 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMO: Unified In-Context Learning Unlocks Motion Foundation Model Priors
Mar 16, 2026Large-scale foundation models (LFMs) have recently made impressive progress in text-to-motion generation by learning strong generative priors from massive 3D human motion datasets and paired text descriptions. However, how to effectively and efficiently leverage such single-purpose motion LFMs, i.e., text-to-motion synthesis, in more diverse cross-modal and in-context motion generation downstream tasks remains largely unclear. Prior work typically adapts pretrained generative priors to individual downstream tasks in a task-specific manner. In contrast, our goal is to unlock such priors to support a broad spectrum of downstream motion generation tasks within a single unified framework. To bridge this gap, we present UMO, a simple yet general unified formulation that casts diverse downstream tasks into compositions of atomic per-frame operations, enabling in-context adaptation to unlock the generative priors of pretrained DiT-based motion LFMs. Specifically, UMO introduces three learnable frame-level meta-operation embeddings to specify per-frame intent and employs lightweight temporal fusion to inject in-context cues into the pretrained backbone, with negligible runtime overhead compared to the base model. With this design, UMO finetunes the pretrained model, originally limited to text-to-motion generation, to support diverse previously unsupported tasks, including temporal inpainting, text-guided motion editing, text-serialized geometric constraints, and multi-identity reaction generation. Experiments demonstrate that UMO consistently outperforms task-specific and training-free baselines across a wide range of benchmarks, despite using a single unified model. Code and model will be publicly available. Project Page: https://oliver-cong02.github.io/UMO.github.io/
NGL-Prompter: Training-Free Sewing Pattern Estimation from a Single Image
Feb 24, 2026Estimating sewing patterns from images is a practical approach for creating high-quality 3D garments. Due to the lack of real-world pattern-image paired data, prior approaches fine-tune large vision language models (VLMs) on synthetic garment datasets generated by randomly sampling from a parametric garment model GarmentCode. However, these methods often struggle to generalize to in-the-wild images, fail to capture real-world correlations between garment parts, and are typically restricted to single-layer outfits. In contrast, we observe that VLMs are effective at describing garments in natural language, yet perform poorly when asked to directly regress GarmentCode parameters from images. To bridge this gap, we propose NGL (Natural Garment Language), a novel intermediate language that restructures GarmentCode into a representation more understandable to language models. Leveraging this language, we introduce NGL-Prompter, a training-free pipeline that queries large VLMs to extract structured garment parameters, which are then deterministically mapped to valid GarmentCode. We evaluate our method on the Dress4D, CloSe and a newly collected dataset of approximately 5,000 in-the-wild fashion images. Our approach achieves state-of-the-art performance on standard geometry metrics and is strongly preferred in both human and GPT-based perceptual evaluations compared to existing baselines. Furthermore, NGL-prompter can recover multi-layer outfits whereas competing methods focus mostly on single-layer garments, highlighting its strong generalization to real-world images even with occluded parts. These results demonstrate that accurate sewing pattern reconstruction is possible without costly model training. Our code and data will be released for research use.
FUSION: Full-Body Unified Motion Prior for Body and Hands via Diffusion
Jan 07, 2026Hands are central to interacting with our surroundings and conveying gestures, making their inclusion essential for full-body motion synthesis. Despite this, existing human motion synthesis methods fall short: some ignore hand motions entirely, while others generate full-body motions only for narrowly scoped tasks under highly constrained settings. A key obstacle is the lack of large-scale datasets that jointly capture diverse full-body motion with detailed hand articulation. While some datasets capture both, they are limited in scale and diversity. Conversely, large-scale datasets typically focus either on body motion without hands or on hand motions without the body. To overcome this, we curate and unify existing hand motion datasets with large-scale body motion data to generate full-body sequences that capture both hand and body. We then propose the first diffusion-based unconditional full-body motion prior, FUSION, which jointly models body and hand motion. Despite using a pose-based motion representation, FUSION surpasses state-of-the-art skeletal control models on the Keypoint Tracking task in the HumanML3D dataset and achieves superior motion naturalness. Beyond standard benchmarks, we demonstrate that FUSION can go beyond typical uses of motion priors through two applications: (1) generating detailed full-body motion including fingers during interaction given the motion of an object, and (2) generating Self-Interaction motions using an LLM to transform natural language cues into actionable motion constraints. For these applications, we develop an optimization pipeline that refines the latent space of our diffusion model to generate task-specific motions. Experiments on these tasks highlight precise control over hand motion while maintaining plausible full-body coordination. The code will be public.
