 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Video Diffusion Transformers with Massive Activations
Mar 18, 2026Despite rapid progress in video diffusion transformers, how their internal model signals can be leveraged with minimal overhead to enhance video generation quality remains underexplored. In this work, we study the role of Massive Activations (MAs), which are rare, high-magnitude hidden state spikes in video diffusion transformers. We observed that MAs emerge consistently across all visual tokens, with a clear magnitude hierarchy: first-frame tokens exhibit the largest MA magnitudes, latent-frame boundary tokens (the head and tail portions of each temporal chunk in the latent space) show elevated but slightly lower MA magnitudes than the first frame, and interior tokens within each latent frame remain elevated, yet are comparatively moderate in magnitude. This structured pattern suggests that the model implicitly prioritizes token positions aligned with the temporal chunking in the latent space. Based on this observation, we propose Structured Activation Steering (STAS), a training-free self-guidance-like method that steers MA values at first-frame and boundary tokens toward a scaled global maximum reference magnitude. STAS achieves consistent improvements in terms of video quality and temporal coherence across different text-to-video models, while introducing negligible computational overhead.
Character Mixing for Video Generation
Oct 06, 2025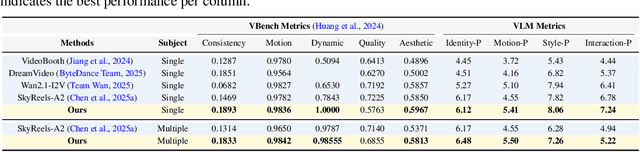


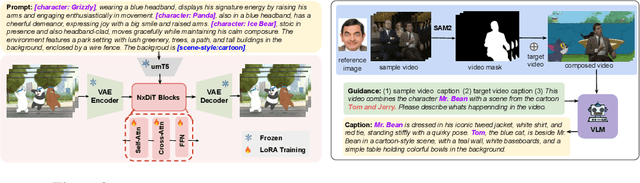
Imagine Mr. Bean stepping into Tom and Jerry--can we generate videos where characters interact naturally across different worlds? We study inter-character interaction in text-to-video generation, where the key challenge is to preserve each character's identity and behaviors while enabling coherent cross-context interaction. This is difficult because characters may never have coexisted and because mixing styles often causes style delusion, where realistic characters appear cartoonish or vice versa. We introduce a framework that tackles these issues with Cross-Character Embedding (CCE), which learns identity and behavioral logic across multimodal sources, and Cross-Character Augmentation (CCA), which enriches training with synthetic co-existence and mixed-style data. Together, these techniques allow natural interactions between previously uncoexistent characters without losing stylistic fidelity. Experiments on a curated benchmark of cartoons and live-action series with 10 characters show clear improvements in identity preservation, interaction quality, and robustness to style delusion, enabling new forms of generative storytelling.Additional results and videos are available on our project page: https://tingtingliao.github.io/mimix/.
SOAP: Style-Omniscient Animatable Portraits
May 08, 2025
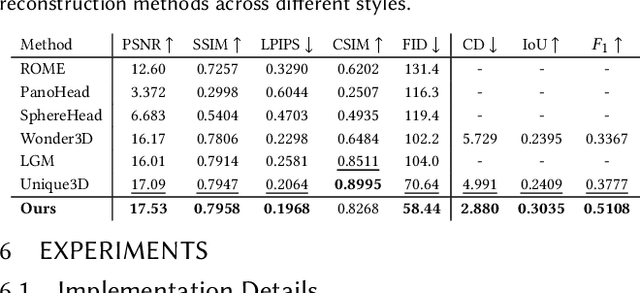
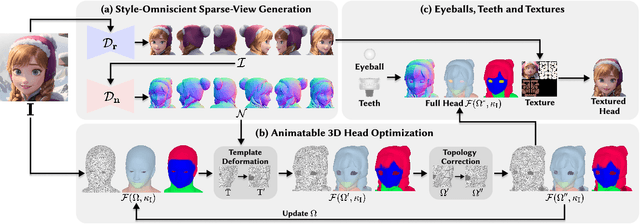
Creating animatable 3D avatars from a single image remains challenging due to style limitations (realistic, cartoon, anime) and difficulties in handling accessories or hairstyles. While 3D diffusion models advance single-view reconstruction for general objects, outputs often lack animation controls or suffer from artifacts because of the domain gap. We propose SOAP, a style-omniscient framework to generate rigged, topology-consistent avatars from any portrait. Our method leverages a multiview diffusion model trained on 24K 3D heads with multiple styles and an adaptive optimization pipeline to deform the FLAME mesh while maintaining topology and rigging via differentiable rendering. The resulting textured avatars support FACS-based animation, integrate with eyeballs and teeth, and preserve details like braided hair or accessories. Extensive experiments demonstrate the superiority of our method over state-of-the-art techniques for both single-view head modeling and diffusion-based generation of Image-to-3D. Our code and data are publicly available for research purposes at https://github.com/TingtingLiao/soap.
TADA! Text to Animatable Digital Avatars
Aug 21, 2023

