 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Vocabulary Functional 3D Human-Scene Interaction Generation
Jan 28, 2026Generating 3D humans that functionally interact with 3D scenes remains an open problem with applications in embodied AI, robotics, and interactive content creation. The key challenge involves reasoning about both the semantics of functional elements in 3D scenes and the 3D human poses required to achieve functionality-aware interaction. Unfortunately, existing methods typically lack explicit reasoning over object functionality and the corresponding human-scene contact, resulting in implausible or functionally incorrect interactions. In this work, we propose FunHSI, a training-free, functionality-driven framework that enables functionally correct human-scene interactions from open-vocabulary task prompts. Given a task prompt, FunHSI performs functionality-aware contact reasoning to identify functional scene elements, reconstruct their 3D geometry, and model high-level interactions via a contact graph. We then leverage vision-language models to synthesize a human performing the task in the image and estimate proposed 3D body and hand poses. Finally, the proposed 3D body configuration is refined via stage-wise optimization to ensure physical plausibility and functional correctness. In contrast to existing methods, FunHSI not only synthesizes more plausible general 3D interactions, such as "sitting on a sofa'', while supporting fine-grained functional human-scene interactions, e.g., "increasing the room temperature''. Extensive experiments demonstrate that FunHSI consistently generates functionally correct and physically plausible human-scene interactions across diverse indoor and outdoor scenes.
Vidarc: Embodied Video Diffusion Model for Closed-loop Control
Dec 19, 2025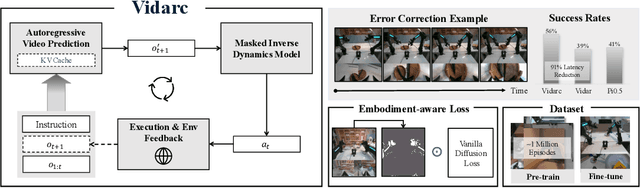
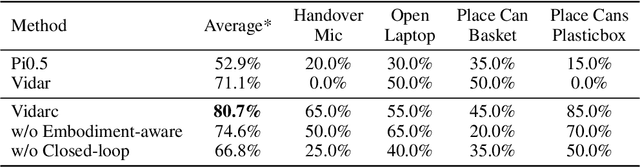
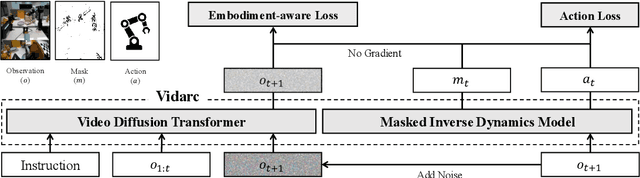
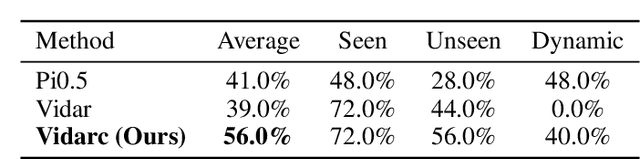
Robotic arm manipulation in data-scarce settings is a highly challenging task due to the complex embodiment dynamics and diverse contexts. Recent video-based approaches have shown great promise in capturing and transferring the temporal and physical interactions by pre-training on Internet-scale video data. However, such methods are often not optimized for the embodiment-specific closed-loop control, typically suffering from high latency and insufficient grounding. In this paper, we present Vidarc (Video Diffusion for Action Reasoning and Closed-loop Control), a novel autoregressive embodied video diffusion approach augmented by a masked inverse dynamics model. By grounding video predictions with action-relevant masks and incorporating real-time feedback through cached autoregressive generation, Vidarc achieves fast, accurate closed-loop control. Pre-trained on one million cross-embodiment episodes, Vidarc surpasses state-of-the-art baselines, achieving at least a 15% higher success rate in real-world deployment and a 91% reduction in latency. We also highlight its robust generalization and error correction capabilities across previously unseen robotic platforms.
