 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionBricks: Scalable Real-Time Motions with Modular Latent Generative Model and Smart Primitives
Apr 27, 2026Despite transformative advances in generative motion synthesis, real-time interactive motion control remains dominated by traditional techniques. In this work, we identify two key challenges in bridging research and production: 1) Real-time scalability: Industry applications demand real-time generation of a vast repertoire of motion skills, while generative methods exhibit significant degradation in quality and scalability under real-time computation constraints, and 2) Integration: Industry applications demand fine-grained multi-modal control involving velocity commands, style selection, and precise keyframes, a need largely unmet by existing text- or tag-driven models. To overcome these limitations, we introduce MotionBricks: a large-scale, real-time generative framework with a two-fold solution. First, we propose a large-scale modular latent generative backbone tailored for robust real-time motion generation, effectively modeling a dataset of over 350,000 motion clips with a single model. Second, we introduce smart primitives that provide a unified, robust, and intuitive interface for authoring both navigation and object interaction. Applications can be designed in a plug-and-play manner like assembling bricks without expert animation knowledge. Quantitatively, we show that MotionBricks produces state-of-the-art motion quality on open-source and proprietary datasets of various scales, while also achieving a real-time throughput of 15,000 FPS with 2ms latency. We demonstrate the flexibility and robustness of MotionBricks in a complete production-level animation demo, covering navigation and object-scene interaction across various styles with a unified model. To showcase our framework's application beyond animation, we deploy MotionBricks on the Unitree G1 humanoid robot to demonstrate its flexibility and generalization for real-time robotic control.
Kimodo: Scaling Controllable Human Motion Generation
Mar 16, 2026High-quality human motion data is becoming increasingly important for applications in robotics, simulation, and entertainment. Recent generative models offer a potential data source, enabling human motion synthesis through intuitive inputs like text prompts or kinematic constraints on poses. However, the small scale of public mocap datasets has limited the motion quality, control accuracy, and generalization of these models. In this work, we introduce Kimodo, an expressive and controllable kinematic motion diffusion model trained on 700 hours of optical motion capture data. Our model generates high-quality motions while being easily controlled through text and a comprehensive suite of kinematic constraints including full-body keyframes, sparse joint positions/rotations, 2D waypoints, and dense 2D paths. This is enabled through a carefully designed motion representation and two-stage denoiser architecture that decomposes root and body prediction to minimize motion artifacts while allowing for flexible constraint conditioning. Experiments on the large-scale mocap dataset justify key design decisions and analyze how the scaling of dataset size and model size affect performance.
Noise-Aware Generative Microscopic Traffic Simulation
Aug 10, 2025Accurately modeling individual vehicle behavior in microscopic traffic simulation remains a key challenge in intelligent transportation systems, as it requires vehicles to realistically generate and respond to complex traffic phenomena such as phantom traffic jams. While traditional human driver simulation models offer computational tractability, they do so by abstracting away the very complexity that defines human driving. On the other hand, recent advances in infrastructure-mounted camera-based roadway sensing have enabled the extraction of vehicle trajectory data, presenting an opportunity to shift toward generative, agent-based models. Yet, a major bottleneck remains: most existing datasets are either overly sanitized or lack standardization, failing to reflect the noisy, imperfect nature of real-world sensing. Unlike data from vehicle-mounted sensors-which can mitigate sensing artifacts like occlusion through overlapping fields of view and sensor fusion-infrastructure-based sensors surface a messier, more practical view of challenges that traffic engineers encounter. To this end, we present the I-24 MOTION Scenario Dataset (I24-MSD)-a standardized, curated dataset designed to preserve a realistic level of sensor imperfection, embracing these errors as part of the learning problem rather than an obstacle to overcome purely from preprocessing. Drawing from noise-aware learning strategies in computer vision, we further adapt existing generative models in the autonomous driving community for I24-MSD with noise-aware loss functions. Our results show that such models not only outperform traditional baselines in realism but also benefit from explicitly engaging with, rather than suppressing, data imperfection. We view I24-MSD as a stepping stone toward a new generation of microscopic traffic simulation that embraces the real-world challenges and is better aligned with practical needs.
