 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicHOI: Leveraging 3D Priors for Accurate Hand-object Reconstruction from Short Monocular Video Clips
Aug 07, 2025



Most RGB-based hand-object reconstruction methods rely on object templates, while template-free methods typically assume full object visibility. This assumption often breaks in real-world settings, where fixed camera viewpoints and static grips leave parts of the object unobserved, resulting in implausible reconstructions. To overcome this, we present MagicHOI, a method for reconstructing hands and objects from short monocular interaction videos, even under limited viewpoint variation. Our key insight is that, despite the scarcity of paired 3D hand-object data, large-scale novel view synthesis diffusion models offer rich object supervision. This supervision serves as a prior to regularize unseen object regions during hand interactions. Leveraging this insight, we integrate a novel view synthesis model into our hand-object reconstruction framework. We further align hand to object by incorporating visible contact constraints. Our results demonstrate that MagicHOI significantly outperforms existing state-of-the-art hand-object reconstruction methods. We also show that novel view synthesis diffusion priors effectively regularize unseen object regions, enhancing 3D hand-object reconstruction.
HOLD: Category-agnostic 3D Reconstruction of Interacting Hands and Objects from Video
Nov 30, 2023

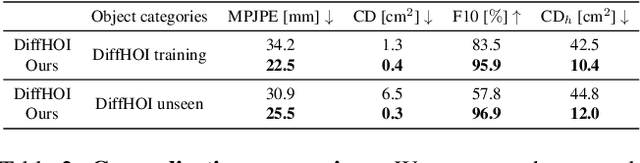
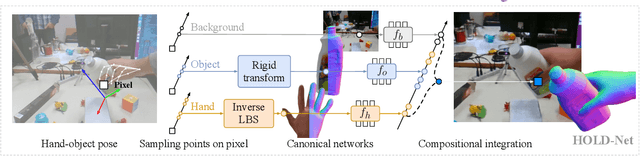
Since humans interact with diverse objects every day, the holistic 3D capture of these interactions is important to understand and model human behaviour. However, most existing methods for hand-object reconstruction from RGB either assume pre-scanned object templates or heavily rely on limited 3D hand-object data, restricting their ability to scale and generalize to more unconstrained interaction settings. To this end, we introduce HOLD -- the first category-agnostic method that reconstructs an articulated hand and object jointly from a monocular interaction video. We develop a compositional articulated implicit model that can reconstruct disentangled 3D hand and object from 2D images. We also further incorporate hand-object constraints to improve hand-object poses and consequently the reconstruction quality. Our method does not rely on 3D hand-object annotations while outperforming fully-supervised baselines in both in-the-lab and challenging in-the-wild settings. Moreover, we qualitatively show its robustness in reconstructing from in-the-wild videos. Code: https://github.com/zc-alexfan/hold
Interpretable Visual Question Answering via Reasoning Supervision
Sep 07, 2023Transformer-based architectures have recently demonstrated remarkable performance in the Visual Question Answering (VQA) task. However, such models are likely to disregard crucial visual cues and often rely on multimodal shortcuts and inherent biases of the language modality to predict the correct answer, a phenomenon commonly referred to as lack of visual grounding. In this work, we alleviate this shortcoming through a novel architecture for visual question answering that leverages