 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Move: Motion-controllable Video Generation via Latent Trajectory Guidance
Dec 09, 2025We present Wan-Move, a simple and scalable framework that brings motion control to video generative models. Existing motion-controllable methods typically suffer from coarse control granularity and limited scalability, leaving their outputs insufficient for practical use. We narrow this gap by achieving precise and high-quality motion control. Our core idea is to directly make the original condition features motion-aware for guiding video synthesis. To this end, we first represent object motions with dense point trajectories, allowing fine-grained control over the scene. We then project these trajectories into latent space and propagate the first frame's features along each trajectory, producing an aligned spatiotemporal feature map that tells how each scene element should move. This feature map serves as the updated latent condition, which is naturally integrated into the off-the-shelf image-to-video model, e.g., Wan-I2V-14B, as motion guidance without any architecture change. It removes the need for auxiliary motion encoders and makes fine-tuning base models easily scalable. Through scaled training, Wan-Move generates 5-second, 480p videos whose motion controllability rivals Kling 1.5 Pro's commercial Motion Brush, as indicated by user studies. To support comprehensive evaluation, we further design MoveBench, a rigorously curated benchmark featuring diverse content categories and hybrid-verified annotations. It is distinguished by larger data volume, longer video durations, and high-quality motion annotations. Extensive experiments on MoveBench and the public dataset consistently show Wan-Move's superior motion quality. Code, models, and benchmark data are made publicly available.
SignX: The Foundation Model for Sign Recognition
Apr 22, 2025The complexity of sign language data processing brings many challenges. The current approach to recognition of ASL signs aims to translate RGB sign language videos through pose information into English-based ID glosses, which serve to uniquely identify ASL signs. Note that there is no shared convention for assigning such glosses to ASL signs, so it is essential that the same glossing conventions are used for all of the data in the datasets that are employed. This paper proposes SignX, a foundation model framework for sign recognition. It is a concise yet powerful framework applicable to multiple human activity recognition scenarios. First, we developed a Pose2Gloss component based on an inverse diffusion model, which contains a multi-track pose fusion layer that unifies five of the most powerful pose information sources--SMPLer-X, DWPose, Mediapipe, PrimeDepth, and Sapiens Segmentation--into a single latent pose representation. Second, we trained a Video2Pose module based on ViT that can directly convert raw video into signer pose representation. Through this 2-stage training framework, we enable sign language recognition models to be compatible with existing pose formats, laying the foundation for the common pose estimation necessary for sign recognition. Experimental results show that SignX can recognize signs from sign language video, producing predicted gloss representations with greater accuracy than has been reported in prior work.
MagicDistillation: Weak-to-Strong Video Distillation for Large-Scale Portrait Few-Step Synthesis
Mar 17, 2025



Fine-tuning open-source large-scale VDMs for the portrait video synthesis task can result in significant improvements across multiple dimensions, such as visual quality and natural facial motion dynamics. Despite their advancements, how to achieve step distillation and reduce the substantial computational overhead of large-scale VDMs remains unexplored. To fill this gap, this paper proposes Weak-to-Strong Video Distillation (W2SVD) to mitigate both the issue of insufficient training memory and the problem of training collapse observed in vanilla DMD during the training process. Specifically, we first leverage LoRA to fine-tune the fake diffusion transformer (DiT) to address the out-of-memory issue. Then, we employ the W2S distribution matching to adjust the real DiT's parameter, subtly shifting it toward the fake DiT's parameter. This adjustment is achieved by utilizing the weak weight of the low-rank branch, effectively alleviate the conundrum where the video synthesized by the few-step generator deviates from the real data distribution, leading to inaccuracies in the KL divergence approximation. Additionally, we minimize the distance between the fake data distribution and the ground truth distribution to further enhance the visual quality of the synthesized videos. As experimentally demonstrated on HunyuanVideo, W2SVD surpasses the standard Euler, LCM, DMD and even the 28-step standard sampling in FID/FVD and VBench in 1/4-step video synthesis. The project page is in https://w2svd.github.io/W2SVD/.