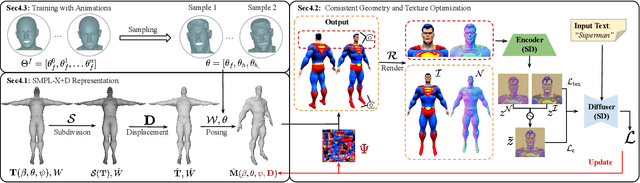

We introduce TADA, a simple-yet-effective approach that takes textual descriptions and produces expressive 3D avatars with high-quality geometry and lifelike textures, that can be animated and rendered with traditional graphics pipelines. Existing text-based character generation methods are limited in terms of geometry and texture quality, and cannot be realistically animated due to inconsistent alignment between the geometry and the texture, particularly in the face region. To overcome these limitations, TADA leverages the synergy of a 2D diffusion model and an animatable parametric body model. Specifically, we derive an optimizable high-resolution body model from SMPL-X with 3D displacements and a texture map, and use hierarchical rendering with score distillation sampling (SDS) to create high-quality, detailed, holistic 3D avatars from text. To ensure alignment between the geometry and texture, we render normals and RGB images of the generated character and exploit their latent embeddings in the SDS training process. We further introduce various expression parameters to deform the generated character during training, ensuring that the semantics of our generated character remain consistent with the original SMPL-X model, resulting in an animatable character. Comprehensive evaluations demonstrate that TADA significantly surpasses existing approaches on both qualitative and quantitative measures. TADA enables creation of large-scale digital character assets that are ready for animation and rendering, while also being easily editable through natural language. The code will be public for research purposes.
TeCH: Text-guided Reconstruction of Lifelike Clothed Humans
Aug 19, 2023



Despite recent research advancements in reconstructing clothed humans from a single image, accurately restoring the "unseen regions" with high-level details remains an unsolved challenge that lacks attention. Existing methods often generate overly smooth back-side surfaces with a blurry texture. But how to effectively capture all visual attributes of an individual from a single image, which are sufficient to reconstruct unseen areas (e.g., the back view)? Motivated by the power of foundation models, TeCH reconstructs the 3D human by leveraging 1) descriptive text prompts (e.g., garments, colors, hairstyles) which are automatically generated via a garment parsing model and Visual Question Answering (VQA), 2) a personalized fine-tuned Text-to-Image diffusion model (T2I) which learns the "indescribable" appearance. To represent high-resolution 3D clothed humans at an affordable cost, we propose a hybrid 3D representation based on DMTet, which consists of an explicit body shape grid and an implicit distance field. Guided by the descriptive prompts + personalized T2I diffusion model, the geometry and texture of the 3D humans are optimized through multi-view Score Distillation Sampling (SDS) and reconstruction losses based on the original observation. TeCH produces high-fidelity 3D clothed humans with consistent & delicate texture, and detailed full-body geometry. Quantitative and qualitative experiments demonstrate that TeCH outperforms the state-of-the-art methods in terms of reconstruction accuracy and rendering quality. The code will be publicly available for research purposes at https://huangyangyi.github.io/TeCH
High-Fidelity Clothed Avatar Reconstruction from a Single Image
Apr 08, 2023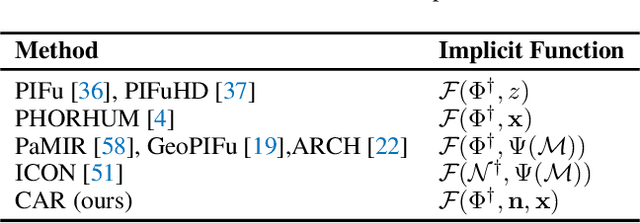
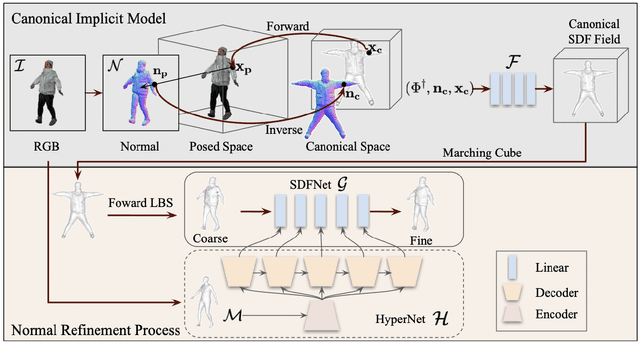