common sense reasoning as a supervisory signal. Reasoning supervision takes the form of a textual justification of the correct answer, with such annotations being already available on large-scale Visual Common Sense Reasoning (VCR) datasets. The model's visual attention is guided toward important elements of the scene through a similarity loss that aligns the learned attention distributions guided by the question and the correct reasoning. We demonstrate both quantitatively and qualitatively that the proposed approach can boost the model's visual perception capability and lead to performance increase, without requiring training on explicit grounding annotations.
Multi-CLIP: Contrastive Vision-Language Pre-training for Question Answering tasks in 3D Scenes
Jun 04, 2023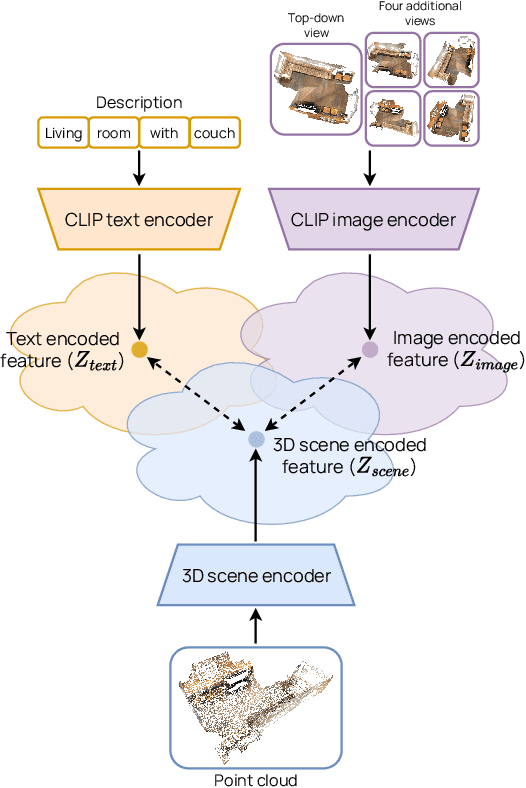
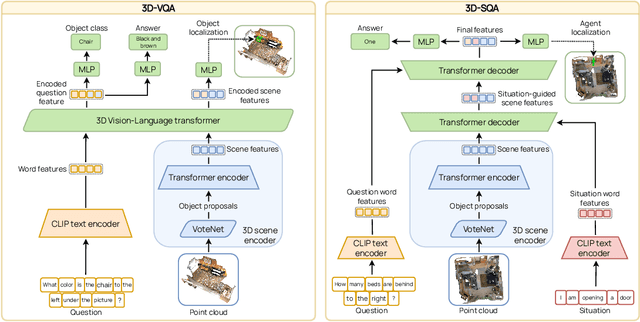
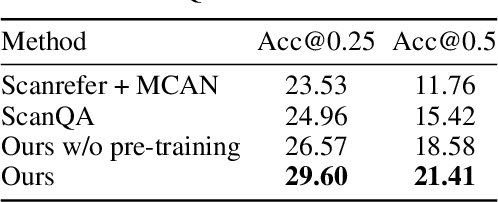
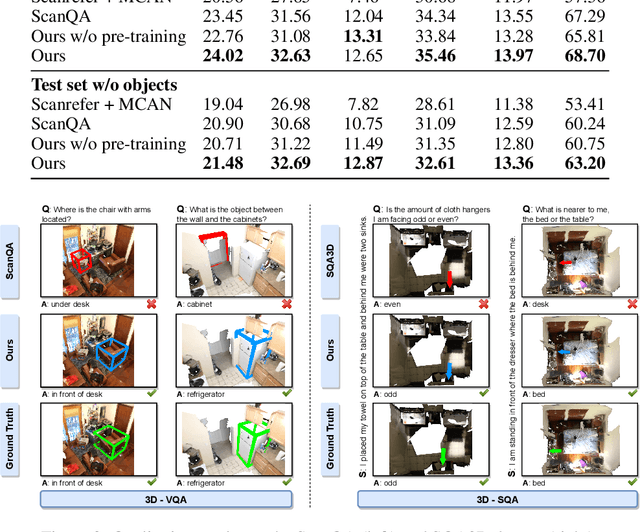
Training models to apply common-sense linguistic knowledge and visual concepts from 2D images to 3D scene understanding is a promising direction that researchers have only recently started to explore. However, it still remains understudied whether 2D distilled knowledge can provide useful representations for downstream 3D vision-language tasks such as 3D question answering. In this paper, we propose a novel 3D pre-training Vision-Language method, namely Multi-CLIP, that enables a model to learn language-grounded and transferable 3D scene point cloud representations. We leverage the representational power of the CLIP model by maximizing the agreement between the encoded 3D scene features and the corresponding 2D multi-view image and text embeddings in the CLIP space via a contrastive objective. To validate our approach, we consider the challenging downstream tasks of 3D Visual Question Answering (3D-VQA) and 3D Situated Question Answering (3D-SQA). To this end, we develop novel multi-modal transformer-based architectures and we demonstrate how our pre-training method can benefit their performance. Quantitative and qualitative experimental results show that Multi-CLIP outperforms state-of-the-art works across the downstream tasks of 3D-VQA and 3D-SQA and leads to a well-structured 3D scene feature space.
CLIP-Guided Vision-Language Pre-training for Question Answering in 3D Scenes
Apr 12, 2023



Training models to apply linguistic knowledge and visual concepts from 2D images to 3D world understanding is a promising direction that researchers have only recently started to explore. In this work, we design a novel 3D pre-training Vision-Language method that helps a model learn semantically meaningful and transferable 3D scene point cloud representations. We inject the representational power of the popular CLIP model into our 3D encoder by aligning the encoded 3D scene features with the corresponding 2D image and text embeddings produced by CLIP. To assess our model's 3D world reasoning capability, we evaluate it on the downstream task of 3D Visual Question Answering. Experimental quantitative and qualitative results show that our pre-training method outperforms state-of-the-art works in this task and leads to an interpretable representation of 3D scene features.