MagicID: Hybrid Preference Optimization for ID-Consistent and Dynamic-Preserved Video Customization
Mar 16, 2025
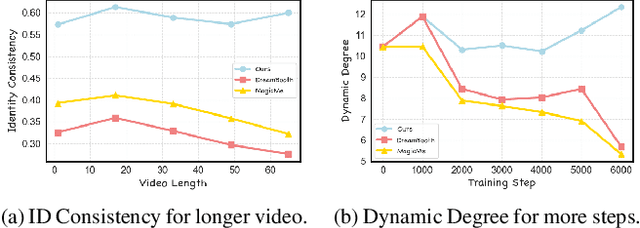

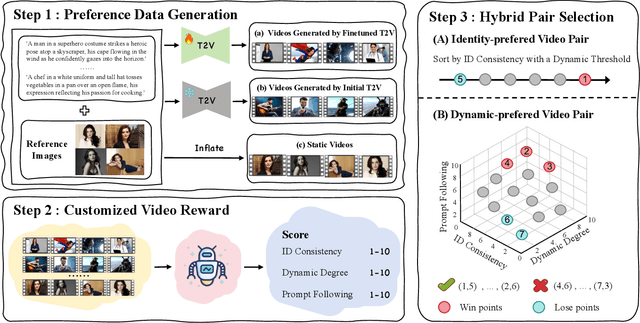
Video identity customization seeks to produce high-fidelity videos that maintain consistent identity and exhibit significant dynamics based on users' reference images. However, existing approaches face two key challenges: identity degradation over extended video length and reduced dynamics during training, primarily due to their reliance on traditional self-reconstruction training with static images. To address these issues, we introduce $\textbf{MagicID}$, a novel framework designed to directly promote the generation of identity-consistent and dynamically rich videos tailored to user preferences. Specifically, we propose constructing pairwise preference video data with explicit identity and dynamic rewards for preference learning, instead of sticking to the traditional self-reconstruction. To address the constraints of customized preference data, we introduce a hybrid sampling strategy. This approach first prioritizes identity preservation by leveraging static videos derived from reference images, then enhances dynamic motion quality in the generated videos using a Frontier-based sampling method. By utilizing these hybrid preference pairs, we optimize the model to align with the reward differences between pairs of customized preferences. Extensive experiments show that MagicID successfully achieves consistent identity and natural dynamics, surpassing existing methods across various metrics.
MagicInfinite: Generating Infinite Talking Videos with Your Words and Voice
Mar 07, 2025We present MagicInfinite, a novel diffusion Transformer (DiT) framework that overcomes traditional portrait animation limitations, delivering high-fidelity results across diverse character types-realistic humans, full-body figures, and stylized anime characters. It supports varied facial poses, including back-facing views, and animates single or multiple characters with input masks for precise speaker designation in multi-character scenes. Our approach tackles key challenges with three innovations: (1) 3D full-attention mechanisms with a sliding window denoising strategy, enabling infinite video generation with temporal coherence and visual quality across diverse character styles; (2) a two-stage curriculum learning scheme, integrating audio for lip sync, text for expressive dynamics, and reference images for identity preservation, enabling flexible multi-modal control over long sequences; and (3) region-specific masks with adaptive loss functions to balance global textual control and local audio guidance, supporting speaker-specific animations. Efficiency is enhanced via our innovative unified step and cfg distillation techniques, achieving a 20x inference speed boost over the basemodel: generating a 10 second 540x540p video in 10 seconds or 720x720p in 30 seconds on 8 H100 GPUs, without quality loss. Evaluations on our new benchmark demonstrate MagicInfinite's superiority in audio-lip synchronization, identity preservation, and motion naturalness across diverse scenarios. It is publicly available at https://www.hedra.com/, with examples at https://magicinfinite.github.io/.
Magic 1-For-1: Generating One Minute Video Clips within One Minute
Feb 11, 2025In this technical report, we present Magic 1-For-1 (Magic141), an efficient video generation model with optimized memory consumption and inference latency. The key idea is simple: factorize the text-to-video generation task into two separate easier tasks for diffusion step distillation, namely text-to-image generation and image-to-video generation. We verify that with the same optimization algorithm, the image-to-video task is indeed easier to converge over the text-to-video task. We also explore a bag of optimization tricks to reduce the computational cost of training the image-to-video (I2V) models from three aspects: 1) model convergence speedup by using a multi-modal prior condition injection; 2) inference latency speed up by applying an adversarial step distillation, and 3) inference memory cost optimization with parameter sparsification. With those techniques, we are able to generate 5-second video clips within 3 seconds. By applying a test time sliding window, we are able to generate a minute-long video within one minute with significantly improved visual quality and motion dynamics, spending less than 1 second for generating 1 second video clips on average. We conduct a series of preliminary explorations to find out the optimal tradeoff between computational cost and video quality during diffusion step distillation and hope this could be a good foundation model for open-source explorations. The code and the model weights are available at https://github.com/DA-Group-PKU/Magic-1-For-1.
