 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Vocabulary Functional 3D Scene Graphs for Real-World Indoor Spaces
Mar 24, 2025



We introduce the task of predicting functional 3D scene graphs for real-world indoor environments from posed RGB-D images. Unlike traditional 3D scene graphs that focus on spatial relationships of objects, functional 3D scene graphs capture objects, interactive elements, and their functional relationships. Due to the lack of training data, we leverage foundation models, including visual language models (VLMs) and large language models (LLMs), to encode functional knowledge. We evaluate our approach on an extended SceneFun3D dataset and a newly collected dataset, FunGraph3D, both annotated with functional 3D scene graphs. Our method significantly outperforms adapted baselines, including Open3DSG and ConceptGraph, demonstrating its effectiveness in modeling complex scene functionalities. We also demonstrate downstream applications such as 3D question answering and robotic manipulation using functional 3D scene graphs. See our project page at https://openfungraph.github.io
Search3D: Hierarchical Open-Vocabulary 3D Segmentation
Sep 27, 2024
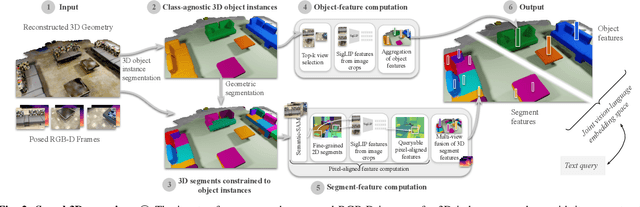
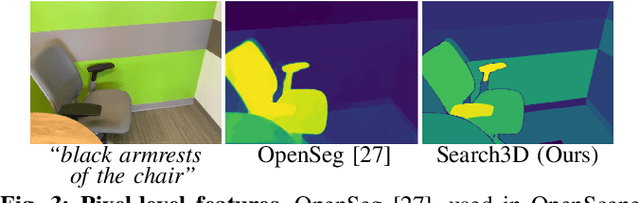

Open-vocabulary 3D segmentation enables the exploration of 3D spaces using free-form text descriptions. Existing methods for open-vocabulary 3D instance segmentation primarily focus on identifying object-level instances in a scene. However, they face challenges when it comes to understanding more fine-grained scene entities such as object parts, or regions described by generic attributes. In this work, we introduce Search3D, an approach that builds a hierarchical open-vocabulary 3D scene representation, enabling the search for entities at varying levels of granularity: fine-grained object parts, entire objects, or regions described by attributes like materials. Our method aims to expand the capabilities of open vocabulary instance-level 3D segmentation by shifting towards a more flexible open-vocabulary 3D search setting less anchored to explicit object-centric queries, compared to prior work. To ensure a systematic evaluation, we also contribute a scene-scale open-vocabulary 3D part segmentation benchmark based on MultiScan, along with a set of open-vocabulary fine-grained part annotations on ScanNet++. We verify the effectiveness of Search3D across several tasks, demonstrating that our approach outperforms baselines in scene-scale open-vocabulary 3D part segmentation, while maintaining strong performance in segmenting 3D objects and materials.
