 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap: Enabling Soft Actor Critic for High Performance Legged Locomotion
May 24, 2026Proximal Policy Optimization (PPO) has become the de facto standard for training legged robots, thanks to its robustness and scalability in massively parallel simulation environments like IsaacLab. However, its on-policy nature makes it inherently sample-inefficient, preventing its use for continuous adaptation and fine-tuning on real hardware. Soft Actor-Critic (SAC), by contrast, is an off-policy algorithm that can reuse past experience, making it a natural candidate for sim-to-real transfer workflows where the same algorithm can be used both in simulation and for online learning on the real robot. Despite these advantages, SAC has consistently failed to match PPO's empirical performance in massively parallel training settings. This work identifies the root causes of this gap and introduces targeted modifications, covering policy initialization, timeout-aware critic targets, and multi-step return estimation, that enable SAC to train stably at scale. Evaluated across multiple legged robot platforms and diverse locomotion tasks, our approach closes the performance gap with PPO entirely.
PruneTIR: Inference-Time Tool Call Pruning for Effective yet Efficient Tool-Integrated Reasoning
May 11, 2026Tool-integrated reasoning (TIR) enables large language models (LLMs) to enhance their capabilities by interacting with external tools, such as code interpreters (CI). Most recent studies focus on exploring various methods to equip LLMs with the ability to use tools. However, how to further boost the reasoning ability of already tool-capable LLMs at inference time remains underexplored. Improving reasoning at inference time requires no additional training and can help LLMs better leverage tools to solve problems. We observe that, during tool-capable LLM inference, both the number and the proportion of erroneous tool calls are negatively correlated with answer correctness. Moreover, erroneous tool calls are typically resolved successfully within a few subsequent turns. If not, LLMs often struggle to resolve such errors even with many additional turns. Building on the above observations, we propose PruneTIR, a rather effective yet efficient framework that enhances the tool-integrated reasoning at inference time. During LLM inference, PruneTIR prunes trajectories, resamples tool calls, and suspends tool usage through three components: Success-Triggered Pruning, Stuck-Triggered Pruning and Resampling, and Retry-Triggered Tool Suspension. These three components enable PruneTIR to mitigate the negative impact of erroneous tool calls and prevent LLMs from getting stuck in repeated failed resolution attempts, thereby improving overall LLM performance. Extensive experimental results demonstrate the effectiveness of PruneTIR, which significantly improves Pass@1 and efficiency while reducing the working context length for tool-capable LLMs.
PAINT: Partner-Agnostic Intent-Aware Cooperative Transport with Legged Robots
Apr 14, 2026Collaborative transport requires robots to infer partner intent through physical interaction while maintaining stable loco-manipulation. This becomes particularly challenging in complex environments, where interaction signals are difficult to capture and model. We present PAINT, a lightweight yet efficient hierarchical learning framework for partner-agonistic intent-aware collaborative legged transport that infers partner intent directly from proprioceptive feedback. PAINT decouples intent understanding from terrain-robust locomotion: A high-level policy infers the partner interaction wrench using an intent estimator and a teacher-student training scheme, while a low-level locomotion backbone ensures robust execution. This enables lightweight deployment without external force-torque sensing or payload tracking. Extensive simulation and real-world experiments demonstrate compliant cooperative transport across diverse terrains, payloads, and partners. Furthermore, we show that PAINT naturally scales to decentralized multi-robot transport and transfers across robot embodiments by swapping the underlying locomotion backbone. Our results suggest that proprioceptive signals in payload-coupled interaction provide a scalable interface for partner-agnostic intent-aware collaborative transport.
Toward Hardware-Agnostic Quadrupedal World Models via Morphology Conditioning
Apr 09, 2026World models promise a paradigm shift in robotics, where an agent learns the underlying physics of its environment once to enable efficient planning and behavior learning. However, current world models are often hardware-locked specialists: a model trained on a Boston Dynamics Spot robot fails catastrophically on a Unitree Go1 due to the mismatch in kinematic and dynamic properties, as the model overfits to specific embodiment constraints rather than capturing the universal locomotion dynamics. Consequently, a slight change in actuator dynamics or limb length necessitates training a new model from scratch. In this work, we take a step towards a framework for training a generalizable Quadrupedal World Model (QWM) that disentangles environmental dynamics from robot morphology. We address the limitations of implicit system identification, where treating static physical properties (like mass or limb length) as latent variables to be inferred from motion history creates an adaptation lag that can compromise zero-shot safety and efficiency. Instead, we explicitly condition the generative dynamics on the robot's engineering specifications. By integrating a physical morphology encoder and a reward normalizer, we enable the model to serve as a neural simulator capable of generalizing across morphologies. This capability unlocks zero-shot control across a range of embodiments. We introduce, for the first time, a world model that enables zero-shot generalization to new morphologies for locomotion. While we carefully study the limitations of our method, QWM operates as a distribution-bounded interpolator within the quadrupedal morphology family rather than a universal physics engine, this work represents a significant step toward morphology-conditioned world models for legged locomotion.
