 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTT3R: 3D Reconstruction as Test-Time Training
Sep 30, 2025Modern Recurrent Neural Networks have become a competitive architecture for 3D reconstruction due to their linear-time complexity. However, their performance degrades significantly when applied beyond the training context length, revealing limited length generalization. In this work, we revisit the 3D reconstruction foundation models from a Test-Time Training perspective, framing their designs as an online learning problem. Building on this perspective, we leverage the alignment confidence between the memory state and incoming observations to derive a closed-form learning rate for memory updates, to balance between retaining historical information and adapting to new observations. This training-free intervention, termed TTT3R, substantially improves length generalization, achieving a $2\times$ improvement in global pose estimation over baselines, while operating at 20 FPS with just 6 GB of GPU memory to process thousands of images. Code available in https://rover-xingyu.github.io/TTT3R
SOAP: Style-Omniscient Animatable Portraits
May 08, 2025
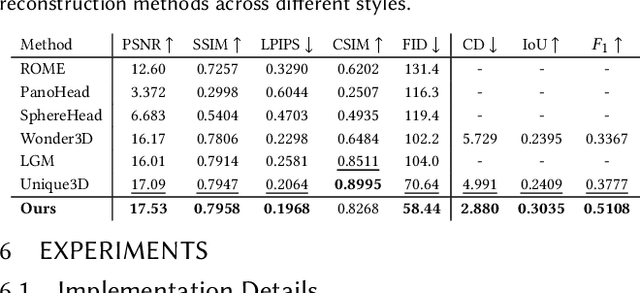
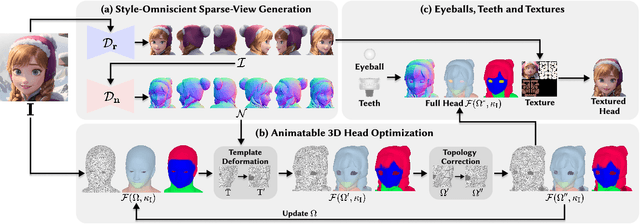
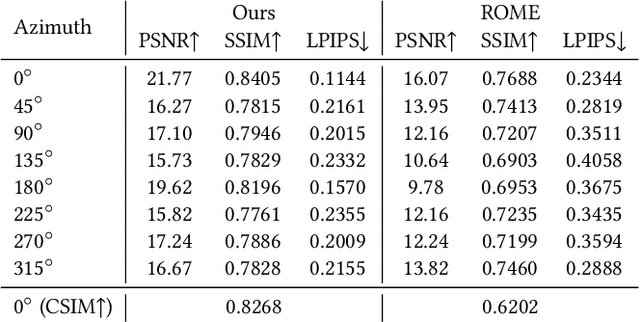
Creating animatable 3D avatars from a single image remains challenging due to style limitations (realistic, cartoon, anime) and difficulties in handling accessories or hairstyles. While 3D diffusion models advance single-view reconstruction for general objects, outputs often lack animation controls or suffer from artifacts because of the domain gap. We propose SOAP, a style-omniscient framework to generate rigged, topology-consistent avatars from any portrait. Our method leverages a multiview diffusion model trained on 24K 3D heads with multiple styles and an adaptive optimization pipeline to deform the FLAME mesh while maintaining topology and rigging via differentiable rendering. The resulting textured avatars support FACS-based animation, integrate with eyeballs and teeth, and preserve details like braided hair or accessories. Extensive experiments demonstrate the superiority of our method over state-of-the-art techniques for both single-view head modeling and diffusion-based generation of Image-to-3D. Our code and data are publicly available for research purposes at https://github.com/TingtingLiao/soap.
