 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNIL: No-data Imitation Learning by Leveraging Pre-trained Video Diffusion Models
Mar 13, 2025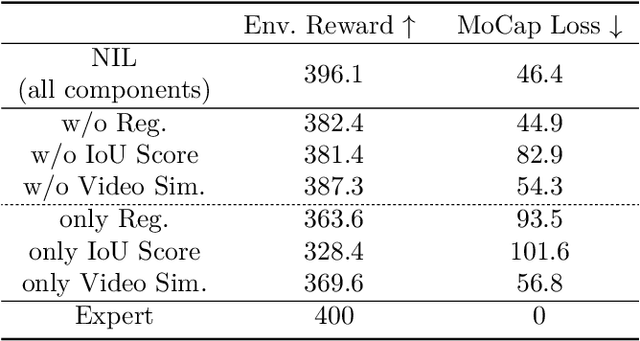
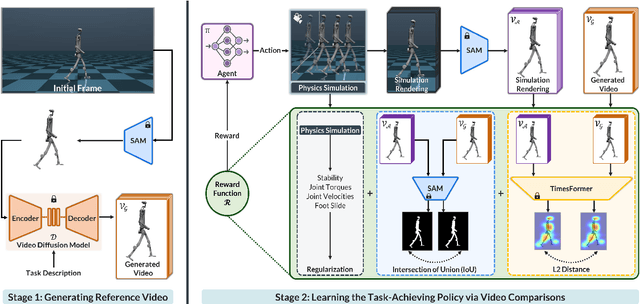
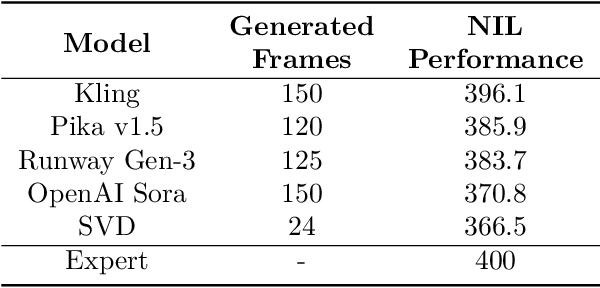
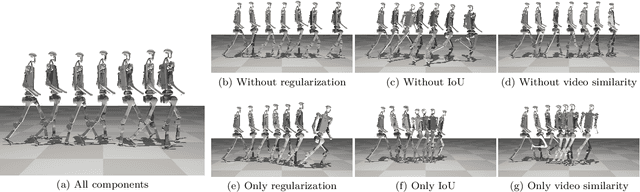
Acquiring physically plausible motor skills across diverse and unconventional morphologies-including humanoid robots, quadrupeds, and animals-is essential for advancing character simulation and robotics. Traditional methods, such as reinforcement learning (RL) are task- and body-specific, require extensive reward function engineering, and do not generalize well. Imitation learning offers an alternative but relies heavily on high-quality expert demonstrations, which are difficult to obtain for non-human morphologies. Video diffusion models, on the other hand, are capable of generating realistic videos of various morphologies, from humans to ants. Leveraging this capability, we propose a data-independent approach for skill acquisition that learns 3D motor skills from 2D-generated videos, with generalization capability to unconventional and non-human forms. Specifically, we guide the imitation learning process by leveraging vision transformers for video-based comparisons by calculating pair-wise distance between video embeddings. Along with video-encoding distance, we also use a computed similarity between segmented video frames as a guidance reward. We validate our method on locomotion tasks involving unique body configurations. In humanoid robot locomotion tasks, we demonstrate that 'No-data Imitation Learning' (NIL) outperforms baselines trained on 3D motion-capture data. Our results highlight the potential of leveraging generative video models for physically plausible skill learning with diverse morphologies, effectively replacing data collection with data generation for imitation learning.