Multi-CLIP: Contrastive Vision-Language Pre-training for Question Answering tasks in 3D Scenes
Jun 04, 2023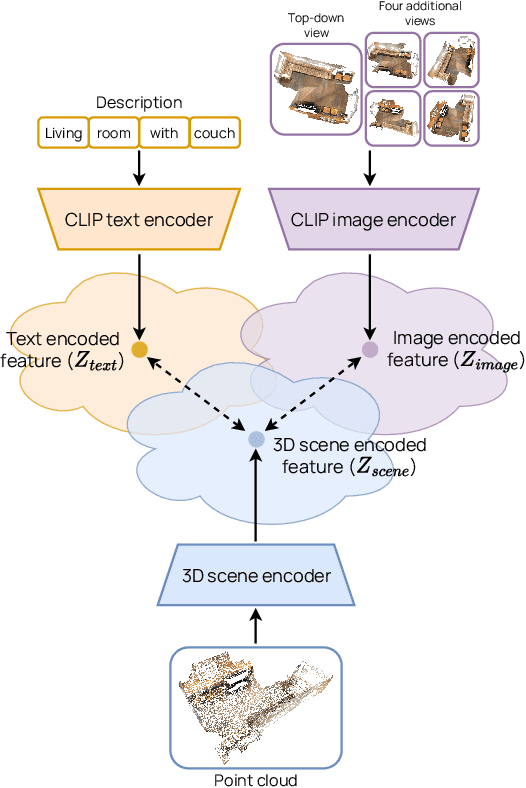
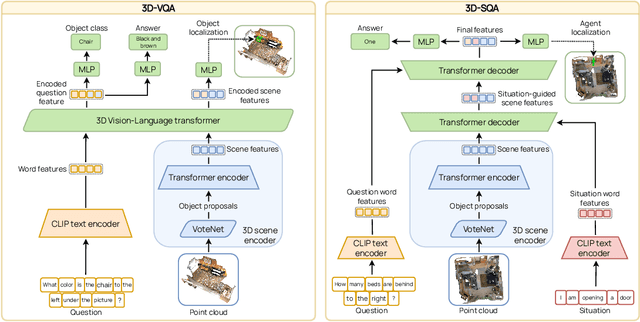
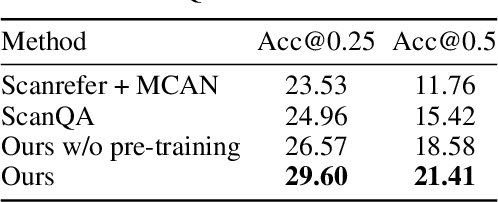
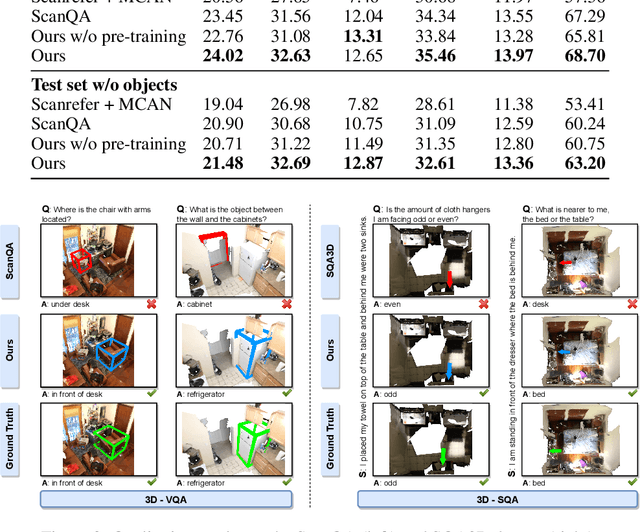
Training models to apply common-sense linguistic knowledge and visual concepts from 2D images to 3D scene understanding is a promising direction that researchers have only recently started to explore. However, it still remains understudied whether 2D distilled knowledge can provide useful representations for downstream 3D vision-language tasks such as 3D question answering. In this paper, we propose a novel 3D pre-training Vision-Language method, namely Multi-CLIP, that enables a model to learn language-grounded and transferable 3D scene point cloud representations. We leverage the representational power of the CLIP model by maximizing the agreement between the encoded 3D scene features and the corresponding 2D multi-view image and text embeddings in the CLIP space via a contrastive objective. To validate our approach, we consider the challenging downstream tasks of 3D Visual Question Answering (3D-VQA) and 3D Situated Question Answering (3D-SQA). To this end, we develop novel multi-modal transformer-based architectures and we demonstrate how our pre-training method can benefit their performance. Quantitative and qualitative experimental results show that Multi-CLIP outperforms state-of-the-art works across the downstream tasks of 3D-VQA and 3D-SQA and leads to a well-structured 3D scene feature space.