Easi3R: Estimating Disentangled Motion from DUSt3R Without Training
Mar 31, 2025



Recent advances in DUSt3R have enabled robust estimation of dense point clouds and camera parameters of static scenes, leveraging Transformer network architectures and direct supervision on large-scale 3D datasets. In contrast, the limited scale and diversity of available 4D datasets present a major bottleneck for training a highly generalizable 4D model. This constraint has driven conventional 4D methods to fine-tune 3D models on scalable dynamic video data with additional geometric priors such as optical flow and depths. In this work, we take an opposite path and introduce Easi3R, a simple yet efficient training-free method for 4D reconstruction. Our approach applies attention adaptation during inference, eliminating the need for from-scratch pre-training or network fine-tuning. We find that the attention layers in DUSt3R inherently encode rich information about camera and object motion. By carefully disentangling these attention maps, we achieve accurate dynamic region segmentation, camera pose estimation, and 4D dense point map reconstruction. Extensive experiments on real-world dynamic videos demonstrate that our lightweight attention adaptation significantly outperforms previous state-of-the-art methods that are trained or finetuned on extensive dynamic datasets. Our code is publicly available for research purpose at https://easi3r.github.io/
ETCH: Generalizing Body Fitting to Clothed Humans via Equivariant Tightness
Mar 13, 2025Fitting a body to a 3D clothed human point cloud is a common yet challenging task. Traditional optimization-based approaches use multi-stage pipelines that are sensitive to pose initialization, while recent learning-based methods often struggle with generalization across diverse poses and garment types. We propose Equivariant Tightness Fitting for Clothed Humans, or ETCH, a novel pipeline that estimates cloth-to-body surface mapping through locally approximate SE(3) equivariance, encoding tightness as displacement vectors from the cloth surface to the underlying body. Following this mapping, pose-invariant body features regress sparse body markers, simplifying clothed human fitting into an inner-body marker fitting task. Extensive experiments on CAPE and 4D-Dress show that ETCH significantly outperforms state-of-the-art methods -- both tightness-agnostic and tightness-aware -- in body fitting accuracy on loose clothing (16.7% ~ 69.5%) and shape accuracy (average 49.9%). Our equivariant tightness design can even reduce directional errors by (67.2% ~ 89.8%) in one-shot (or out-of-distribution) settings. Qualitative results demonstrate strong generalization of ETCH, regardless of challenging poses, unseen shapes, loose clothing, and non-rigid dynamics. We will release the code and models soon for research purposes at https://boqian-li.github.io/ETCH/.
ChatGarment: Garment Estimation, Generation and Editing via Large Language Models
Dec 23, 2024We introduce ChatGarment, a novel approach that leverages large vision-language models (VLMs) to automate the estimation, generation, and editing of 3D garments from images or text descriptions. Unlike previous methods that struggle in real-world scenarios or lack interactive editing capabilities, ChatGarment can estimate sewing patterns from in-the-wild images or sketches, generate them from text descriptions, and edit garments based on user instructions, all within an interactive dialogue. These sewing patterns can then be draped into 3D garments, which are easily animatable and simulatable. This is achieved by finetuning a VLM to directly generate a JSON file that includes both textual descriptions of garment types and styles, as well as continuous numerical attributes. This JSON file is then used to create sewing patterns through a programming parametric model. To support this, we refine the existing programming model, GarmentCode, by expanding its garment type coverage and simplifying its structure for efficient VLM fine-tuning. Additionally, we construct a large-scale dataset of image-to-sewing-pattern and text-to-sewing-pattern pairs through an automated data pipeline. Extensive evaluations demonstrate ChatGarment's ability to accurately reconstruct, generate, and edit garments from multimodal inputs, highlighting its potential to revolutionize workflows in fashion and gaming applications. Code and data will be available at https://chatgarment.github.io/.
Feat2GS: Probing Visual Foundation Models with Gaussian Splatting
Dec 12, 2024Given that visual foundation models (VFMs) are trained on extensive datasets but often limited to 2D images, a natural question arises: how well do they understand the 3D world? With the differences in architecture and training protocols (i.e., objectives, proxy tasks), a unified framework to fairly and comprehensively probe their 3D awareness is urgently needed. Existing works on 3D probing suggest single-view 2.5D estimation (e.g., depth and normal) or two-view sparse 2D correspondence (e.g., matching and tracking). Unfortunately, these tasks ignore texture awareness, and require 3D data as ground-truth, which limits the scale and diversity of their evaluation set. To address these issues, we introduce Feat2GS, which readout 3D Gaussians attributes from VFM features extracted from unposed images. This allows us to probe 3D awareness for geometry and texture via novel view synthesis, without requiring 3D data. Additionally, the disentanglement of 3DGS parameters - geometry ($\boldsymbol{x}, \alpha, \Sigma$) and texture ($\boldsymbol{c}$) - enables separate analysis of texture and geometry awareness. Under Feat2GS, we conduct extensive experiments to probe the 3D awareness of several VFMs, and investigate the ingredients that lead to a 3D aware VFM. Building on these findings, we develop several variants that achieve state-of-the-art across diverse datasets. This makes Feat2GS useful for probing VFMs, and as a simple-yet-effective baseline for novel-view synthesis. Code and data will be made available at https://fanegg.github.io/Feat2GS/.