Motus: A Unified Latent Action World Model
Dec 15, 2025While a general embodied agent must function as a unified system, current methods are built on isolated models for understanding, world modeling, and control. This fragmentation prevents unifying multimodal generative capabilities and hinders learning from large-scale, heterogeneous data. In this paper, we propose Motus, a unified latent action world model that leverages existing general pretrained models and rich, sharable motion information. Motus introduces a Mixture-of-Transformer (MoT) architecture to integrate three experts (i.e., understanding, video generation, and action) and adopts a UniDiffuser-style scheduler to enable flexible switching between different modeling modes (i.e., world models, vision-language-action models, inverse dynamics models, video generation models, and video-action joint prediction models). Motus further leverages the optical flow to learn latent actions and adopts a recipe with three-phase training pipeline and six-layer data pyramid, thereby extracting pixel-level "delta action" and enabling large-scale action pretraining. Experiments show that Motus achieves superior performance against state-of-the-art methods in both simulation (a +15% improvement over X-VLA and a +45% improvement over Pi0.5) and real-world scenarios(improved by +11~48%), demonstrating unified modeling of all functionalities and priors significantly benefits downstream robotic tasks.
GentleHumanoid: Learning Upper-body Compliance for Contact-rich Human and Object Interaction
Nov 06, 2025Humanoid robots are expected to operate in human-centered environments where safe and natural physical interaction is essential. However, most recent reinforcement learning (RL) policies emphasize rigid tracking and suppress external forces. Existing impedance-augmented approaches are typically restricted to base or end-effector control and focus on resisting extreme forces rather than enabling compliance. We introduce GentleHumanoid, a framework that integrates impedance control into a whole-body motion tracking policy to achieve upper-body compliance. At its core is a unified spring-based formulation that models both resistive contacts (restoring forces when pressing against surfaces) and guiding contacts (pushes or pulls sampled from human motion data). This formulation ensures kinematically consistent forces across the shoulder, elbow, and wrist, while exposing the policy to diverse interaction scenarios. Safety is further supported through task-adjustable force thresholds. We evaluate our approach in both simulation and on the Unitree G1 humanoid across tasks requiring different levels of compliance, including gentle hugging, sit-to-stand assistance, and safe object manipulation. Compared to baselines, our policy consistently reduces peak contact forces while maintaining task success, resulting in smoother and more natural interactions. These results highlight a step toward humanoid robots that can safely and effectively collaborate with humans and handle objects in real-world environments.
Results of the NeurIPS 2023 Neural MMO Competition on Multi-task Reinforcement Learning
Aug 17, 2025We present the results of the NeurIPS 2023 Neural MMO Competition, which attracted over 200 participants and submissions. Participants trained goal-conditional policies that generalize to tasks, maps, and opponents never seen during training. The top solution achieved a score 4x higher than our baseline within 8 hours of training on a single 4090 GPU. We open-source everything relating to Neural MMO and the competition under the MIT license, including the policy weights and training code for our baseline and for the top submissions.
Half-Physics: Enabling Kinematic 3D Human Model with Physical Interactions
Jul 31, 2025While current general-purpose 3D human models (e.g., SMPL-X) efficiently represent accurate human shape and pose, they lacks the ability to physically interact with the environment due to the kinematic nature. As a result, kinematic-based interaction models often suffer from issues such as interpenetration and unrealistic object dynamics. To address this limitation, we introduce a novel approach that embeds SMPL-X into a tangible entity capable of dynamic physical interactions with its surroundings. Specifically, we propose a "half-physics" mechanism that transforms 3D kinematic motion into a physics simulation. Our approach maintains kinematic control over inherent SMPL-X poses while ensuring physically plausible interactions with scenes and objects, effectively eliminating penetration and unrealistic object dynamics. Unlike reinforcement learning-based methods, which demand extensive and complex training, our half-physics method is learning-free and generalizes to any body shape and motion; meanwhile, it operates in real time. Moreover, it preserves the fidelity of the original kinematic motion while seamlessly integrating physical interactions
DiffLocks: Generating 3D Hair from a Single Image using Diffusion Models
May 09, 2025