InteractVLM: 3D Interaction Reasoning from 2D Foundational Models
Apr 07, 2025We introduce InteractVLM, a novel method to estimate 3D contact points on human bodies and objects from single in-the-wild images, enabling accurate human-object joint reconstruction in 3D. This is challenging due to occlusions, depth ambiguities, and widely varying object shapes. Existing methods rely on 3D contact annotations collected via expensive motion-capture systems or tedious manual labeling, limiting scalability and generalization. To overcome this, InteractVLM harnesses the broad visual knowledge of large Vision-Language Models (VLMs), fine-tuned with limited 3D contact data. However, directly applying these models is non-trivial, as they reason only in 2D, while human-object contact is inherently 3D. Thus we introduce a novel Render-Localize-Lift module that: (1) embeds 3D body and object surfaces in 2D space via multi-view rendering, (2) trains a novel multi-view localization model (MV-Loc) to infer contacts in 2D, and (3) lifts these to 3D. Additionally, we propose a new task called Semantic Human Contact estimation, where human contact predictions are conditioned explicitly on object semantics, enabling richer interaction modeling. InteractVLM outperforms existing work on contact estimation and also facilitates 3D reconstruction from an in-the wild image. Code and models are available at https://interactvlm.is.tue.mpg.de.
NIL: No-data Imitation Learning by Leveraging Pre-trained Video Diffusion Models
Mar 13, 2025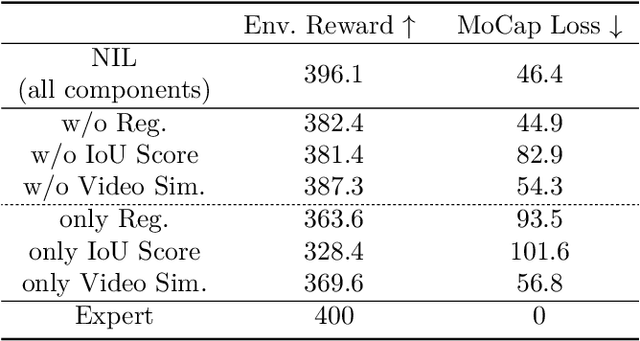
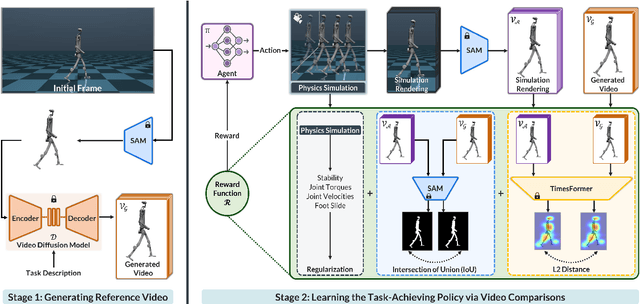
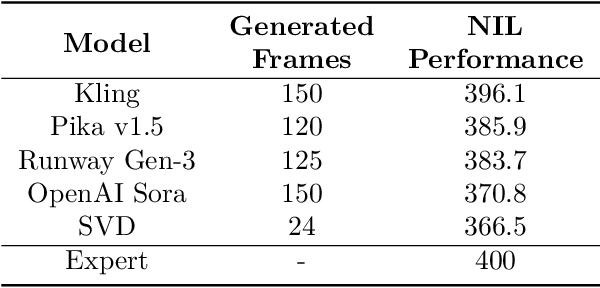
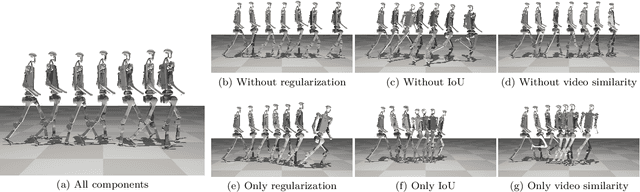
Acquiring physically plausible motor skills across diverse and unconventional morphologies-including humanoid robots, quadrupeds, and animals-is essential for advancing character simulation and robotics. Traditional methods, such as reinforcement learning (RL) are task- and body-specific, require extensive reward function engineering, and do not generalize well. Imitation learning offers an alternative but relies heavily on high-quality expert demonstrations, which are difficult to obtain for non-human morphologies. Video diffusion models, on the other hand, are capable of generating realistic videos of various morphologies, from humans to ants. Leveraging this capability, we propose a data-independent approach for skill acquisition that learns 3D motor skills from 2D-generated videos, with generalization capability to unconventional and non-human forms. Specifically, we guide the imitation learning process by leveraging vision transformers for video-based comparisons by calculating pair-wise distance between video embeddings. Along with video-encoding distance, we also use a computed similarity between segmented video frames as a guidance reward. We validate our method on locomotion tasks involving unique body configurations. In humanoid robot locomotion tasks, we demonstrate that 'No-data Imitation Learning' (NIL) outperforms baselines trained on 3D motion-capture data. Our results highlight the potential of leveraging generative video models for physically plausible skill learning with diverse morphologies, effectively replacing data collection with data generation for imitation learning.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Predicting 4D Hand Trajectory from Monocular Videos
Jan 14, 2025



We present HaPTIC, an approach that infers coherent 4D hand trajectories from monocular videos. Current video-based hand pose reconstruction methods primarily focus on improving frame-wise 3D pose using adjacent frames rather than studying consistent 4D hand trajectories in space. Despite the additional temporal cues, they generally underperform compared to image-based methods due to the scarcity of annotated video data. To address these issues, we repurpose a state-of-the-art image-based transformer to take in multiple frames and directly predict a coherent trajectory. We introduce two types of lightweight attention layers: cross-view self-attention to fuse temporal information, and global cross-attention to bring in larger spatial context. Our method infers 4D hand trajectories similar to the ground truth while maintaining strong 2D reprojection alignment. We apply the method to both egocentric and allocentric videos. It significantly outperforms existing methods in global trajectory accuracy while being comparable to the state-of-the-art in single-image pose estimation. Project website: https://judyye.github.io/haptic-www