This paper presents a framework for efficient 3D clothed avatar reconstruction. By combining the advantages of the high accuracy of optimization-based methods and the efficiency of learning-based methods, we propose a coarse-to-fine way to realize a high-fidelity clothed avatar reconstruction (CAR) from a single image. At the first stage, we use an implicit model to learn the general shape in the canonical space of a person in a learning-based way, and at the second stage, we refine the surface detail by estimating the non-rigid deformation in the posed space in an optimization way. A hyper-network is utilized to generate a good initialization so that the convergence o f the optimization process is greatly accelerated. Extensive experiments on various datasets show that the proposed CAR successfully produces high-fidelity avatars for arbitrarily clothed humans in real scenes.
MVP-Human Dataset for 3D Human Avatar Reconstruction from Unconstrained Frames
Apr 24, 2022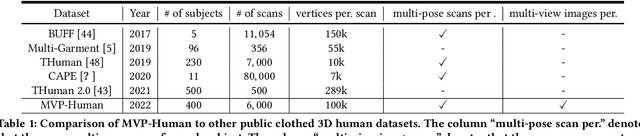
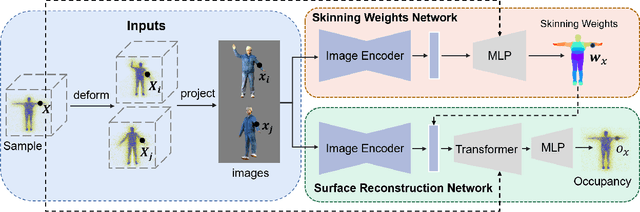
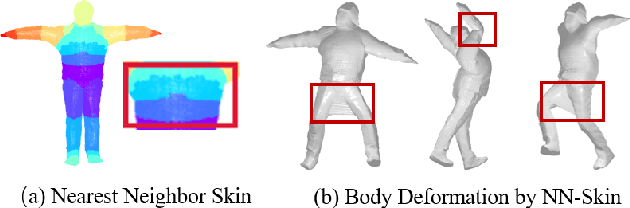
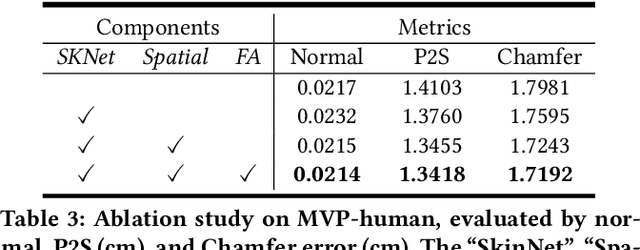
In this paper, we consider a novel problem of reconstructing a 3D human avatar from multiple unconstrained frames, independent of assumptions on camera calibration, capture space, and constrained actions. The problem should be addressed by a framework that takes multiple unconstrained images as inputs, and generates a shape-with-skinning avatar in the canonical space, finished in one feed-forward pass. To this end, we present 3D Avatar Reconstruction in the wild (ARwild), which first reconstructs the implicit skinning fields in a multi-level manner, by which the image features from multiple images are aligned and integrated to estimate a pixel-aligned implicit function that represents the clothed shape. To enable the training and testing of the new framework, we contribute a large-scale dataset, MVP-Human (Multi-View and multi-Pose 3D Human), which contains 400 subjects, each of which has 15 scans in different poses and 8-view images for each pose, providing 6,000 3D scans and 48,000 images in total. Overall, benefits from the specific network architecture and the diverse data, the trained model enables 3D avatar reconstruction from unconstrained frames and achieves state-of-the-art performance.