous. (2) linear combination significantly limits the sampling space for generating samples. To tackle these problems, we propose a novel and effective augmentation method based on global clustering relationships named \textbf{Global Mixup}. Specifically, we transform the previous one-stage augmentation process into two-stage, decoupling the process of generating virtual samples from the labeling. And for the labels of the generated samples, relabeling is performed based on clustering by calculating the global relationships of the generated samples. In addition, we are no longer limited to linear relationships but generate more reliable virtual samples in a larger sampling space. Extensive experiments for \textbf{CNN}, \textbf{LSTM}, and \textbf{BERT} on five tasks show that Global Mixup significantly outperforms previous state-of-the-art baselines. Further experiments also demonstrate the advantage of Global Mixup in low-resource scenarios.
Arbitrary Bit-width Network: A Joint Layer-Wise Quantization and Adaptive Inference Approach
Apr 21, 2022Conventional model quantization methods use a fixed quantization scheme to different data samples, which ignores the inherent "recognition difficulty" differences between various samples. We propose to feed different data samples with varying quantization schemes to achieve a data-dependent dynamic inference, at a fine-grained layer level. However, enabling this adaptive inference with changeable layer-wise quantization schemes is challenging because the combination of bit-widths and layers is growing exponentially, making it extremely difficult to train a single model in such a vast searching space and use it in practice. To solve this problem, we present the Arbitrary Bit-width Network (ABN), where the bit-widths of a single deep network can change at runtime for different data samples, with a layer-wise granularity. Specifically, first we build a weight-shared layer-wise quantizable "super-network" in which each layer can be allocated with multiple bit-widths and thus quantized differently on demand. The super-network provides a considerably large number of combinations of bit-widths and layers, each of which can be used during inference without retraining or storing myriad models. Second, based on the well-trained super-network, each layer's runtime bit-width selection decision is modeled as a Markov Decision Process (MDP) and solved by an adaptive inference strategy accordingly. Experiments show that the super-network can be built without accuracy degradation, and the bit-widths allocation of each layer can be adjusted to deal with various inputs on the fly. On ImageNet classification, we achieve 1.1% top1 accuracy improvement while saving 36.2% BitOps.
Mixed-Precision Neural Network Quantization via Learned Layer-wise Importance
Mar 25, 2022
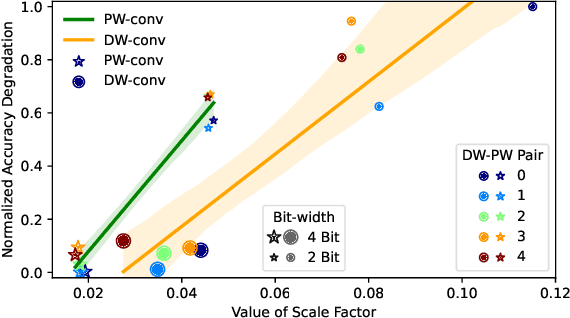

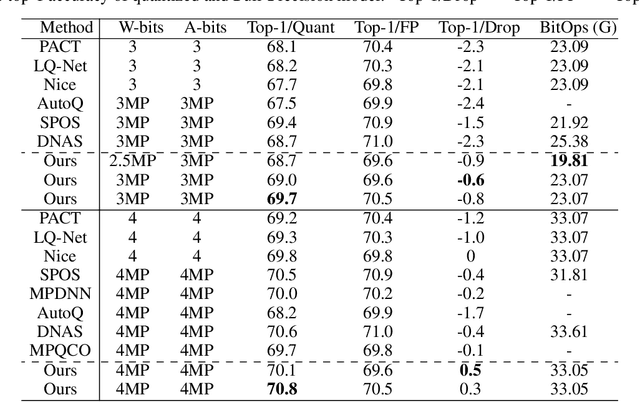
The exponentially large discrete search space in mixed-precision quantization (MPQ) makes it hard to determine the optimal bit-width for each layer. Previous works usually resort to iterative search methods on the training set, which consume hundreds or even thousands of GPU-hours. In this study, we reveal that some unique learnable parameters in quantization, namely the scale factors in the quantizer, can serve as importance indicators of a layer, reflecting the contribution of that layer to the final accuracy at certain bit-widths. These importance indicators naturally perceive the numerical transformation during quantization-aware training, which can precisely and correctly provide quantization sensitivity metrics of layers. However, a deep network always contains hundreds of such indicators, and training them one by one would lead to an excessive time cost. To overcome this issue, we propose a joint training scheme that can obtain all indicators at once. It considerably speeds up the indicators training process by parallelizing the original sequential training processes. With these learned importance indicators, we formulate the MPQ search problem as a one-time integer linear programming (ILP) problem. That avoids the iterative search and significantly reduces search time without limiting the bit-width search space. For example, MPQ search on ResNet18 with our indicators takes only 0.06 seconds. Also, extensive experiments show our approach can achieve SOTA accuracy on ImageNet for far-ranging models with various constraints (e.g., BitOps, compress rate).