GMT: General Motion Tracking for Humanoid Whole-Body Control
Jun 17, 2025The ability to track general whole-body motions in the real world is a useful way to build general-purpose humanoid robots. However, achieving this can be challenging due to the temporal and kinematic diversity of the motions, the policy's capability, and the difficulty of coordination of the upper and lower bodies. To address these issues, we propose GMT, a general and scalable motion-tracking framework that trains a single unified policy to enable humanoid robots to track diverse motions in the real world. GMT is built upon two core components: an Adaptive Sampling strategy and a Motion Mixture-of-Experts (MoE) architecture. The Adaptive Sampling automatically balances easy and difficult motions during training. The MoE ensures better specialization of different regions of the motion manifold. We show through extensive experiments in both simulation and the real world the effectiveness of GMT, achieving state-of-the-art performance across a broad spectrum of motions using a unified general policy. Videos and additional information can be found at https://gmt-humanoid.github.io.
LeVERB: Humanoid Whole-Body Control with Latent Vision-Language Instruction
Jun 16, 2025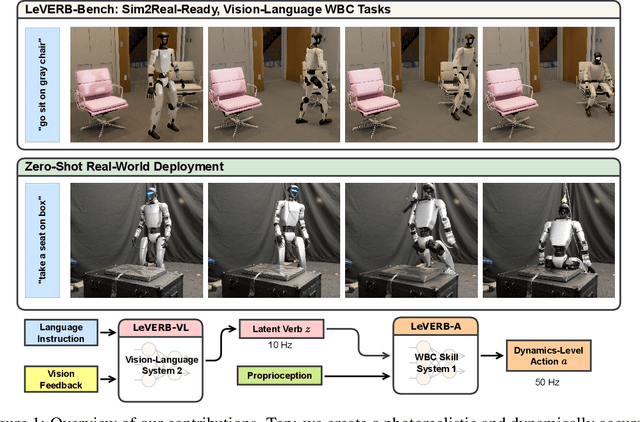
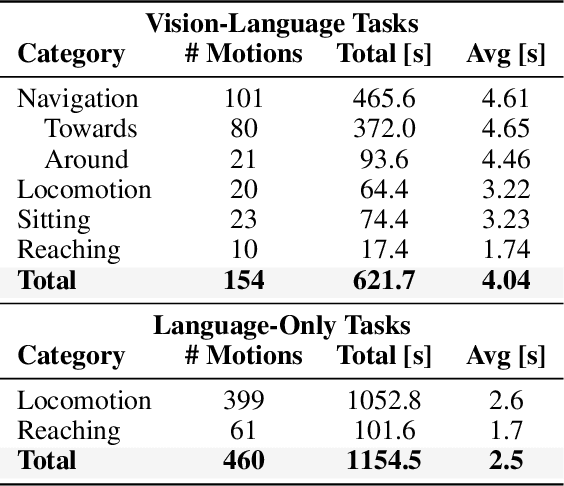
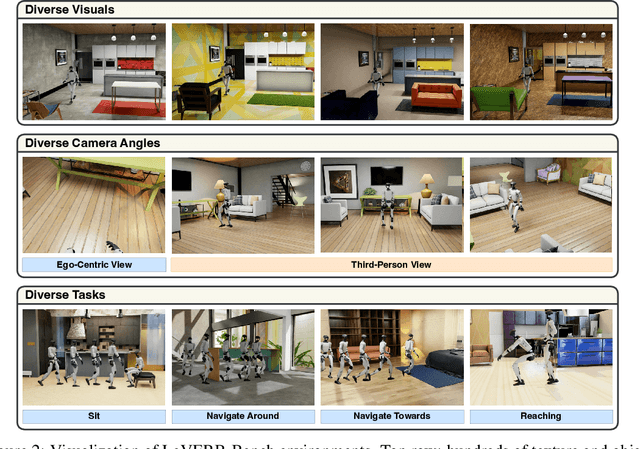
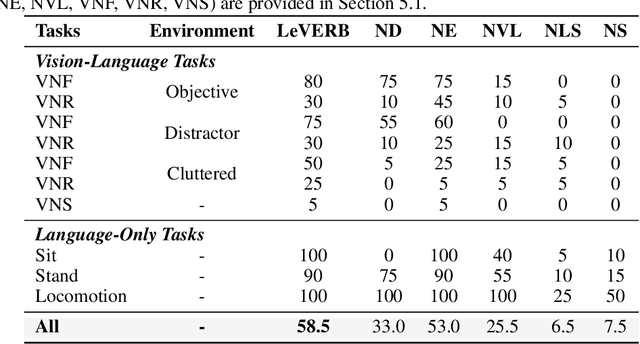
Vision-language-action (VLA) models have demonstrated strong semantic understanding and zero-shot generalization, yet most existing systems assume an accurate low-level controller with hand-crafted action "vocabulary" such as end-effector pose or root velocity. This assumption confines prior work to quasi-static tasks and precludes the agile, whole-body behaviors required by humanoid whole-body control (WBC) tasks. To capture this gap in the literature, we start by introducing the first sim-to-real-ready, vision-language, closed-loop benchmark for humanoid WBC, comprising over 150 tasks from 10 categories. We then propose LeVERB: Latent Vision-Language-Encoded Robot Behavior, a hierarchical latent instruction-following framework for humanoid vision-language WBC, the first of its kind. At the top level, a vision-language policy