We address the task of generating 3D hair geometry from a single image, which is challenging due to the diversity of hairstyles and the lack of paired image-to-3D hair data. Previous methods are primarily trained on synthetic data and cope with the limited amount of such data by using low-dimensional intermediate representations, such as guide strands and scalp-level embeddings, that require post-processing to decode, upsample, and add realism. These approaches fail to reconstruct detailed hair, struggle with curly hair, or are limited to handling only a few hairstyles. To overcome these limitations, we propose DiffLocks, a novel framework that enables detailed reconstruction of a wide variety of hairstyles directly from a single image. First, we address the lack of 3D hair data by automating the creation of the largest synthetic hair dataset to date, containing 40K hairstyles. Second, we leverage the synthetic hair dataset to learn an image-conditioned diffusion-transfomer model that generates accurate 3D strands from a single frontal image. By using a pretrained image backbone, our method generalizes to in-the-wild images despite being trained only on synthetic data. Our diffusion model predicts a scalp texture map in which any point in the map contains the latent code for an individual hair strand. These codes are directly decoded to 3D strands without post-processing techniques. Representing individual strands, instead of guide strands, enables the transformer to model the detailed spatial structure of complex hairstyles. With this, DiffLocks can recover highly curled hair, like afro hairstyles, from a single image for the first time. Data and code is available at https://radualexandru.github.io/difflocks/
Predicting 4D Hand Trajectory from Monocular Videos
Jan 14, 2025



We present HaPTIC, an approach that infers coherent 4D hand trajectories from monocular videos. Current video-based hand pose reconstruction methods primarily focus on improving frame-wise 3D pose using adjacent frames rather than studying consistent 4D hand trajectories in space. Despite the additional temporal cues, they generally underperform compared to image-based methods due to the scarcity of annotated video data. To address these issues, we repurpose a state-of-the-art image-based transformer to take in multiple frames and directly predict a coherent trajectory. We introduce two types of lightweight attention layers: cross-view self-attention to fuse temporal information, and global cross-attention to bring in larger spatial context. Our method infers 4D hand trajectories similar to the ground truth while maintaining strong 2D reprojection alignment. We apply the method to both egocentric and allocentric videos. It significantly outperforms existing methods in global trajectory accuracy while being comparable to the state-of-the-art in single-image pose estimation. Project website: https://judyye.github.io/haptic-www
ChatGarment: Garment Estimation, Generation and Editing via Large Language Models
Dec 23, 2024We introduce ChatGarment, a novel approach that leverages large vision-language models (VLMs) to automate the estimation, generation, and editing of 3D garments from images or text descriptions. Unlike previous methods that struggle in real-world scenarios or lack interactive editing capabilities, ChatGarment can estimate sewing patterns from in-the-wild images or sketches, generate them from text descriptions, and edit garments based on user instructions, all within an interactive dialogue. These sewing patterns can then be draped into 3D garments, which are easily animatable and simulatable. This is achieved by finetuning a VLM to directly generate a JSON file that includes both textual descriptions of garment types and styles, as well as continuous numerical attributes. This JSON file is then used to create sewing patterns through a programming parametric model. To support this, we refine the existing programming model, GarmentCode, by expanding its garment type coverage and simplifying its structure for efficient VLM fine-tuning. Additionally, we construct a large-scale dataset of image-to-sewing-pattern and text-to-sewing-pattern pairs through an automated data pipeline. Extensive evaluations demonstrate ChatGarment's ability to accurately reconstruct, generate, and edit garments from multimodal inputs, highlighting its potential to revolutionize workflows in fashion and gaming applications. Code and data will be available at https://chatgarment.github.io/.
ChatDyn: Language-Driven Multi-Actor Dynamics Generation in Street Scenes
Dec 11, 2024Generating realistic and interactive dynamics of traffic participants according to specific instruction is critical for street scene simulation. However, there is currently a lack of a comprehensive method that generates realistic dynamics of different types of participants including vehicles and pedestrians, with different kinds of interactions between them. In this paper, we introduce ChatDyn, the first system capable of generating interactive, controllable and realistic participant dynamics in street scenes based on language instructions. To achieve precise control through complex language, ChatDyn employs a multi-LLM-agent role-playing approach, which utilizes natural language inputs to plan the trajectories and behaviors for different traffic participants. To generate realistic fine-grained dynamics based on the planning, ChatDyn designs two novel executors: the PedExecutor, a unified multi-task executor that generates realistic pedestrian dynamics under different task plannings; and the VehExecutor, a physical transition-based policy that generates physically plausible vehicle dynamics. Extensive experiments show that ChatDyn can generate realistic driving scene dynamics with multiple vehicles and pedestrians, and significantly outperforms previous methods on subtasks. Code and model will be available at https://vfishc.github.io/chatdyn.