 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Perception Models for 3D Scene Synthesis
Jun 25, 2025



Traditionally, 3D scene synthesis requires expert knowledge and significant manual effort. Automating this process could greatly benefit fields such as architectural design, robotics simulation, virtual reality, and gaming. Recent approaches to 3D scene synthesis often rely on the commonsense reasoning of large language models (LLMs) or strong visual priors of modern image generation models. However, current LLMs demonstrate limited 3D spatial reasoning ability, which restricts their ability to generate realistic and coherent 3D scenes. Meanwhile, image generation-based methods often suffer from constraints in viewpoint selection and multi-view inconsistencies. In this work, we present Video Perception models for 3D Scene synthesis (VIPScene), a novel framework that exploits the encoded commonsense knowledge of the 3D physical world in video generation models to ensure coherent scene layouts and consistent object placements across views. VIPScene accepts both text and image prompts and seamlessly integrates video generation, feedforward 3D reconstruction, and open-vocabulary perception models to semantically and geometrically analyze each object in a scene. This enables flexible scene synthesis with high realism and structural consistency. For more precise analysis, we further introduce First-Person View Score (FPVScore) for coherence and plausibility evaluation, utilizing continuous first-person perspective to capitalize on the reasoning ability of multimodal large language models. Extensive experiments show that VIPScene significantly outperforms existing methods and generalizes well across diverse scenarios. The code will be released.
SLAG: Scalable Language-Augmented Gaussian Splatting
May 12, 2025Language-augmented scene representations hold great promise for large-scale robotics applications such as search-and-rescue, smart cities, and mining. Many of these scenarios are time-sensitive, requiring rapid scene encoding while also being data-intensive, necessitating scalable solutions. Deploying these representations on robots with limited computational resources further adds to the challenge. To address this, we introduce SLAG, a multi-GPU framework for language-augmented Gaussian splatting that enhances the speed and scalability of embedding large scenes. Our method integrates 2D visual-language model features into 3D scenes using SAM and CLIP. Unlike prior approaches, SLAG eliminates the need for a loss function to compute per-Gaussian language embeddings. Instead, it derives embeddings from 3D Gaussian scene parameters via a normalized weighted average, enabling highly parallelized scene encoding. Additionally, we introduce a vector database for efficient embedding storage and retrieval. Our experiments show that SLAG achieves an 18 times speedup in embedding computation on a 16-GPU setup compared to OpenGaussian, while preserving embedding quality on the ScanNet and LERF datasets. For more details, visit our project website: https://slag-project.github.io/.
Robust Human Registration with Body Part Segmentation on Noisy Point Clouds
Apr 04, 2025



Registering human meshes to 3D point clouds is essential for applications such as augmented reality and human-robot interaction but often yields imprecise results due to noise and background clutter in real-world data. We introduce a hybrid approach that incorporates body-part segmentation into the mesh fitting process, enhancing both human pose estimation and segmentation accuracy. Our method first assigns body part labels to individual points, which then guide a two-step SMPL-X fitting: initial pose and orientation estimation using body part centroids, followed by global refinement of the point cloud alignment. Additionally, we demonstrate that the fitted human mesh can refine body part labels, leading to improved segmentation. Evaluations on the cluttered and noisy real-world datasets InterCap, EgoBody, and BEHAVE show that our approach significantly outperforms prior methods in both pose estimation and segmentation accuracy. Code and results are available on our project website: https://segfit.github.io
SuperDec: 3D Scene Decomposition with Superquadric Primitives
Apr 01, 2025