learns a latent action vocabulary from synthetically rendered kinematic demonstrations; at the low level, a reinforcement-learned WBC policy consumes these latent verbs to generate dynamics-level commands. In our benchmark, LeVERB can zero-shot attain a 80% success rate on simple visual navigation tasks, and 58.5% success rate overall, outperforming naive hierarchical whole-body VLA implementation by 7.8 times.
MaskedManipulator: Versatile Whole-Body Control for Loco-Manipulation
May 25, 2025Humans interact with their world while leveraging precise full-body control to achieve versatile goals. This versatility allows them to solve long-horizon, underspecified problems, such as placing a cup in a sink, by seamlessly sequencing actions like approaching the cup, grasping, transporting it, and finally placing it in the sink. Such goal-driven control can enable new procedural tools for animation systems, enabling users to define partial objectives while the system naturally ``fills in'' the intermediate motions. However, while current methods for whole-body dexterous manipulation in physics-based animation achieve success in specific interaction tasks, they typically employ control paradigms (e.g., detailed kinematic motion tracking, continuous object trajectory following, or direct VR teleoperation) that offer limited versatility for high-level goal specification across the entire coupled human-object system. To bridge this gap, we present MaskedManipulator, a unified and generative policy developed through a two-stage learning approach. First, our system trains a tracking controller to physically reconstruct complex human-object interactions from large-scale human mocap datasets. This tracking controller is then distilled into MaskedManipulator, which provides users with intuitive control over both the character's body and the manipulated object. As a result, MaskedManipulator enables users to specify complex loco-manipulation tasks through intuitive high-level objectives (e.g., target object poses, key character stances), and MaskedManipulator then synthesizes the necessary full-body actions for a physically simulated humanoid to achieve these goals, paving the way for more interactive and life-like virtual characters.