MotionFix: Text-Driven 3D Human Motion Editing
Aug 01, 2024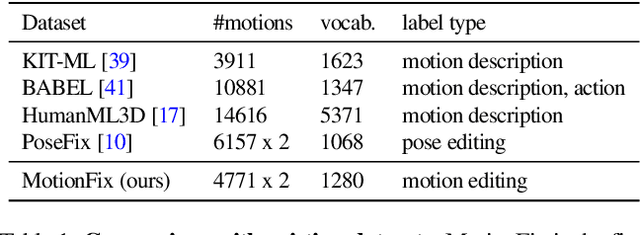

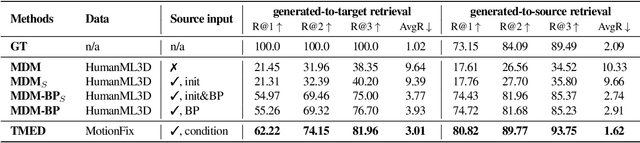
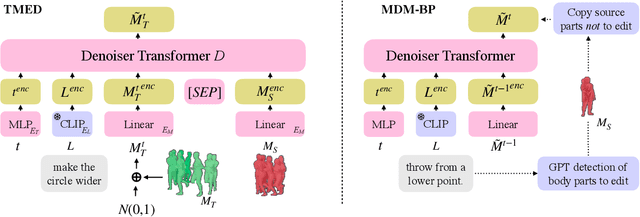
The focus of this paper is 3D motion editing. Given a 3D human motion and a textual description of the desired modification, our goal is to generate an edited motion as described by the text. The challenges include the lack of training data and the design of a model that faithfully edits the source motion. In this paper, we address both these challenges. We build a methodology to semi-automatically collect a dataset of triplets in the form of (i) a source motion, (ii) a target motion, and (iii) an edit text, and create the new MotionFix dataset. Having access to such data allows us to train a conditional diffusion model, TMED, that takes both the source motion and the edit text as input. We further build various baselines trained only on text-motion pairs datasets, and show superior performance of our model trained on triplets. We introduce new retrieval-based metrics for motion editing and establish a new benchmark on the evaluation set of MotionFix. Our results are encouraging, paving the way for further research on finegrained motion generation. Code and models will be made publicly available.
WANDR: Intention-guided Human Motion Generation
Apr 23, 2024Synthesizing natural human motions that enable a 3D human avatar to walk and reach for arbitrary goals in 3D space remains an unsolved problem with many applications. Existing methods (data-driven or using reinforcement learning) are limited in terms of generalization and motion naturalness. A primary obstacle is the scarcity of training data that combines locomotion with goal reaching. To address this, we introduce WANDR, a data-driven model that takes an avatar's initial pose and a goal's 3D position and generates natural human motions that place the end effector (wrist) on the goal location. To solve this, we introduce novel intention features that drive rich goal-oriented movement. Intention guides the agent to the goal, and interactively adapts the generation to novel situations without needing to define sub-goals or the entire motion path. Crucially, intention allows training on datasets that have goal-oriented motions as well as those that do not. WANDR is a conditional Variational Auto-Encoder (c-VAE), which we train using the AMASS and CIRCLE datasets. We evaluate our method extensively and demonstrate its ability to generate natural and long-term motions that reach 3D goals and generalize to unseen goal locations. Our models and code are available for research purposes at wandr.is.tue.mpg.de.
RelVAE: Generative Pretraining for few-shot Visual Relationship Detection
Nov 27, 2023Visual relations are complex, multimodal concepts that play an important role in the way humans perceive the world. As a result of their complexity, high-quality, diverse and large scale datasets for visual relations are still absent. In an attempt to overcome this data barrier, we choose to focus on the problem of few-shot Visual Relationship Detection (VRD), a setting that has been so far neglected by the community. In this work we present the first pretraining method for few-shot predicate classification that does not require any annotated relations. We achieve this by introducing a generative model that is able to capture the variation of semantic, visual and spatial information of relations inside a latent space and later exploiting its representations in order to achieve efficient few-shot classification. We construct few-shot training splits and show quantitative experiments on VG200 and VRD datasets where our model outperforms the baselines. Lastly we attempt to interpret the decisions of the model by conducting various qualitative experiments.