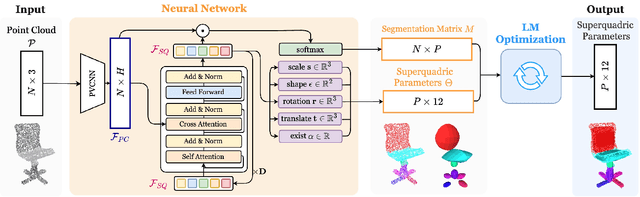

We present SuperDec, an approach for creating compact 3D scene representations via decomposition into superquadric primitives. While most recent works leverage geometric primitives to obtain photorealistic 3D scene representations, we propose to leverage them to obtain a compact yet expressive representation. We propose to solve the problem locally on individual objects and leverage the capabilities of instance segmentation methods to scale our solution to full 3D scenes. In doing that, we design a new architecture which efficiently decompose point clouds of arbitrary objects in a compact set of superquadrics. We train our architecture on ShapeNet and we prove its generalization capabilities on object instances extracted from the ScanNet++ dataset as well as on full Replica scenes. Finally, we show how a compact representation based on superquadrics can be useful for a diverse range of downstream applications, including robotic tasks and controllable visual content generation and editing.
Open-Vocabulary Functional 3D Scene Graphs for Real-World Indoor Spaces
Mar 24, 2025



We introduce the task of predicting functional 3D scene graphs for real-world indoor environments from posed RGB-D images. Unlike traditional 3D scene graphs that focus on spatial relationships of objects, functional 3D scene graphs capture objects, interactive elements, and their functional relationships. Due to the lack of training data, we leverage foundation models, including visual language models (VLMs) and large language models (LLMs), to encode functional knowledge. We evaluate our approach on an extended SceneFun3D dataset and a newly collected dataset, FunGraph3D, both annotated with functional 3D scene graphs. Our method significantly outperforms adapted baselines, including Open3DSG and ConceptGraph, demonstrating its effectiveness in modeling complex scene functionalities. We also demonstrate downstream applications such as 3D question answering and robotic manipulation using functional 3D scene graphs. See our project page at https://openfungraph.github.io
OpenCity3D: What do Vision-Language Models know about Urban Environments?
Mar 21, 2025



Vision-language models (VLMs) show great promise for 3D scene understanding but are mainly applied to indoor spaces or autonomous driving, focusing on low-level tasks like segmentation. This work expands their use to urban-scale environments by leveraging 3D reconstructions from multi-view aerial imagery. We propose OpenCity3D, an approach that addresses high-level tasks, such as population density estimation, building age classification, property price prediction, crime rate assessment, and noise pollution evaluation. Our findings highlight OpenCity3D's impressive zero-shot and few-shot capabilities, showcasing adaptability to new contexts. This research establishes a new paradigm for language-driven urban analytics, enabling applications in planning, policy, and environmental monitoring. See our project page: opencity3d.github.io
ARKit LabelMaker: A New Scale for Indoor 3D Scene Understanding
Oct 17, 2024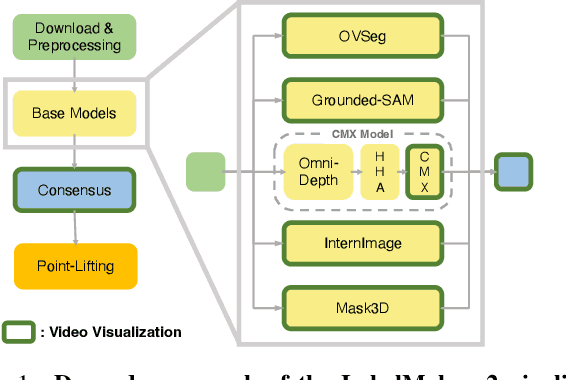
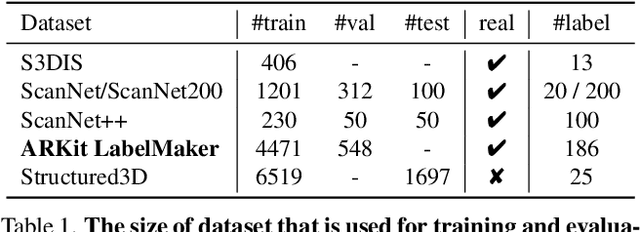


