 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNIL: No-data Imitation Learning by Leveraging Pre-trained Video Diffusion Models
Paper and Code
Mar 13, 2025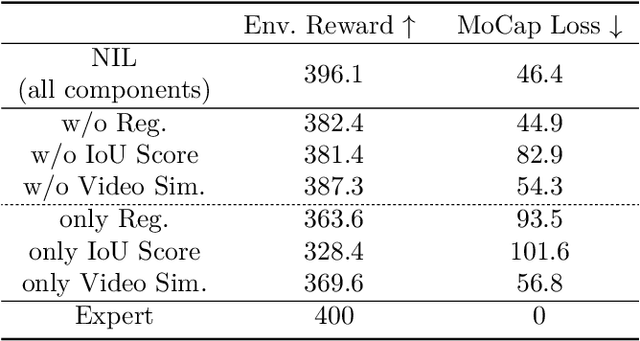
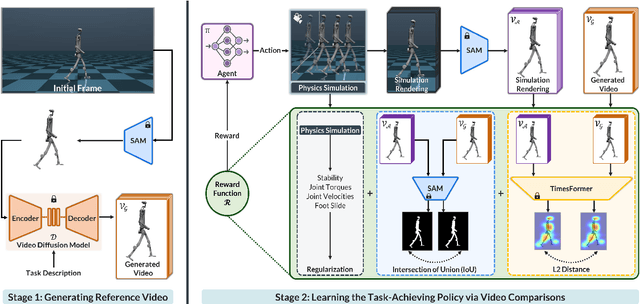
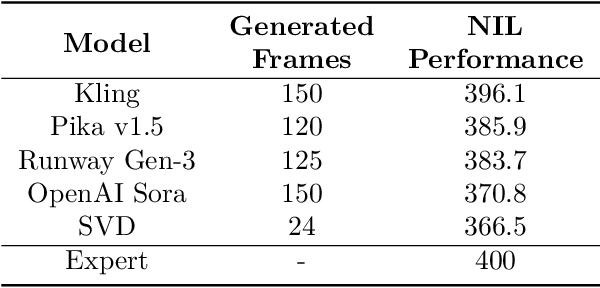
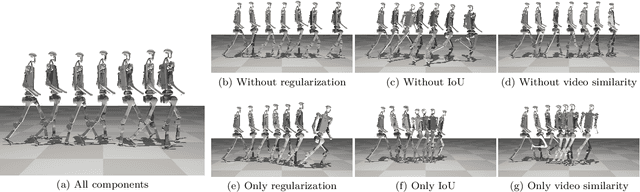
Acquiring physically plausible motor skills across diverse and unconventional morphologies-including humanoid robots, quadrupeds, and animals-is essential for advancing character simulation and robotics. Traditional methods, such as reinforcement learning (RL) are task- and body-specific, require extensive reward function engineering, and do not generalize well. Imitation learning offers an alternative but relies heavily on high-quality expert demonstrations, which are difficult to obtain for non-human morphologies. Video diffusion models, on the other hand, are capable of generating realistic videos of various morphologies, from humans to ants. Leveraging this capability, we propose a data-independent approach for skill acquisition that learns 3D motor skills from 2D-generated videos, with generalization capability to unconventional and non-human forms. Specifically, we guide the imitation learning process by leveraging vision transformers for video-based comparisons by calculating pair-wise distance between video embeddings. Along with video-encoding distance, we also use a computed similarity between segmented video frames as a guidance reward. We validate our method on locomotion tasks involving unique body configurations. In humanoid robot locomotion tasks, we demonstrate that 'No-data Imitation Learning' (NIL) outperforms baselines trained on 3D motion-capture data. Our results highlight the potential of leveraging generative video models for physically plausible skill learning with diverse morphologies, effectively replacing data collection with data generation for imitation learning.