Real-time One-Step Diffusion-based Expressive Portrait Videos Generation
Dec 18, 2024



Latent diffusion models have made great strides in generating expressive portrait videos with accurate lip-sync and natural motion from a single reference image and audio input. However, these models are far from real-time, often requiring many sampling steps that take minutes to generate even one second of video-significantly limiting practical use. We introduce OSA-LCM (One-Step Avatar Latent Consistency Model), paving the way for real-time diffusion-based avatars. Our method achieves comparable video quality to existing methods but requires only one sampling step, making it more than 10x faster. To accomplish this, we propose a novel avatar discriminator design that guides lip-audio consistency and motion expressiveness to enhance video quality in limited sampling steps. Additionally, we employ a second-stage training architecture using an editing fine-tuned method (EFT), transforming video generation into an editing task during training to effectively address the temporal gap challenge in single-step generation. Experiments demonstrate that OSA-LCM outperforms existing open-source portrait video generation models while operating more efficiently with a single sampling step.
Human-Aware 3D Scene Generation with Spatially-constrained Diffusion Models
Jun 26, 2024Generating 3D scenes from human motion sequences supports numerous applications, including virtual reality and architectural design. However, previous auto-regression-based human-aware 3D scene generation methods have struggled to accurately capture the joint distribution of multiple objects and input humans, often resulting in overlapping object generation in the same space. To address this limitation, we explore the potential of diffusion models that simultaneously consider all input humans and the floor plan to generate plausible 3D scenes. Our approach not only satisfies all input human interactions but also adheres to spatial constraints with the floor plan. Furthermore, we introduce two spatial collision guidance mechanisms: human-object collision avoidance and object-room boundary constraints. These mechanisms help avoid generating scenes that conflict with human motions while respecting layout constraints. To enhance the diversity and accuracy of human-guided scene generation, we have developed an automated pipeline that improves the variety and plausibility of human-object interactions in the existing 3D FRONT HUMAN dataset. Extensive experiments on both synthetic and real-world datasets demonstrate that our framework can generate more natural and plausible 3D scenes with precise human-scene interactions, while significantly reducing human-object collisions compared to previous state-of-the-art methods. Our code and data will be made publicly available upon publication of this work.
Generating Human Interaction Motions in Scenes with Text Control
Apr 16, 2024We present TeSMo, a method for text-controlled scene-aware motion generation based on denoising diffusion models. Previous text-to-motion methods focus on characters in isolation without considering scenes due to the limited availability of datasets that include motion, text descriptions, and interactive scenes. Our approach begins with pre-training a scene-agnostic text-to-motion diffusion model, emphasizing goal-reaching constraints on large-scale motion-capture datasets. We then enhance this model with a scene-aware component, fine-tuned using data augmented with detailed scene information, including ground plane and object shapes. To facilitate training, we embed annotated navigation and interaction motions within scenes. The proposed method produces realistic and diverse human-object interactions, such as navigation and sitting, in different scenes with various object shapes, orientations, initial body positions, and poses. Extensive experiments demonstrate that our approach surpasses prior techniques in terms of the plausibility of human-scene interactions, as well as the realism and variety of the generated motions. Code will be released upon publication of this work at https://research.nvidia.com/labs/toronto-ai/tesmo.