CLIP-Guided Vision-Language Pre-training for Question Answering in 3D Scenes
Apr 12, 2023



Training models to apply linguistic knowledge and visual concepts from 2D images to 3D world understanding is a promising direction that researchers have only recently started to explore. In this work, we design a novel 3D pre-training Vision-Language method that helps a model learn semantically meaningful and transferable 3D scene point cloud representations. We inject the representational power of the popular CLIP model into our 3D encoder by aligning the encoded 3D scene features with the corresponding 2D image and text embeddings produced by CLIP. To assess our model's 3D world reasoning capability, we evaluate it on the downstream task of 3D Visual Question Answering. Experimental quantitative and qualitative results show that our pre-training method outperforms state-of-the-art works in this task and leads to an interpretable representation of 3D scene features.
Removing Noise from Extracellular Neural Recordings Using Fully Convolutional Denoising Autoencoders
Sep 18, 2021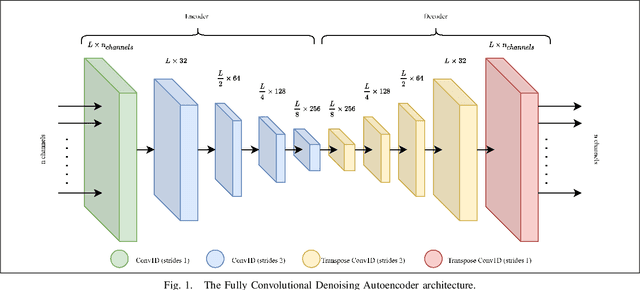
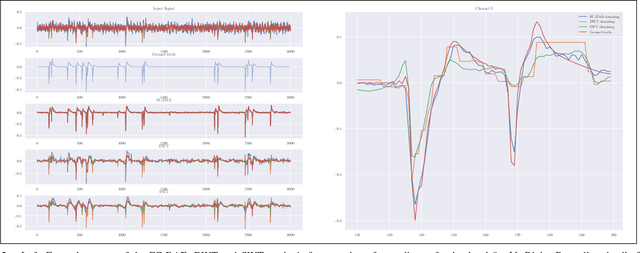
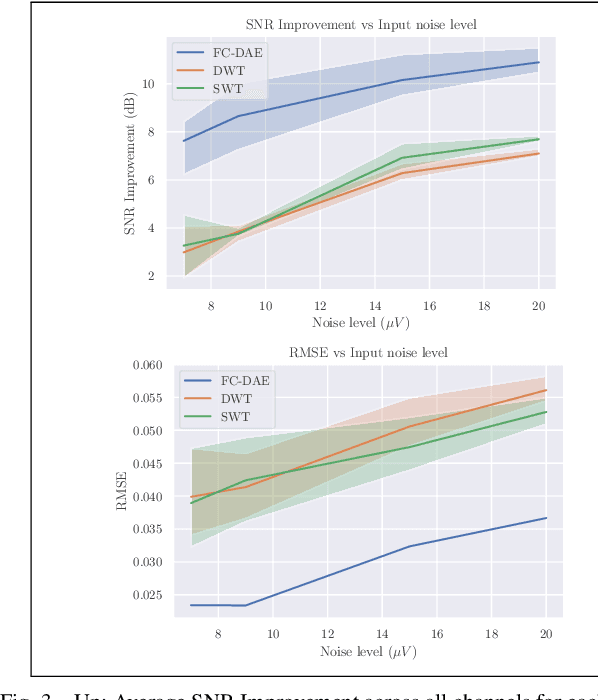

Extracellular recordings are severely contaminated by a considerable amount of noise sources, rendering the denoising process an extremely challenging task that should be tackled for efficient spike sorting. To this end, we propose an end-to-end deep learning approach to the problem, utilizing a Fully Convolutional Denoising Autoencoder, which learns to produce a clean neuronal activity signal from a noisy multichannel input. The experimental results on simulated data show that our proposed method can improve significantly the quality of noise-corrupted neural signals, outperforming widely-used wavelet denoising techniques.