 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIVE: Long-horizon Interactive Video World Modeling
Feb 03, 2026Autoregressive video world models predict future visual observations conditioned on actions. While effective over short horizons, these models often struggle with long-horizon generation, as small prediction errors accumulate over time. Prior methods alleviate this by introducing pre-trained teacher models and sequence-level distribution matching, which incur additional computational cost and fail to prevent error propagation beyond the training horizon. In this work, we propose LIVE, a Long-horizon Interactive Video world modEl that enforces bounded error accumulation via a novel cycle-consistency objective, thereby eliminating the need for teacher-based distillation. Specifically, LIVE first performs a forward rollout from ground-truth frames and then applies a reverse generation process to reconstruct the initial state. The diffusion loss is subsequently computed on the reconstructed terminal state, providing an explicit constraint on long-horizon error propagation. Moreover, we provide an unified view that encompasses different approaches and introduce progressive training curriculum to stabilize training. Experiments demonstrate that LIVE achieves state-of-the-art performance on long-horizon benchmarks, generating stable, high-quality videos far beyond training rollout lengths.
HyperOffload: Graph-Driven Hierarchical Memory Management for Large Language Models on SuperNode Architectures
Feb 03, 2026The rapid evolution of Large Language Models (LLMs) towards long-context reasoning and sparse architectures has pushed memory requirements far beyond the capacity of individual device HBM. While emerging supernode architectures offer terabyte-scale shared memory pools via high-bandwidth interconnects, existing software stacks fail to exploit this hardware effectively. Current runtime-based offloading and swapping techniques operate with a local view, leading to reactive scheduling and exposed communication latency that stall the computation pipeline. In this paper, we propose the SuperNode Memory Management Framework (\textbf{HyperOffload}). It employs a compiler-assisted approach that leverages graph-driven memory management to treat remote memory access as explicit operations in the computation graph, specifically designed for hierarchical SuperNode architectures. Unlike reactive runtime systems, SuperNode represents data movement using cache operators within the compiler's Intermediate Representation (IR). This design enables a global, compile-time analysis of tensor lifetimes and execution dependencies. Leveraging this visibility, we develop a global execution-order refinement algorithm that statically schedules data transfers to hide remote memory latency behind compute-intensive regions. We implement SuperNode within the production deep learning framework MindSpore, adding a remote memory backend and specialized compiler passes. Evaluation on representative LLM workloads shows that SuperNode reduces peak device memory usage by up to 26\% for inference while maintaining end-to-end performance. Our work demonstrates that integrating memory-augmented hardware into the compiler's optimization framework is essential for scaling next-generation AI workloads.
GeoPredict: Leveraging Predictive Kinematics and 3D Gaussian Geometry for Precise VLA Manipulation
Dec 18, 2025Vision-Language-Action (VLA) models achieve strong generalization in robotic manipulation but remain largely reactive and 2D-centric, making them unreliable in tasks that require precise 3D reasoning. We propose GeoPredict, a geometry-aware VLA framework that augments a continuous-action policy with predictive kinematic and geometric priors. GeoPredict introduces a trajectory-level module that encodes motion history and predicts multi-step 3D keypoint trajectories of robot arms, and a predictive 3D Gaussian geometry module that forecasts workspace geometry with track-guided refinement along future keypoint trajectories. These predictive modules serve exclusively as training-time supervision through depth-based rendering, while inference requires only lightweight additional query tokens without invoking any 3D decoding. Experiments on RoboCasa Human-50, LIBERO, and real-world manipulation tasks show that GeoPredict consistently outperforms strong VLA baselines, especially in geometry-intensive and spatially demanding scenarios.