A Versatile and Differentiable Hand-Object Interaction Representation
Sep 25, 2024



Synthesizing accurate hands-object interactions (HOI) is critical for applications in Computer Vision, Augmented Reality (AR), and Mixed Reality (MR). Despite recent advances, the accuracy of reconstructed or generated HOI leaves room for refinement. Some techniques have improved the accuracy of dense correspondences by shifting focus from generating explicit contacts to using rich HOI fields. Still, they lack full differentiability or continuity and are tailored to specific tasks. In contrast, we present a Coarse Hand-Object Interaction Representation (CHOIR), a novel, versatile and fully differentiable field for HOI modelling. CHOIR leverages discrete unsigned distances for continuous shape and pose encoding, alongside multivariate Gaussian distributions to represent dense contact maps with few parameters. To demonstrate the versatility of CHOIR we design JointDiffusion, a diffusion model to learn a grasp distribution conditioned on noisy hand-object interactions or only object geometries, for both refinement and synthesis applications. We demonstrate JointDiffusion's improvements over the SOTA in both applications: it increases the contact F1 score by $5\%$ for refinement and decreases the sim. displacement by $46\%$ for synthesis. Our experiments show that JointDiffusion with CHOIR yield superior contact accuracy and physical realism compared to SOTA methods designed for specific tasks. Our models and code will be publicly available to the research community.
HUMOS: Human Motion Model Conditioned on Body Shape
Sep 05, 2024
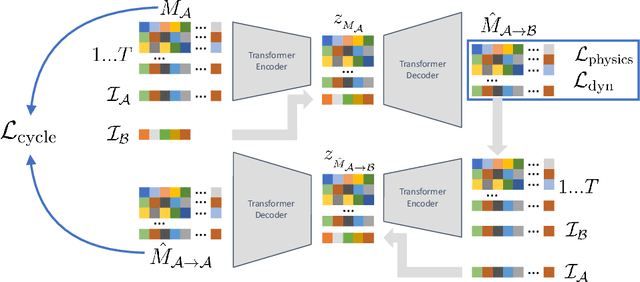
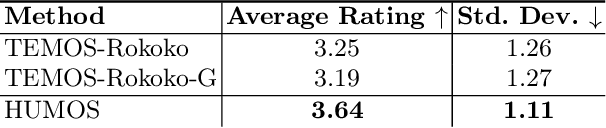

Generating realistic human motion is essential for many computer vision and graphics applications. The wide variety of human body shapes and sizes greatly impacts how people move. However, most existing motion models ignore these differences, relying on a standardized, average body. This leads to uniform motion across different body types, where movements don't match their physical characteristics, limiting diversity. To solve this, we introduce a new approach to develop a generative motion model based on body shape. We show that it's possible to train this model using unpaired data by applying cycle consistency, intuitive physics, and stability constraints, which capture the relationship between identity and movement. The resulting model generates diverse, physically plausible, and dynamically stable human motions that are both quantitatively and qualitatively more realistic than current state-of-the-art methods. More details are available on our project page https://CarstenEpic.github.io/humos/.
3D Whole-body Grasp Synthesis with Directional Controllability
Aug 29, 2024Synthesizing 3D whole-bodies that realistically grasp objects is useful for animation, mixed reality, and robotics. This is challenging, because the hands and body need to look natural w.r.t. each other, the grasped object, as well as the local scene (i.e., a receptacle supporting the object). Only recent work tackles this, with a divide-and-conquer approach; it first generates a "guiding" right-hand grasp, and then searches for bodies that match this. However, the guiding-hand synthesis lacks controllability and receptacle awareness, so it likely has an implausible direction (i.e., a body can't match this without penetrating the receptacle) and needs corrections through major post-processing. Moreover, the body search needs exhaustive sampling and is expensive. These are strong limitations. We tackle these with a novel method called CWGrasp. Our key idea is that performing geometry-based reasoning "early on," instead of "too late," provides rich "control" signals for inference. To this end, CWGrasp first samples a plausible reaching-direction vector (used later for both the arm and hand) from a probabilistic model built via raycasting from the object and collision checking. Then, it generates a reaching body with a desired arm direction, as well as a "guiding" grasping hand with a desired palm direction that complies with the arm's one. Eventually, CWGrasp refines the body to match the "guiding" hand, while plausibly contacting the scene. Notably, generating already-compatible "parts" greatly simplifies the "whole." Moreover, CWGrasp uniquely tackles both right- and left-hand grasps. We evaluate on the GRAB and ReplicaGrasp datasets. CWGrasp outperforms baselines, at lower runtime and budget, while all components help performance. Code and models will be released.