Self-Supervised Learning for Visual Relationship Detection through Masked Bounding Box Reconstruction
Nov 08, 2023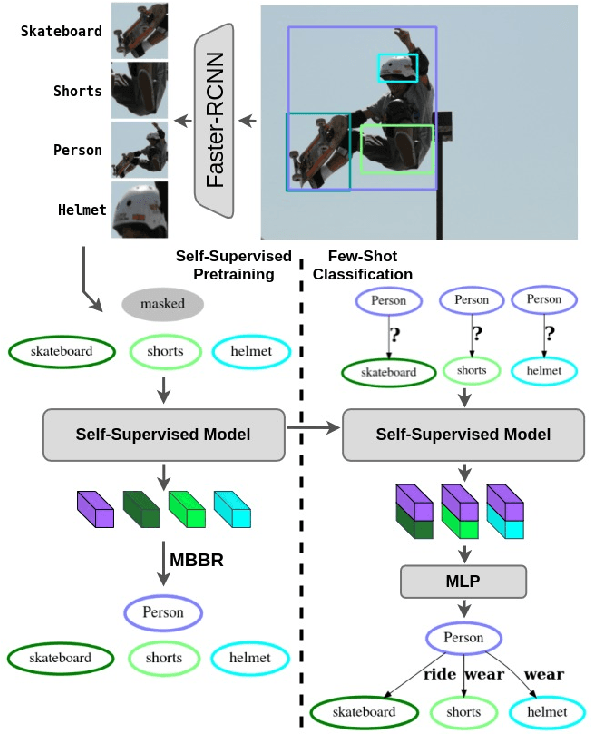
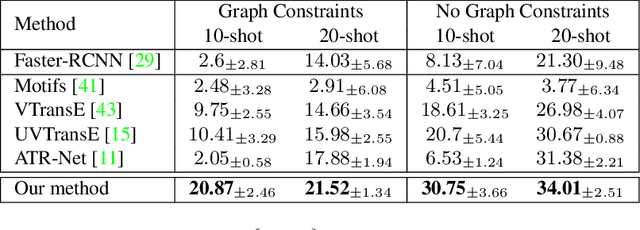
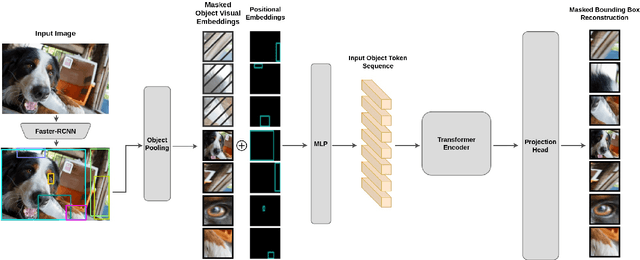
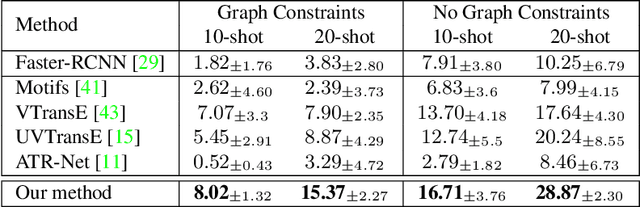
We present a novel self-supervised approach for representation learning, particularly for the task of Visual Relationship Detection (VRD). Motivated by the effectiveness of Masked Image Modeling (MIM), we propose Masked Bounding Box Reconstruction (MBBR), a variation of MIM where a percentage of the entities/objects within a scene are masked and subsequently reconstructed based on the unmasked objects. The core idea is that, through object-level masked modeling, the network learns context-aware representations that capture the interaction of objects within a scene and thus are highly predictive of visual object relationships. We extensively evaluate learned representations, both qualitatively and quantitatively, in a few-shot setting and demonstrate the efficacy of MBBR for learning robust visual representations, particularly tailored for VRD. The proposed method is able to surpass state-of-the-art VRD methods on the Predicate Detection (PredDet) evaluation setting, using only a few annotated samples. We make our code available at https://github.com/deeplab-ai/SelfSupervisedVRD.
Interpretable Visual Question Answering via Reasoning Supervision
Sep 07, 2023Transformer-based architectures have recently demonstrated remarkable performance in the Visual Question Answering (VQA) task. However, such models are likely to disregard crucial visual cues and often rely on multimodal shortcuts and inherent biases of the language modality to predict the correct answer, a phenomenon commonly referred to as lack of visual grounding. In this work, we alleviate this shortcoming through a novel architecture for visual question answering that leverages common sense reasoning as a supervisory signal. Reasoning supervision takes the form of a textual justification of the correct answer, with such annotations being already available on large-scale Visual Common Sense Reasoning (VCR) datasets. The model's visual attention is guided toward important elements of the scene through a similarity loss that aligns the learned attention distributions guided by the question and the correct reasoning. We demonstrate both quantitatively and qualitatively that the proposed approach can boost the model's visual perception capability and lead to performance increase, without requiring training on explicit grounding annotations.