Differentiable Voxelization and Mesh Morphing
Jul 15, 2024
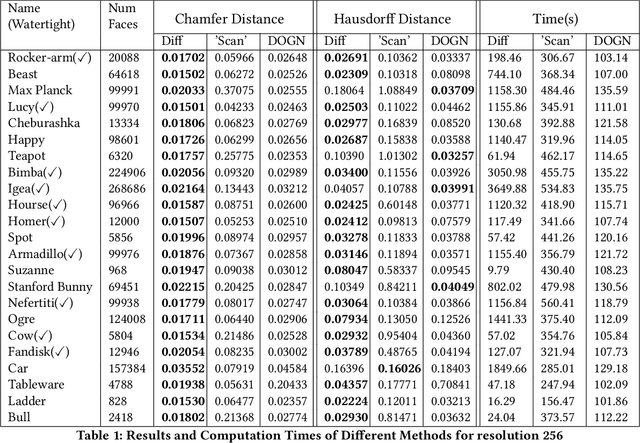
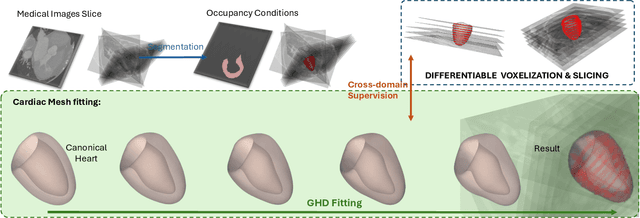

In this paper, we propose the differentiable voxelization of 3D meshes via the winding number and solid angles. The proposed approach achieves fast, flexible, and accurate voxelization of 3D meshes, admitting the computation of gradients with respect to the input mesh and GPU acceleration. We further demonstrate the application of the proposed voxelization in mesh morphing, where the voxelized mesh is deformed by a neural network. The proposed method is evaluated on the ShapeNet dataset and achieves state-of-the-art performance in terms of both accuracy and efficiency.
StableNormal: Reducing Diffusion Variance for Stable and Sharp Normal
Jun 24, 2024


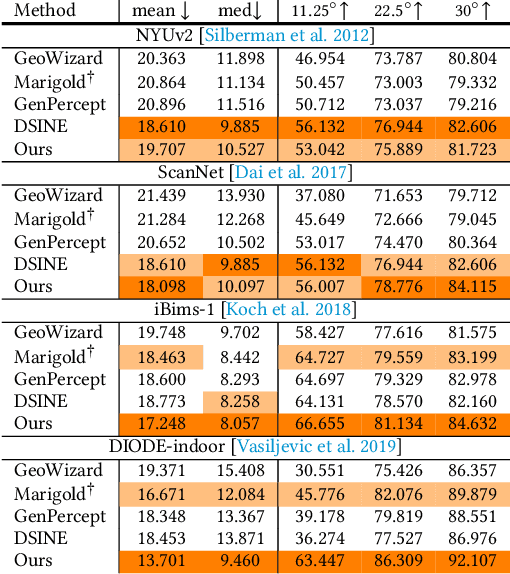
This work addresses the challenge of high-quality surface normal estimation from monocular colored inputs (i.e., images and videos), a field which has recently been revolutionized by repurposing diffusion priors. However, previous attempts still struggle with stochastic inference, conflicting with the deterministic nature of the Image2Normal task, and costly ensembling step, which slows down the estimation process. Our method, StableNormal, mitigates the stochasticity of the diffusion process by reducing inference variance, thus producing "Stable-and-Sharp" normal estimates without any additional ensembling process. StableNormal works robustly under challenging imaging conditions, such as extreme lighting, blurring, and low quality. It is also robust against transparent and reflective surfaces, as well as cluttered scenes with numerous objects. Specifically, StableNormal employs a coarse-to-fine strategy, which starts with a one-step normal estimator (YOSO) to derive an initial normal guess, that is relatively coarse but reliable, then followed by a semantic-guided refinement process (SG-DRN) that refines the normals to recover geometric details. The effectiveness of StableNormal is demonstrated through competitive performance in standard datasets such as DIODE-indoor, iBims, ScannetV2 and NYUv2, and also in various downstream tasks, such as surface reconstruction and normal enhancement. These results evidence that StableNormal retains both the "stability" and "sharpness" for accurate normal estimation. StableNormal represents a baby attempt to repurpose diffusion priors for deterministic estimation. To democratize this, code and models have been publicly available in hf.co/Stable-X
PuzzleAvatar: Assembling 3D Avatars from Personal Albums
May 23, 2024



Generating personalized 3D avatars is crucial for AR/VR. However, recent text-to-3D methods that generate avatars for celebrities or fictional characters, struggle with everyday people. Methods for faithful reconstruction typically require full-body images in controlled settings. What if a user could just upload their personal "OOTD" (Outfit Of The Day) photo collection and get a faithful avatar in return? The challenge is that such casual photo collections contain diverse poses, challenging viewpoints, cropped views, and occlusion (albeit with a consistent outfit, accessories and hairstyle). We address this novel "Album2Human" task by developing PuzzleAvatar, a novel model that generates a faithful 3D avatar (in a canonical pose) from a personal OOTD album, while bypassing the challenging estimation of body and camera pose. To this end, we fine-tune a foundational vision-language model (VLM) on such photos, encoding the appearance, identity, garments, hairstyles, and accessories of a person into (separate) learned tokens and instilling these cues into the VLM. In effect, we exploit the learned tokens as "puzzle pieces" from which we assemble a faithful, personalized 3D avatar. Importantly, we can customize avatars by simply inter-changing tokens. As a benchmark for this new task, we collect a new dataset, called PuzzleIOI, with 41 subjects in a total of nearly 1K OOTD configurations, in challenging partial photos with paired ground-truth 3D bodies. Evaluation shows that PuzzleAvatar not only has high reconstruction accuracy, outperforming TeCH and MVDreamBooth, but also a unique scalability to album photos, and strong robustness. Our model and data will be public.
Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization
Nov 10, 2023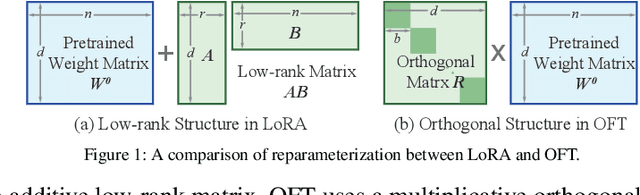
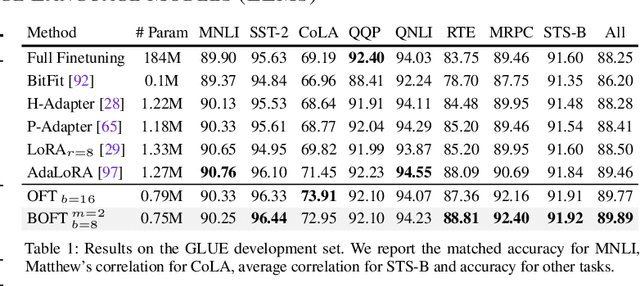
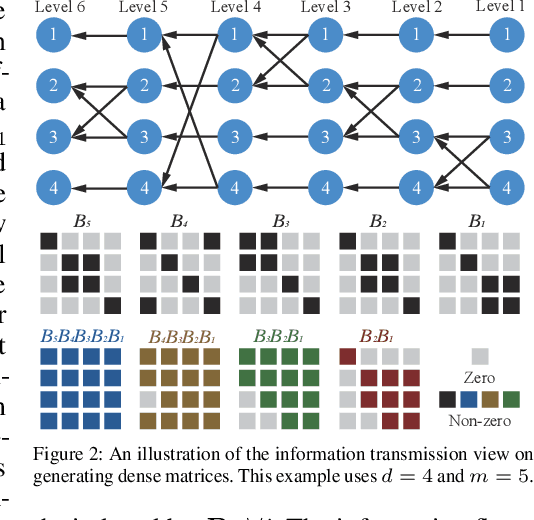
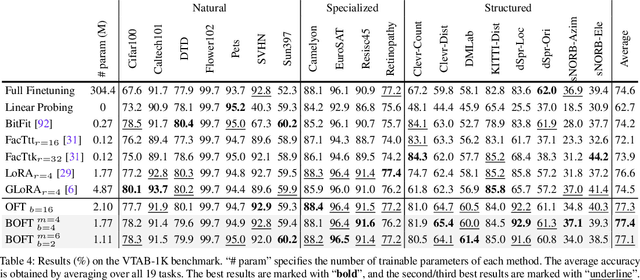
Large foundation models are becoming ubiquitous, but training them from scratch is prohibitively expensive. Thus, efficiently adapting these powerful models to downstream tasks is increasingly important. In this paper, we study a principled finetuning paradigm -- Orthogonal Finetuning (OFT) -- for downstream task adaptation. Despite demonstrating good generalizability, OFT still uses a fairly large number of trainable parameters due to the high dimensionality of orthogonal matrices. To address this, we start by examining OFT from an information transmission perspective, and then identify a few key desiderata that enable better parameter-efficiency. Inspired by how the Cooley-Tukey fast Fourier transform algorithm enables efficient information transmission, we propose an efficient orthogonal parameterization using butterfly structures. We apply this parameterization to OFT, creating a novel parameter-efficient finetuning method, called Orthogonal Butterfly (BOFT). By subsuming OFT as a special case, BOFT introduces a generalized orthogonal finetuning framework. Finally, we conduct an extensive empirical study of adapting large vision transformers, large language models, and text-to-image diffusion models to various downstream tasks in vision and language.