Hybrid Deep Learning with Temporal Data Augmentation for Accurate Remaining Useful Life Prediction of Lithium-Ion Batteries
Mar 28, 2026Accurate prediction of lithium-ion battery remaining useful life (RUL) is essential for reliable health monitoring and data-driven analysis of battery degradation. However, the robustness and generalization capabilities of existing RUL prediction models are significantly challenged by complex operating conditions and limited data availability. To address these limitations, this study proposes a hybrid deep learning model, CDFormer, which integrates convolutional neural networks, deep residual shrinkage networks, and Transformer encoders extract multiscale temporal features from battery measurement signals, including voltage, current, and capacity. This architecture enables the joint modeling of local and global degradation dynamics, effectively improving the accuracy of RUL prediction.To enhance predictive reliability, a composite temporal data augmentation strategy is proposed, incorporating Gaussian noise, time warping, and time resampling, explicitly accounting for measurement noise and variability. CDFormer is evaluated on two real-world datasets, with experimental results demonstrating its consistent superiority over conventional recurrent neural network-based and Transformer-based baselines across key metrics. By improving the reliability and predictive performance of RUL prediction from measurement data, CDFormer provides accurate and reliable forecasts, supporting effective battery health monitoring and data-driven maintenance strategies.
Revisiting Shape from Polarization in the Era of Vision Foundation Models
Mar 05, 2026We show that, with polarization cues, a lightweight model trained on a small dataset can outperform RGB-only vision foundation models (VFMs) in single-shot object-level surface normal estimation. Shape from polarization (SfP) has long been studied due to the strong physical relationship between polarization and surface geometry. Meanwhile, driven by scaling laws, RGB-only VFMs trained on large datasets have recently achieved impressive performance and surpassed existing SfP methods. This situation raises questions about the necessity of polarization cues, which require specialized hardware and have limited training data. We argue that the weaker performance of prior SfP methods does not come from the polarization modality itself, but from domain gaps. These domain gaps mainly arise from two sources. First, existing synthetic datasets use limited and unrealistic 3D objects, with simple geometry and random texture maps that do not match the underlying shapes. Second, real-world polarization signals are often affected by sensor noise, which is not well modeled during training. To address the first issue, we render a high-quality polarization dataset using 1,954 3D-scanned real-world objects. We further incorporate pretrained DINOv3 priors to improve generalization to unseen objects. To address the second issue, we introduce polarization sensor-aware data augmentation that better reflects real-world conditions. With only 40K training scenes, our method significantly outperforms both state-of-the-art SfP approaches and RGB-only VFMs. Extensive experiments show that polarization cues enable a 33x reduction in training data or an 8x reduction in model parameters, while still achieving better performance than RGB-only counterparts.
What Matters for Simulation to Online Reinforcement Learning on Real Robots
Feb 23, 2026We investigate what specific design choices enable successful online reinforcement learning (RL) on physical robots. Across 100 real-world training runs on three distinct robotic platforms, we systematically ablate algorithmic, systems, and experimental decisions that are typically left implicit in prior work. We find that some widely used defaults can be harmful, while a set of robust, readily adopted design choices within standard RL practice yield stable learning across tasks and hardware. These results provide the first large-sample empirical study of such design choices, enabling practitioners to deploy online RL with lower engineering effort.
Scaling Rough Terrain Locomotion with Automatic Curriculum Reinforcement Learning
Jan 24, 2026Curriculum learning has demonstrated substantial effectiveness in robot learning. However, it still faces limitations when scaling to complex, wide-ranging task spaces. Such task spaces often lack a well-defined difficulty structure, making the difficulty ordering required by previous methods challenging to define. We propose a Learning Progress-based Automatic Curriculum Reinforcement Learning (LP-ACRL) framework, which estimates the agent's learning progress online and adaptively adjusts the task-sampling distribution, thereby enabling automatic curriculum generation without prior knowledge of the difficulty distribution over the task space. Policies trained with LP-ACRL enable the ANYmal D quadruped to achieve and maintain stable, high-speed locomotion at 2.5 m/s linear velocity and 3.0 rad/s angular velocity across diverse terrains, including stairs, slopes, gravel, and low-friction flat surfaces--whereas previous methods have generally been limited to high speeds on flat terrain or low speeds on complex terrain. Experimental results demonstrate that LP-ACRL exhibits strong scalability and real-world applicability, providing a robust baseline for future research on curriculum generation in complex, wide-ranging robotic learning task spaces.