SpecQuant: Spectral Decomposition and Adaptive Truncation for Ultra-Low-Bit LLMs Quantization
Nov 11, 2025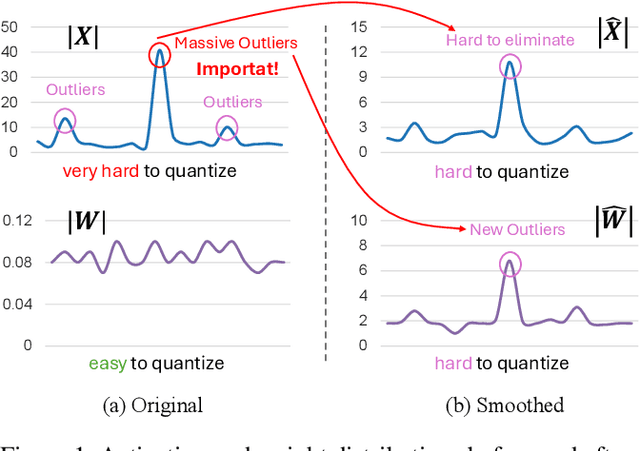
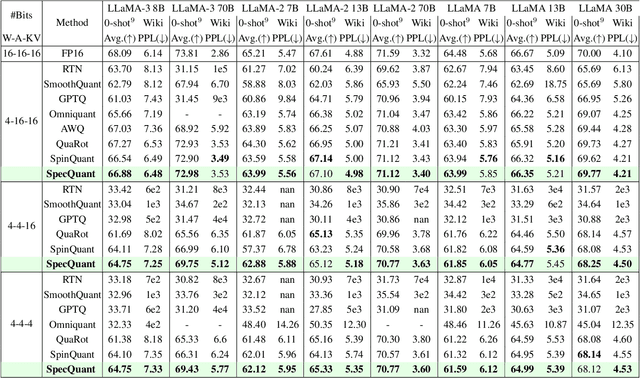
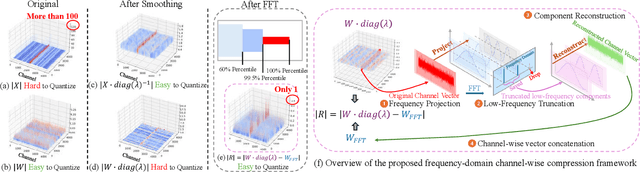
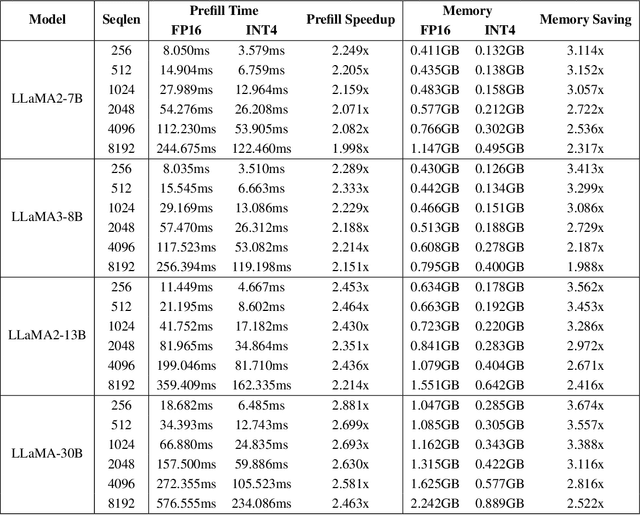
The emergence of accurate open large language models (LLMs) has sparked a push for advanced quantization techniques to enable efficient deployment on end-user devices. In this paper, we revisit the challenge of extreme LLM compression -- targeting ultra-low-bit quantization for both activations and weights -- from a Fourier frequency domain perspective. We propose SpecQuant, a two-stage framework that tackles activation outliers and cross-channel variance. In the first stage, activation outliers are smoothed and transferred into the weight matrix to simplify downstream quantization. In the second stage, we apply channel-wise low-frequency Fourier truncation to suppress high-frequency components while preserving essential signal energy, improving quantization robustness. Our method builds on the principle that most of the weight energy is concentrated in low-frequency components, which can be retained with minimal impact on model accuracy. To enable runtime adaptability, we introduce a lightweight truncation module during inference that adjusts truncation thresholds based on channel characteristics. On LLaMA-3 8B, SpecQuant achieves 4-bit quantization for both weights and activations, narrowing the zero-shot accuracy gap to only 1.5% compared to full precision, while delivering 2 times faster inference and 3times lower memory usage.