ADD: Physics-Based Motion Imitation with Adversarial Differential Discriminators
May 08, 2025



Multi-objective optimization problems, which require the simultaneous optimization of multiple terms, are prevalent across numerous applications. Existing multi-objective optimization methods often rely on manually tuned aggregation functions to formulate a joint optimization target. The performance of such hand-tuned methods is heavily dependent on careful weight selection, a time-consuming and laborious process. These limitations also arise in the setting of reinforcement-learning-based motion tracking for physically simulated characters, where intricately crafted reward functions are typically used to achieve high-fidelity results. Such solutions not only require domain expertise and significant manual adjustment, but also limit the applicability of the resulting reward function across diverse skills. To bridge this gap, we present a novel adversarial multi-objective optimization technique that is broadly applicable to a range of multi-objective optimization problems, including motion tracking. The proposed adversarial differential discriminator receives a single positive sample, yet is still effective at guiding the optimization process. We demonstrate that our technique can enable characters to closely replicate a variety of acrobatic and agile behaviors, achieving comparable quality to state-of-the-art motion-tracking methods, without relying on manually tuned reward functions. Results are best visualized through https://youtu.be/rz8BYCE9E2w.
StableMotion: Training Motion Cleanup Models with Unpaired Corrupted Data
May 06, 2025
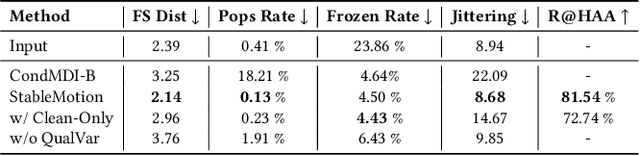
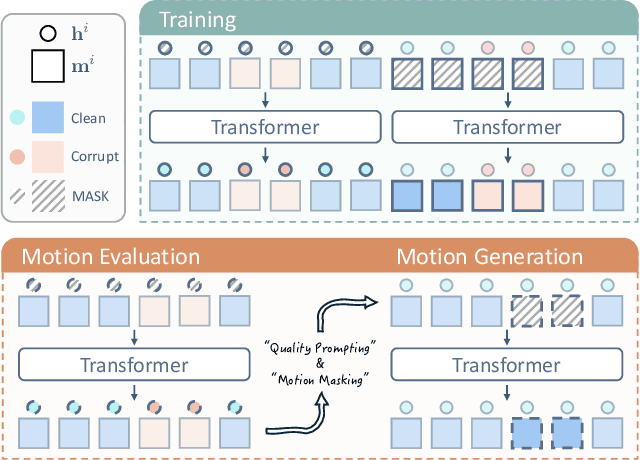
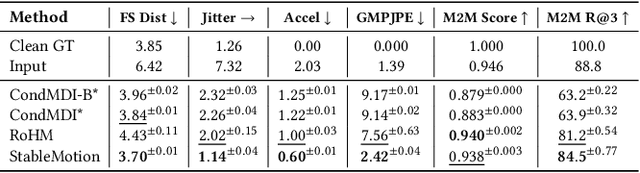
Motion capture (mocap) data often exhibits visually jarring artifacts due to inaccurate sensors and post-processing. Cleaning this corrupted data can require substantial manual effort from human experts, which can be a costly and time-consuming process. Previous data-driven motion cleanup methods offer the promise of automating this cleanup process, but often require in-domain paired corrupted-to-clean training data. Constructing such paired datasets requires access to high-quality, relatively artifact-free motion clips, which often necessitates laborious manual cleanup. In this work, we present StableMotion, a simple yet effective method for training motion cleanup models directly from unpaired corrupted datasets that need cleanup. The core component of our method is the introduction of motion quality indicators, which can be easily annotated through manual labeling or heuristic algorithms and enable training of quality-aware motion generation models on raw motion data with mixed quality. At test time, the model can be prompted to generate high-quality motions using the quality indicators. Our method can be implemented through a simple diffusion-based framework, leading to a unified motion generate-discriminate model, which can be used to both identify and fix corrupted frames. We demonstrate that our proposed method is effective for training motion cleanup models on raw mocap data in production scenarios by applying StableMotion to SoccerMocap, a 245-hour soccer mocap dataset containing real-world motion artifacts. The trained model effectively corrects a wide range of motion artifacts, reducing motion pops and frozen frames by 68% and 81%, respectively. See https://youtu.be/3Y7MMAH02B4 for more results.