ActiShade: Activating Overshadowed Knowledge to Guide Multi-Hop Reasoning in Large Language Models
Jan 12, 2026In multi-hop reasoning, multi-round retrieval-augmented generation (RAG) methods typically rely on LLM-generated content as the retrieval query. However, these approaches are inherently vulnerable to knowledge overshadowing - a phenomenon where critical information is overshadowed during generation. As a result, the LLM-generated content may be incomplete or inaccurate, leading to irrelevant retrieval and causing error accumulation during the iteration process. To address this challenge, we propose ActiShade, which detects and activates overshadowed knowledge to guide large language models (LLMs) in multi-hop reasoning. Specifically, ActiShade iteratively detects the overshadowed keyphrase in the given query, retrieves documents relevant to both the query and the overshadowed keyphrase, and generates a new query based on the retrieved documents to guide the next-round iteration. By supplementing the overshadowed knowledge during the formulation of next-round queries while minimizing the introduction of irrelevant noise, ActiShade reduces the error accumulation caused by knowledge overshadowing. Extensive experiments show that ActiShade outperforms existing methods across multiple datasets and LLMs.
Multi-Domain Motion Embedding: Expressive Real-Time Mimicry for Legged Robots
Dec 08, 2025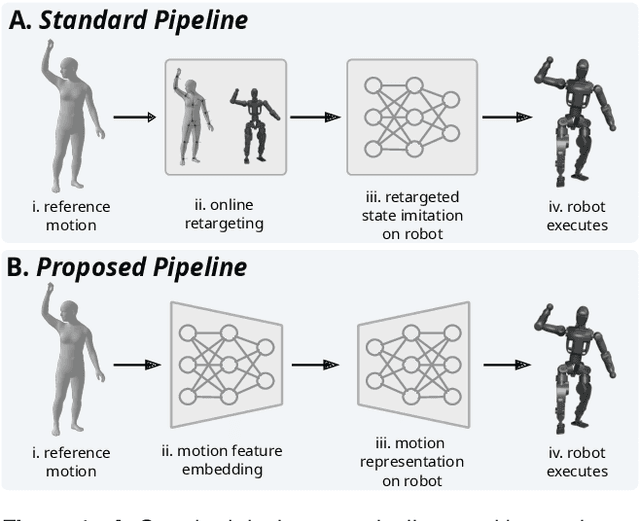

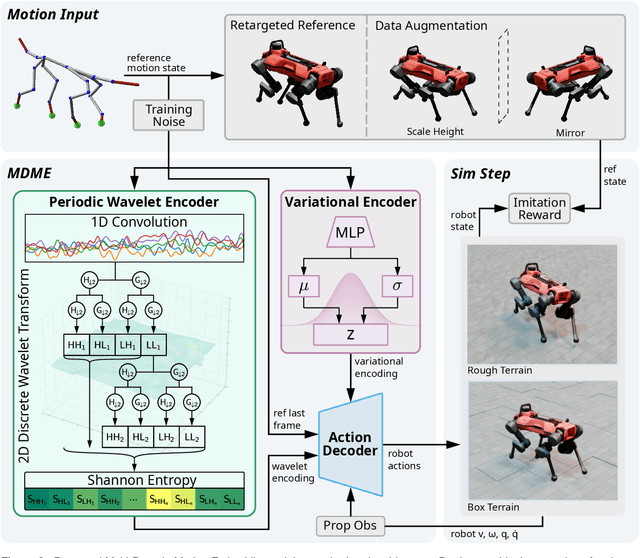

Effective motion representation is crucial for enabling robots to imitate expressive behaviors in real time, yet existing motion controllers often ignore inherent patterns in motion. Previous efforts in representation learning do not attempt to jointly capture structured periodic patterns and irregular variations in human and animal movement. To address this, we present Multi-Domain Motion Embedding (MDME), a motion representation that unifies the embedding of structured and unstructured features using a wavelet-based encoder and a probabilistic embedding in parallel. This produces a rich representation of reference motions from a minimal input set, enabling improved generalization across diverse motion styles and morphologies. We evaluate MDME on retargeting-free real-time motion imitation by conditioning robot control policies on the learned embeddings, demonstrating accurate reproduction of complex trajectories on both humanoid and quadruped platforms. Our comparative studies confirm that MDME outperforms prior approaches in reconstruction fidelity and generalizability to unseen motions. Furthermore, we demonstrate that MDME can reproduce novel motion styles in real-time through zero-shot deployment, eliminating the need for task-specific tuning or online retargeting. These results position MDME as a generalizable and structure-aware foundation for scalable real-time robot imitation.