DECO: Dense Estimation of 3D Human-Scene Contact In The Wild
Sep 26, 2023
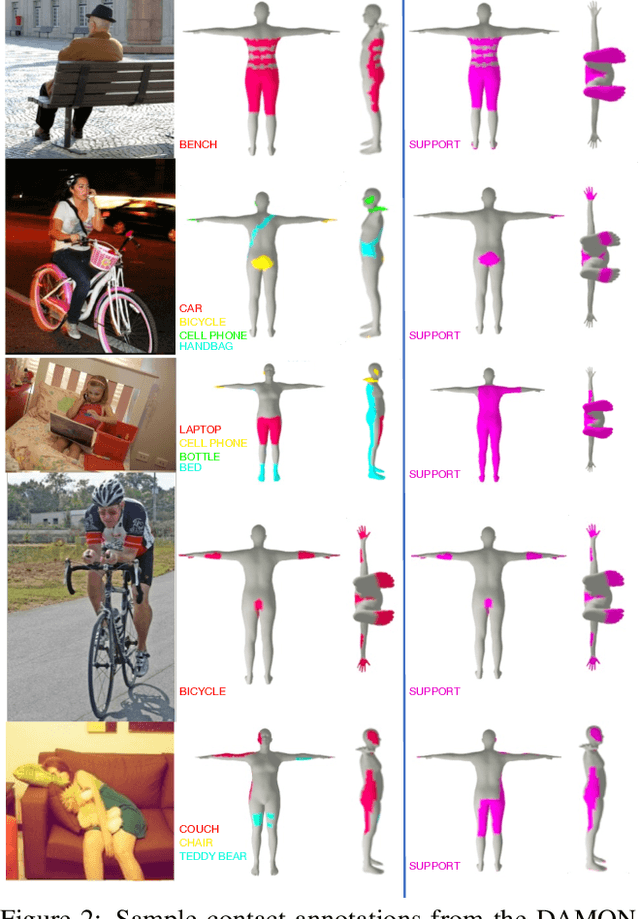
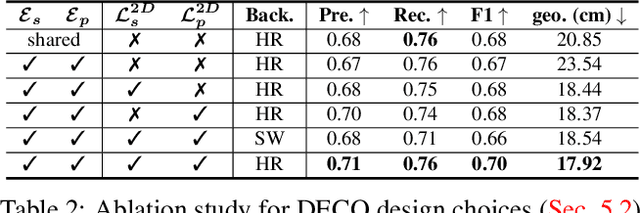
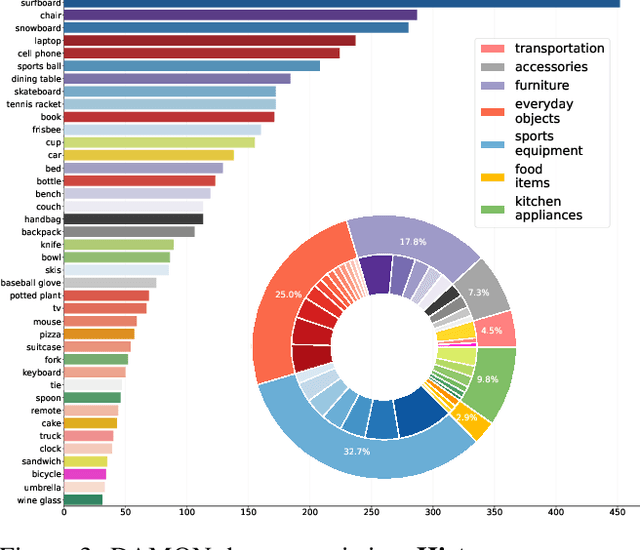
Understanding how humans use physical contact to interact with the world is key to enabling human-centric artificial intelligence. While inferring 3D contact is crucial for modeling realistic and physically-plausible human-object interactions, existing methods either focus on 2D, consider body joints rather than the surface, use coarse 3D body regions, or do not generalize to in-the-wild images. In contrast, we focus on inferring dense, 3D contact between the full body surface and objects in arbitrary images. To achieve this, we first collect DAMON, a new dataset containing dense vertex-level contact annotations paired with RGB images containing complex human-object and human-scene contact. Second, we train DECO, a novel 3D contact detector that uses both body-part-driven and scene-context-driven attention to estimate vertex-level contact on the SMPL body. DECO builds on the insight that human observers recognize contact by reasoning about the contacting body parts, their proximity to scene objects, and the surrounding scene context. We perform extensive evaluations of our detector on DAMON as well as on the RICH and BEHAVE datasets. We significantly outperform existing SOTA methods across all benchmarks. We also show qualitatively that DECO generalizes well to diverse and challenging real-world human interactions in natural images. The code, data, and models are available at https://deco.is.tue.mpg.de.