PARC: Physics-based Augmentation with Reinforcement Learning for Character Controllers
May 06, 2025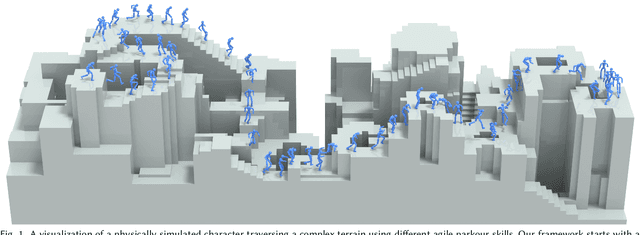
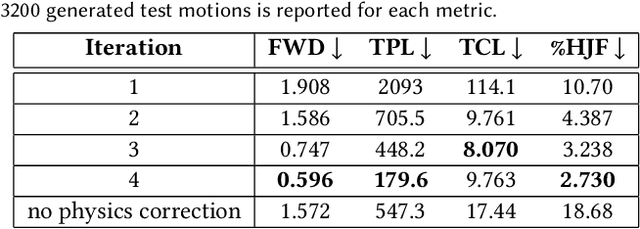

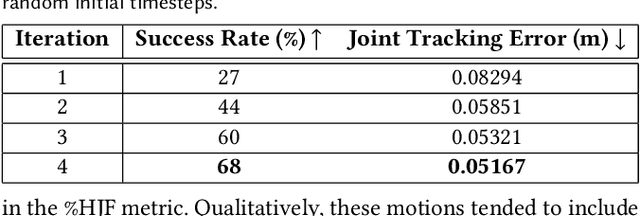
Humans excel in navigating diverse, complex environments with agile motor skills, exemplified by parkour practitioners performing dynamic maneuvers, such as climbing up walls and jumping across gaps. Reproducing these agile movements with simulated characters remains challenging, in part due to the scarcity of motion capture data for agile terrain traversal behaviors and the high cost of acquiring such data. In this work, we introduce PARC (Physics-based Augmentation with Reinforcement Learning for Character Controllers), a framework that leverages machine learning and physics-based simulation to iteratively augment motion datasets and expand the capabilities of terrain traversal controllers. PARC begins by training a motion generator on a small dataset consisting of core terrain traversal skills. The motion generator is then used to produce synthetic data for traversing new terrains. However, these generated motions often exhibit artifacts, such as incorrect contacts or discontinuities. To correct these artifacts, we train a physics-based tracking controller to imitate the motions in simulation. The corrected motions are then added to the dataset, which is used to continue training the motion generator in the next iteration. PARC's iterative process jointly expands the capabilities of the motion generator and tracker, creating agile and versatile models for interacting with complex environments. PARC provides an effective approach to develop controllers for agile terrain traversal, which bridges the gap between the scarcity of motion data and the need for versatile character controllers.
TWIST: Teleoperated Whole-Body Imitation System
May 05, 2025Teleoperating humanoid robots in a whole-body manner marks a fundamental step toward developing general-purpose robotic intelligence, with human motion providing an ideal interface for controlling all degrees of freedom. Yet, most current humanoid teleoperation systems fall short of enabling coordinated whole-body behavior, typically limiting themselves to isolated locomotion or manipulation tasks. We present the Teleoperated Whole-Body Imitation System (TWIST), a system for humanoid teleoperation through whole-body motion imitation. We first generate reference motion clips by retargeting human motion capture data to the humanoid robot. We then develop a robust, adaptive, and responsive whole-body controller using a combination of reinforcement learning and behavior cloning (RL+BC). Through systematic analysis, we demonstrate how incorporating privileged future motion frames and real-world motion capture (MoCap) data improves tracking accuracy. TWIST enables real-world humanoid robots to achieve unprecedented, versatile, and coordinated whole-body motor skills--spanning whole-body manipulation, legged manipulation, locomotion, and expressive movement--using a single unified neural network controller. Our project website: https://humanoid-teleop.github.io