 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Apr 15, 2025We introduce Kimina-Prover Preview, a large language model that pioneers a novel reasoning-driven exploration paradigm for formal theorem proving, as showcased in this preview release. Trained with a large-scale reinforcement learning pipeline from Qwen2.5-72B, Kimina-Prover demonstrates strong performance in Lean 4 proof generation by employing a structured reasoning pattern we term \textit{formal reasoning pattern}. This approach allows the model to emulate human problem-solving strategies in Lean, iteratively generating and refining proof steps. Kimina-Prover sets a new state-of-the-art on the miniF2F benchmark, reaching 80.7% with pass@8192. Beyond improved benchmark performance, our work yields several key insights: (1) Kimina-Prover exhibits high sample efficiency, delivering strong results even with minimal sampling (pass@1) and scaling effectively with computational budget, stemming from its unique reasoning pattern and RL training; (2) we demonstrate clear performance scaling with model size, a trend previously unobserved for neural theorem provers in formal mathematics; (3) the learned reasoning style, distinct from traditional search algorithms, shows potential to bridge the gap between formal verification and informal mathematical intuition. We open source distilled versions with 1.5B and 7B parameters of Kimina-Prover
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
$\texttt{PatentAgent}$: Intelligent Agent for Automated Pharmaceutical Patent Analysis
Oct 25, 2024Pharmaceutical patents play a vital role in biochemical industries, especially in drug discovery, providing researchers with unique early access to data, experimental results, and research insights. With the advancement of machine learning, patent analysis has evolved from manual labor to tasks assisted by automatic tools. However, there still lacks an unified agent that assists every aspect of patent analysis, from patent reading to core chemical identification. Leveraging the capabilities of Large Language Models (LLMs) to understand requests and follow instructions, we introduce the $\textbf{first}$ intelligent agent in this domain, $\texttt{PatentAgent}$, poised to advance and potentially revolutionize the landscape of pharmaceutical research. $\texttt{PatentAgent}$ comprises three key end-to-end modules -- $\textit{PA-QA}$, $\textit{PA-Img2Mol}$, and $\textit{PA-CoreId}$ -- that respectively perform (1) patent question-answering, (2) image-to-molecular-structure conversion, and (3) core chemical structure identification, addressing the essential needs of scientists and practitioners in pharmaceutical patent analysis. Each module of $\texttt{PatentAgent}$ demonstrates significant effectiveness with the updated algorithm and the synergistic design of $\texttt{PatentAgent}$ framework. $\textit{PA-Img2Mol}$ outperforms existing methods across CLEF, JPO, UOB, and USPTO patent benchmarks with an accuracy gain between 2.46% and 8.37% while $\textit{PA-CoreId}$ realizes accuracy improvement ranging from 7.15% to 7.62% on PatentNetML benchmark. Our code and dataset will be publicly available.
Easy-to-Hard Generalization: Scalable Alignment Beyond Human Supervision
Mar 14, 2024


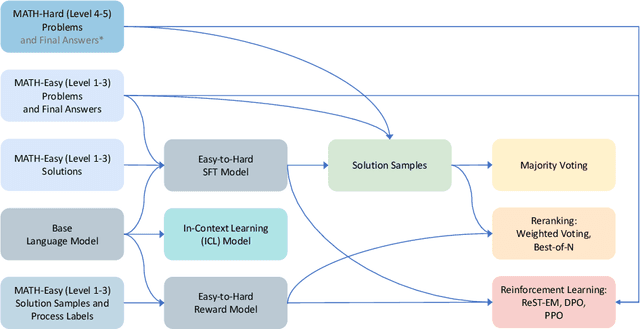
Current AI alignment methodologies rely on human-provided demonstrations or judgments, and the learned capabilities of AI systems would be upper-bounded by human capabilities as a result. This raises a challenging research question: How can we keep improving the systems when their capabilities have surpassed the levels of humans? This paper answers this question in the context of tackling hard reasoning tasks (e.g., level 4-5 MATH problems) via learning from human annotations on easier tasks (e.g., level 1-3 MATH problems), which we term as \textit{easy-to-hard generalization}. Our key insight is that an evaluator (reward model) trained on supervisions for easier tasks can be effectively used for scoring candidate solutions of harder tasks and hence facilitating easy-to-hard generalization over different levels of tasks. Based on this insight, we propose a novel approach to scalable alignment, which firstly trains the process-supervised reward models on easy problems (e.g., level 1-3), and then uses them to evaluate the performance of policy models on hard problems. We show that such \textit{easy-to-hard generalization from evaluators} can enable \textit{easy-to-hard generalizations in generators} either through re-ranking or reinforcement learning (RL). Notably, our process-supervised 7b RL model achieves an accuracy of 34.0\% on MATH500, despite only using human supervision on easy problems. Our approach suggests a promising path toward AI systems that advance beyond the frontier of human supervision.
Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization
Nov 10, 2023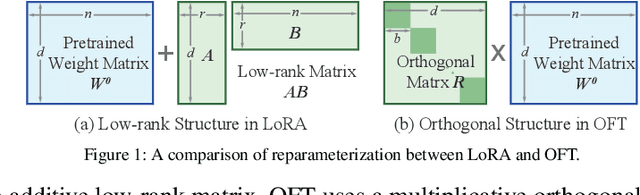
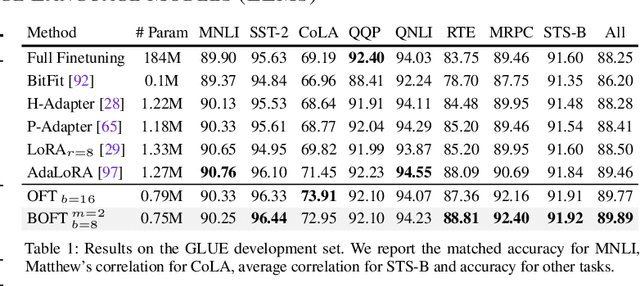
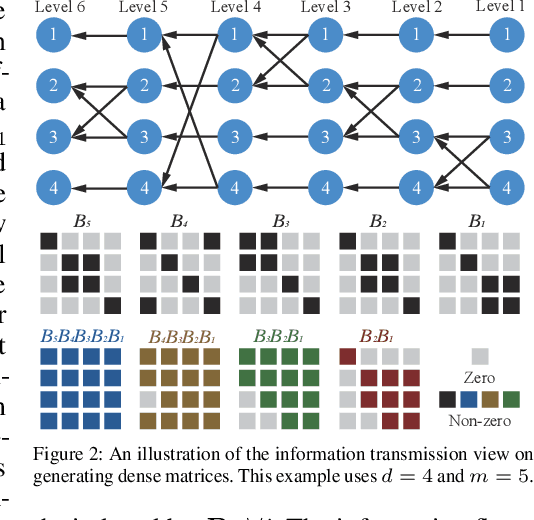
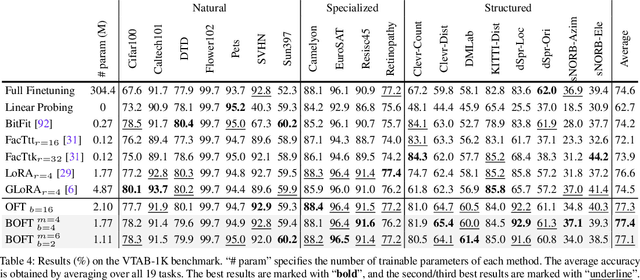
Large foundation models are becoming ubiquitous, but training them from scratch is prohibitively expensive. Thus, efficiently adapting these powerful models to downstream tasks is increasingly important. In this paper, we study a principled finetuning paradigm -- Orthogonal Finetuning (OFT) -- for downstream task adaptation. Despite demonstrating good generalizability, OFT still uses a fairly large number of trainable parameters due to the high dimensionality of orthogonal matrices. To address this, we start by examining OFT from an information transmission perspective, and then identify a few key desiderata that enable better parameter-efficiency. Inspired by how the Cooley-Tukey fast Fourier transform algorithm enables efficient information transmission, we propose an efficient orthogonal parameterization using butterfly structures. We apply this parameterization to OFT, creating a novel parameter-efficient finetuning method, called Orthogonal Butterfly (BOFT). By subsuming OFT as a special case, BOFT introduces a generalized orthogonal finetuning framework. Finally, we conduct an extensive empirical study of adapting large vision transformers, large language models, and text-to-image diffusion models to various downstream tasks in vision and language.
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Sep 22, 2023Large language models (LLMs) have pushed the limits of natural language understanding and exhibited excellent problem-solving ability. Despite the great success, most existing open-source LLMs (e.g., LLaMA-2) are still far away from satisfactory for solving mathematical problem due to the complex reasoning procedures. To bridge this gap, we propose MetaMath, a fine-tuned language model that specializes in mathematical reasoning. Specifically, we start by bootstrapping mathematical questions by rewriting the question from multiple perspectives without extra knowledge, which results in a new dataset called MetaMathQA. Then we fine-tune the LLaMA-2 models on MetaMathQA. Experimental results on two popular benchmarks (i.e., GSM8K and MATH) for mathematical reasoning demonstrate that MetaMath outperforms a suite of open-source LLMs by a significant margin. Our MetaMath-7B model achieves 66.4% on GSM8K and 19.4% on MATH, exceeding the state-of-the-art models of the same size by 11.5% and 8.7%. Particularly, MetaMath-70B achieves an accuracy of 82.3% on GSM8K, slightly better than GPT-3.5-Turbo. We release the MetaMathQA dataset, the MetaMath models with different model sizes and the training code for public use.
Forward-Backward Reasoning in Large Language Models for Verification
Aug 23, 2023Chain-of-Though (CoT) prompting has shown promising performance in various reasoning tasks. Recently, Self-Consistency \citep{wang2023selfconsistency} proposes to sample a diverse set of reasoning chains which may lead to different answers while the answer that receives the most votes is selected. In this paper, we propose a novel method to use backward reasoning in verifying candidate answers. We mask a token in the question by ${\bf x}$ and ask the LLM to predict the masked token when a candidate answer is provided by \textit{a simple template}, i.e., "\textit{\textbf{If we know the answer of the above question is \{a candidate answer\}, what is the value of unknown variable ${\bf x}$?}}" Intuitively, the LLM is expected to predict the masked token successfully if the provided candidate answer is correct. We further propose FOBAR to combine forward and backward reasoning for estimating the probability of candidate answers. We conduct extensive experiments on six data sets and three LLMs. Experimental results demonstrate that FOBAR achieves state-of-the-art performance on various reasoning benchmarks.