The performance of neural networks scales with both their size and the amount of data they have been trained on. This is shown in both language and image generation. However, this requires scaling-friendly network architectures as well as large-scale datasets. Even though scaling-friendly architectures like transformers have emerged for 3D vision tasks, the GPT-moment of 3D vision remains distant due to the lack of training data. In this paper, we introduce ARKit LabelMaker, the first large-scale, real-world 3D dataset with dense semantic annotations. Specifically, we complement ARKitScenes dataset with dense semantic annotations that are automatically generated at scale. To this end, we extend LabelMaker, a recent automatic annotation pipeline, to serve the needs of large-scale pre-training. This involves extending the pipeline with cutting-edge segmentation models as well as making it robust to the challenges of large-scale processing. Further, we push forward the state-of-the-art performance on ScanNet and ScanNet200 dataset with prevalent 3D semantic segmentation models, demonstrating the efficacy of our generated dataset.
Search3D: Hierarchical Open-Vocabulary 3D Segmentation
Sep 27, 2024
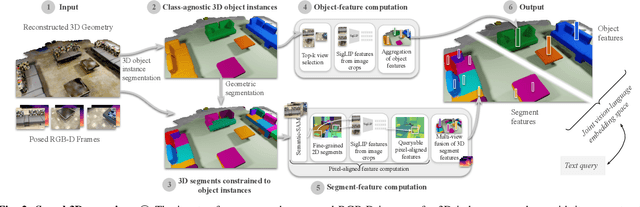
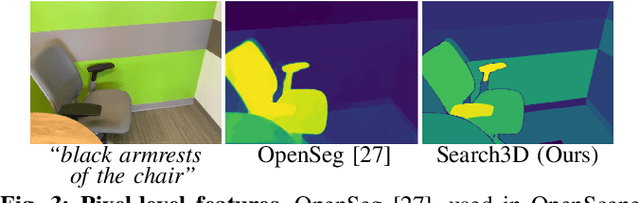

Open-vocabulary 3D segmentation enables the exploration of 3D spaces using free-form text descriptions. Existing methods for open-vocabulary 3D instance segmentation primarily focus on identifying object-level instances in a scene. However, they face challenges when it comes to understanding more fine-grained scene entities such as object parts, or regions described by generic attributes. In this work, we introduce Search3D, an approach that builds a hierarchical open-vocabulary 3D scene representation, enabling the search for entities at varying levels of granularity: fine-grained object parts, entire objects, or regions described by attributes like materials. Our method aims to expand the capabilities of open vocabulary instance-level 3D segmentation by shifting towards a more flexible open-vocabulary 3D search setting less anchored to explicit object-centric queries, compared to prior work. To ensure a systematic evaluation, we also contribute a scene-scale open-vocabulary 3D part segmentation benchmark based on MultiScan, along with a set of open-vocabulary fine-grained part annotations on ScanNet++. We verify the effectiveness of Search3D across several tasks, demonstrating that our approach outperforms baselines in scene-scale open-vocabulary 3D part segmentation, while maintaining strong performance in segmenting 3D objects and materials.
P2P-Bridge: Diffusion Bridges for 3D Point Cloud Denoising
Aug 29, 2024



In this work, we tackle the task of point cloud denoising through a novel framework that adapts Diffusion Schr\"odinger bridges to points clouds. Unlike previous approaches that predict point-wise displacements from point features or learned noise distributions, our method learns an optimal transport plan between paired point clouds. Experiments on object datasets like PU-Net and real-world datasets such as ScanNet++ and ARKitScenes show that P2P-Bridge achieves significant improvements over existing methods. While our approach demonstrates strong results using only point coordinates, we also show that incorporating additional features, such as color information or point-wise DINOv2 features, further enhances the performance. Code and pretrained models are available at https://p2p-bridge.github.io.
Improving 2D Feature Representations by 3D-Aware Fine-Tuning
Jul 29, 2024



Current visual foundation models are trained purely on unstructured 2D data, limiting their understanding of 3D structure of objects and scenes. In this work, we show that fine-tuning on 3D-aware data improves the quality of emerging semantic features. We design a method to lift semantic 2D features into an efficient 3D Gaussian representation, which allows us to re-render them for arbitrary views. Using the rendered 3D-aware features, we design a fine-tuning strategy to transfer such 3D awareness into a 2D foundation model. We demonstrate that models fine-tuned in that way produce features that readily improve downstream task performance in semantic segmentation and depth estimation through simple linear probing. Notably, though fined-tuned on a single indoor dataset, the improvement is transferable to a variety of indoor datasets and out-of-domain datasets. We hope our study encourages the community to consider injecting 3D awareness when training 2D foundation models. Project page: https://ywyue.github.io/FiT3D.