QUARK: Quantization-Enabled Circuit Sharing for Transformer Acceleration by Exploiting Common Patterns in Nonlinear Operations
Nov 10, 2025Transformer-based models have revolutionized computer vision (CV) and natural language processing (NLP) by achieving state-of-the-art performance across a range of benchmarks. However, nonlinear operations in models significantly contribute to inference latency, presenting unique challenges for efficient hardware acceleration. To this end, we propose QUARK, a quantization-enabled FPGA acceleration framework that leverages common patterns in nonlinear operations to enable efficient circuit sharing, thereby reducing hardware resource requirements. QUARK targets all nonlinear operations within Transformer-based models, achieving high-performance approximation through a novel circuit-sharing design tailored to accelerate these operations. Our evaluation demonstrates that QUARK significantly reduces the computational overhead of nonlinear operators in mainstream Transformer architectures, achieving up to a 1.96 times end-to-end speedup over GPU implementations. Moreover, QUARK lowers the hardware overhead of nonlinear modules by more than 50% compared to prior approaches, all while maintaining high model accuracy -- and even substantially boosting accuracy under ultra-low-bit quantization.
UniSplat: Unified Spatio-Temporal Fusion via 3D Latent Scaffolds for Dynamic Driving Scene Reconstruction
Nov 06, 2025Feed-forward 3D reconstruction for autonomous driving has advanced rapidly, yet existing methods struggle with the joint challenges of sparse, non-overlapping camera views and complex scene dynamics. We present UniSplat, a general feed-forward framework that learns robust dynamic scene reconstruction through unified latent spatio-temporal fusion. UniSplat constructs a 3D latent scaffold, a structured representation that captures geometric and semantic scene context by leveraging pretrained foundation models. To effectively integrate information across spatial views and temporal frames, we introduce an efficient fusion mechanism that operates directly within the 3D scaffold, enabling consistent spatio-temporal alignment. To ensure complete and detailed reconstructions, we design a dual-branch decoder that generates dynamic-aware Gaussians from the fused scaffold by combining point-anchored refinement with voxel-based generation, and maintain a persistent memory of static Gaussians to enable streaming scene completion beyond current camera coverage. Extensive experiments on real-world datasets demonstrate that UniSplat achieves state-of-the-art performance in novel view synthesis, while providing robust and high-quality renderings even for viewpoints outside the original camera coverage.
Mitigating Object Hallucinations via Sentence-Level Early Intervention
Jul 16, 2025Multimodal large language models (MLLMs) have revolutionized cross-modal understanding but continue to struggle with hallucinations - fabricated content contradicting visual inputs. Existing hallucination mitigation methods either incur prohibitive computational costs or introduce distribution mismatches between training data and model outputs. We identify a critical insight: hallucinations predominantly emerge at the early stages of text generation and propagate through subsequent outputs. To address this, we propose **SENTINEL** (**S**entence-level **E**arly i**N**tervention **T**hrough **IN**-domain pr**E**ference **L**earning), a framework that eliminates dependency on human annotations. Specifically, we first bootstrap high-quality in-domain preference pairs by iteratively sampling model outputs, validating object existence through cross-checking with two open-vocabulary detectors, and classifying sentences into hallucinated/non-hallucinated categories. Subsequently, we use context-coherent positive samples and hallucinated negative samples to build context-aware preference data iteratively. Finally, we train models using a context-aware preference loss (C-DPO) that emphasizes discriminative learning at the sentence level where hallucinations initially manifest. Experimental results show that SENTINEL can reduce hallucinations by over 90\% compared to the original model and outperforms the previous state-of-the-art method on both hallucination benchmarks and general capabilities benchmarks, demonstrating its superiority and generalization ability. The models, datasets, and code are available at https://github.com/pspdada/SENTINEL.
Edit360: 2D Image Edits to 3D Assets from Any Angle
Jun 12, 2025Recent advances in diffusion models have significantly improved image generation and editing, but extending these capabilities to 3D assets remains challenging, especially for fine-grained edits that require multi-view consistency. Existing methods typically restrict editing to predetermined viewing angles, severely limiting their flexibility and practical applications. We introduce Edit360, a tuning-free framework that extends 2D modifications to multi-view consistent 3D editing. Built upon video diffusion models, Edit360 enables user-specific editing from arbitrary viewpoints while ensuring structural coherence across all views. The framework selects anchor views for 2D modifications and propagates edits across the entire 360-degree range. To achieve this, Edit360 introduces a novel Anchor-View Editing Propagation mechanism, which effectively aligns and merges multi-view information within the latent and attention spaces of diffusion models. The resulting edited multi-view sequences facilitate the reconstruction of high-quality 3D assets, enabling customizable 3D content creation.
