 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Images, More Problems? A Controlled Analysis of VLM Failure Modes
Jan 12, 2026Large Vision Language Models (LVLMs) have demonstrated remarkable capabilities, yet their proficiency in understanding and reasoning over multiple images remains largely unexplored. While existing benchmarks have initiated the evaluation of multi-image models, a comprehensive analysis of their core weaknesses and their causes is still lacking. In this work, we introduce MIMIC (Multi-Image Model Insights and Challenges), a new benchmark designed to rigorously evaluate the multi-image capabilities of LVLMs. Using MIMIC, we conduct a series of diagnostic experiments that reveal pervasive issues: LVLMs often fail to aggregate information across images and struggle to track or attend to multiple concepts simultaneously. To address these failures, we propose two novel complementary remedies. On the data side, we present a procedural data-generation strategy that composes single-image annotations into rich, targeted multi-image training examples. On the optimization side, we analyze layer-wise attention patterns and derive an attention-masking scheme tailored for multi-image inputs. Experiments substantially improved cross-image aggregation, while also enhancing performance on existing multi-image benchmarks, outperforming prior state of the art across tasks. Data and code will be made available at https://github.com/anurag-198/MIMIC.
MTA-CLIP: Language-Guided Semantic Segmentation with Mask-Text Alignment
Jul 31, 2024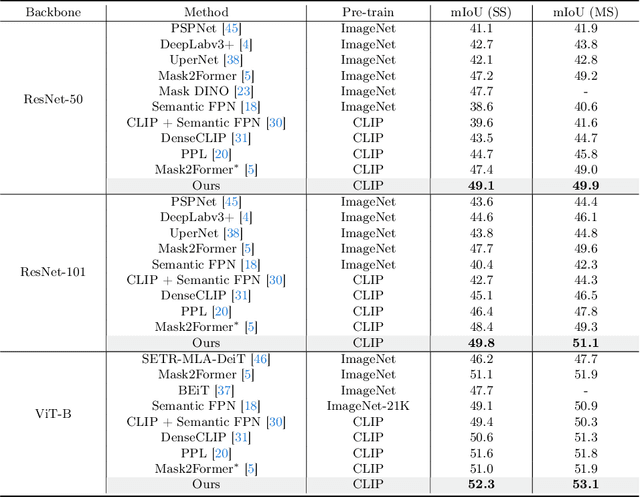
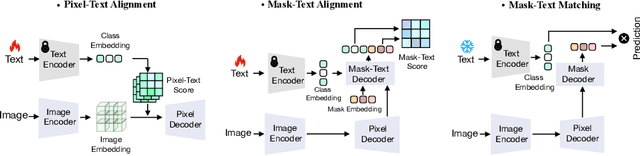
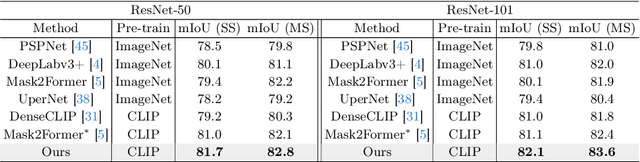
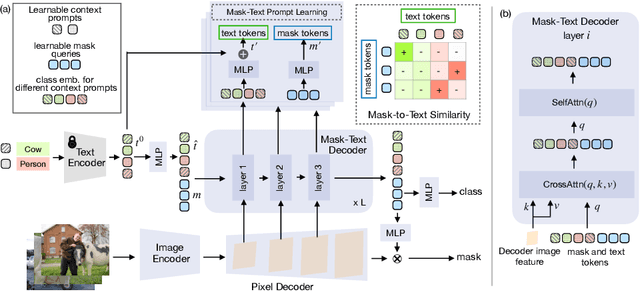
Recent approaches have shown that large-scale vision-language models such as CLIP can improve semantic segmentation performance. These methods typically aim for pixel-level vision-language alignment, but often rely on low resolution image features from CLIP, resulting in class ambiguities along boundaries. Moreover, the global scene representations in CLIP text embeddings do not directly correlate with the local and detailed pixel-level features, making meaningful alignment more difficult. To address these limitations, we introduce MTA-CLIP, a novel framework employing mask-level vision-language alignment. Specifically, we first propose Mask-Text Decoder that enhances the mask representations using rich textual data with the CLIP language model. Subsequently, it aligns mask representations with text embeddings using Mask-to-Text Contrastive Learning. Furthermore, we introduce MaskText Prompt Learning, utilizing multiple context-specific prompts for text embeddings to capture diverse class representations across masks. Overall, MTA-CLIP achieves state-of-the-art, surpassing prior works by an average of 2.8% and 1.3% on on standard benchmark datasets, ADE20k and Cityscapes, respectively.
Improving 2D Feature Representations by 3D-Aware Fine-Tuning
Jul 29, 2024



Current visual foundation models are trained purely on unstructured 2D data, limiting their understanding of 3D structure of objects and scenes. In this work, we show that fine-tuning on 3D-aware data improves the quality of emerging semantic features. We design a method to lift semantic 2D features into an efficient 3D Gaussian representation, which allows us to re-render them for arbitrary views. Using the rendered 3D-aware features, we design a fine-tuning strategy to transfer such 3D awareness into a 2D foundation model. We demonstrate that models fine-tuned in that way produce features that readily improve downstream task performance in semantic segmentation and depth estimation through simple linear probing. Notably, though fined-tuned on a single indoor dataset, the improvement is transferable to a variety of indoor datasets and out-of-domain datasets. We hope our study encourages the community to consider injecting 3D awareness when training 2D foundation models. Project page: https://ywyue.github.io/FiT3D.
Urban Scene Semantic Segmentation with Low-Cost Coarse Annotation
Dec 15, 2022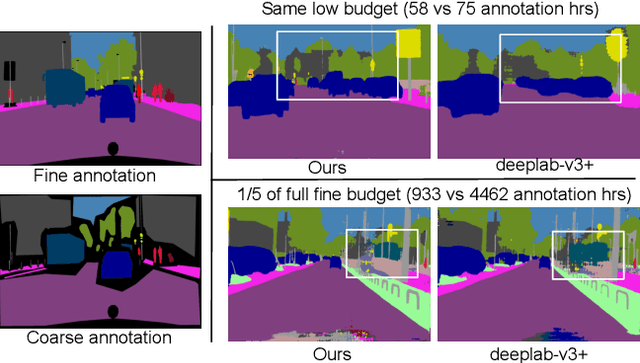



For best performance, today's semantic segmentation methods use large and carefully labeled datasets, requiring expensive annotation budgets. In this work, we show that coarse annotation is a low-cost but highly effective alternative for training semantic segmentation models. Considering the urban scene segmentation scenario, we leverage cheap coarse annotations for real-world captured data, as well as synthetic data to train our model and show competitive performance compared with finely annotated real-world data. Specifically, we propose a coarse-to-fine self-training framework that generates pseudo labels for unlabeled regions of the coarsely annotated data, using synthetic data to improve predictions around the boundaries between semantic classes, and using cross-domain data augmentation to increase diversity. Our extensive experimental results on Cityscapes and BDD100k datasets demonstrate that our method achieves a significantly better performance vs annotation cost tradeoff, yielding a comparable performance to fully annotated data with only a small fraction of the annotation budget. Also, when used as pretraining, our framework performs better compared to the standard fully supervised setting.