DriveX: Omni Scene Modeling for Learning Generalizable World Knowledge in Autonomous Driving
May 25, 2025Data-driven learning has advanced autonomous driving, yet task-specific models struggle with out-of-distribution scenarios due to their narrow optimization objectives and reliance on costly annotated data. We present DriveX, a self-supervised world model that learns generalizable scene dynamics and holistic representations (geometric, semantic, and motion) from large-scale driving videos. DriveX introduces Omni Scene Modeling (OSM), a module that unifies multimodal supervision-3D point cloud forecasting, 2D semantic representation, and image generation-to capture comprehensive scene evolution. To simplify learning complex dynamics, we propose a decoupled latent world modeling strategy that separates world representation learning from future state decoding, augmented by dynamic-aware ray sampling to enhance motion modeling. For downstream adaptation, we design Future Spatial Attention (FSA), a unified paradigm that dynamically aggregates spatiotemporal features from DriveX's predictions to enhance task-specific inference. Extensive experiments demonstrate DriveX's effectiveness: it achieves significant improvements in 3D future point cloud prediction over prior work, while attaining state-of-the-art results on diverse tasks including occupancy prediction, flow estimation, and end-to-end driving. These results validate DriveX's capability as a general-purpose world model, paving the way for robust and unified autonomous driving frameworks.
DASH: Input-Aware Dynamic Layer Skipping for Efficient LLM Inference with Markov Decision Policies
May 23, 2025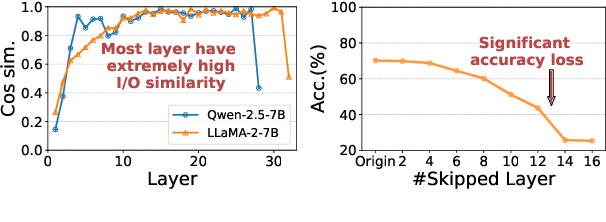
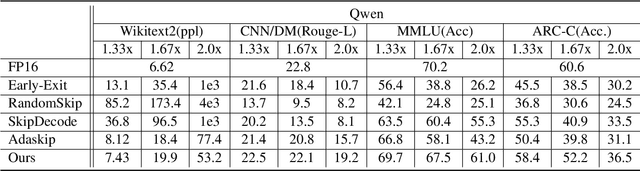
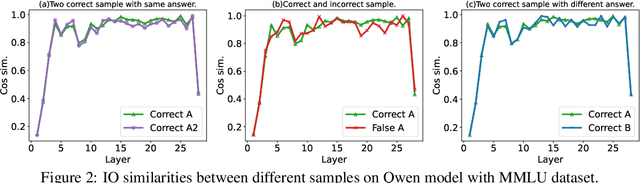
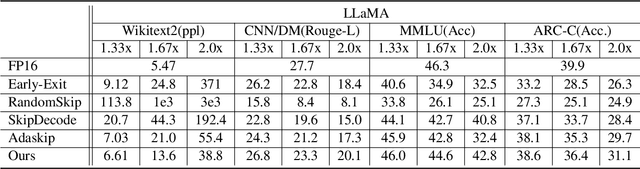
Large language models (LLMs) have achieved remarkable performance across a wide range of NLP tasks. However, their substantial inference cost poses a major barrier to real-world deployment, especially in latency-sensitive scenarios. To address this challenge, we propose \textbf{DASH}, an adaptive layer-skipping framework that dynamically selects computation paths conditioned on input characteristics. We model the skipping process as a Markov Decision Process (MDP), enabling fine-grained token-level decisions based on intermediate representations. To mitigate potential performance degradation caused by skipping, we introduce a lightweight compensation mechanism that injects differential rewards into the decision process. Furthermore, we design an asynchronous execution strategy that overlaps layer computation with policy evaluation to minimize runtime overhead. Experiments on multiple LLM architectures and NLP benchmarks show that our method achieves significant inference acceleration while maintaining competitive task performance, outperforming existing methods.