 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Aware Generative Microscopic Traffic Simulation
Aug 10, 2025Accurately modeling individual vehicle behavior in microscopic traffic simulation remains a key challenge in intelligent transportation systems, as it requires vehicles to realistically generate and respond to complex traffic phenomena such as phantom traffic jams. While traditional human driver simulation models offer computational tractability, they do so by abstracting away the very complexity that defines human driving. On the other hand, recent advances in infrastructure-mounted camera-based roadway sensing have enabled the extraction of vehicle trajectory data, presenting an opportunity to shift toward generative, agent-based models. Yet, a major bottleneck remains: most existing datasets are either overly sanitized or lack standardization, failing to reflect the noisy, imperfect nature of real-world sensing. Unlike data from vehicle-mounted sensors-which can mitigate sensing artifacts like occlusion through overlapping fields of view and sensor fusion-infrastructure-based sensors surface a messier, more practical view of challenges that traffic engineers encounter. To this end, we present the I-24 MOTION Scenario Dataset (I24-MSD)-a standardized, curated dataset designed to preserve a realistic level of sensor imperfection, embracing these errors as part of the learning problem rather than an obstacle to overcome purely from preprocessing. Drawing from noise-aware learning strategies in computer vision, we further adapt existing generative models in the autonomous driving community for I24-MSD with noise-aware loss functions. Our results show that such models not only outperform traditional baselines in realism but also benefit from explicitly engaging with, rather than suppressing, data imperfection. We view I24-MSD as a stepping stone toward a new generation of microscopic traffic simulation that embraces the real-world challenges and is better aligned with practical needs.
A Roadmap for Climate-Relevant Robotics Research
Jul 15, 2025



Climate change is one of the defining challenges of the 21st century, and many in the robotics community are looking for ways to contribute. This paper presents a roadmap for climate-relevant robotics research, identifying high-impact opportunities for collaboration between roboticists and experts across climate domains such as energy, the built environment, transportation, industry, land use, and Earth sciences. These applications include problems such as energy systems optimization, construction, precision agriculture, building envelope retrofits, autonomous trucking, and large-scale environmental monitoring. Critically, we include opportunities to apply not only physical robots but also the broader robotics toolkit - including planning, perception, control, and estimation algorithms - to climate-relevant problems. A central goal of this roadmap is to inspire new research directions and collaboration by highlighting specific, actionable problems at the intersection of robotics and climate. This work represents a collaboration between robotics researchers and domain experts in various climate disciplines, and it serves as an invitation to the robotics community to bring their expertise to bear on urgent climate priorities.
NeuralMOVES: A lightweight and microscopic vehicle emission estimation model based on reverse engineering and surrogate learning
Feb 06, 2025



The transportation sector significantly contributes to greenhouse gas emissions, necessitating accurate emission models to guide mitigation strategies. Despite its field validation and certification, the industry-standard Motor Vehicle Emission Simulator (MOVES) faces challenges related to complexity in usage, high computational demands, and its unsuitability for microscopic real-time applications. To address these limitations, we present NeuralMOVES, a comprehensive suite of high-performance, lightweight surrogate models for vehicle CO2 emissions. Developed based on reverse engineering and Neural Networks, NeuralMOVES achieves a remarkable 6.013% Mean Average Percentage Error relative to MOVES across extensive tests spanning over two million scenarios with diverse trajectories and the factors regarding environments and vehicles. NeuralMOVES is only 2.4 MB, largely condensing the original MOVES and the reverse engineered MOVES into a compact representation, while maintaining high accuracy. Therefore, NeuralMOVES significantly enhances accessibility while maintaining the accuracy of MOVES, simplifying CO2 evaluation for transportation analyses and enabling real-time, microscopic applications across diverse scenarios without reliance on complex software or extensive computational resources. Moreover, this paper provides, for the first time, a framework for reverse engineering industrial-grade software tailored specifically to transportation scenarios, going beyond MOVES. The surrogate models are available at https://github.com/edgar-rs/neuralMOVES.
IntersectionZoo: Eco-driving for Benchmarking Multi-Agent Contextual Reinforcement Learning
Oct 19, 2024Despite the popularity of multi-agent reinforcement learning (RL) in simulated and two-player applications, its success in messy real-world applications has been limited. A key challenge lies in its generalizability across problem variations, a common necessity for many real-world problems. Contextual reinforcement learning (CRL) formalizes learning policies that generalize across problem variations. However, the lack of standardized benchmarks for multi-agent CRL has hindered progress in the field. Such benchmarks are desired to be based on real-world applications to naturally capture the many open challenges of real-world problems that affect generalization. To bridge this gap, we propose IntersectionZoo, a comprehensive benchmark suite for multi-agent CRL through the real-world application of cooperative eco-driving in urban road networks. The task of cooperative eco-driving is to control a fleet of vehicles to reduce fleet-level vehicular emissions. By grounding IntersectionZoo in a real-world application, we naturally capture real-world problem characteristics, such as partial observability and multiple competing objectives. IntersectionZoo is built on data-informed simulations of 16,334 signalized intersections derived from 10 major US cities, modeled in an open-source industry-grade microscopic traffic simulator. By modeling factors affecting vehicular exhaust emissions (e.g., temperature, road conditions, travel demand), IntersectionZoo provides one million data-driven traffic scenarios. Using these traffic scenarios, we benchmark popular multi-agent RL and human-like driving algorithms and demonstrate that the popular multi-agent RL algorithms struggle to generalize in CRL settings.
Mitigating Metropolitan Carbon Emissions with Dynamic Eco-driving at Scale
Aug 10, 2024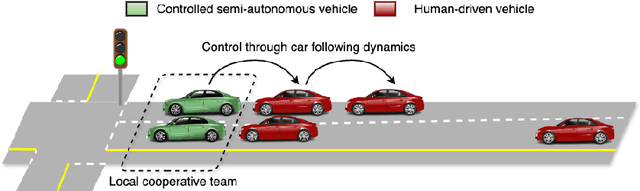
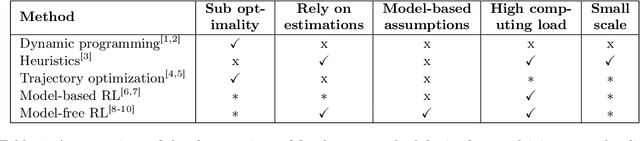
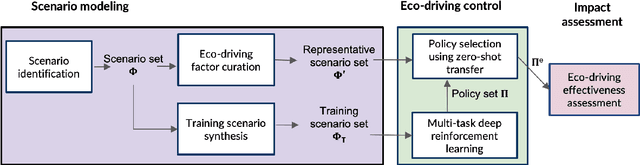
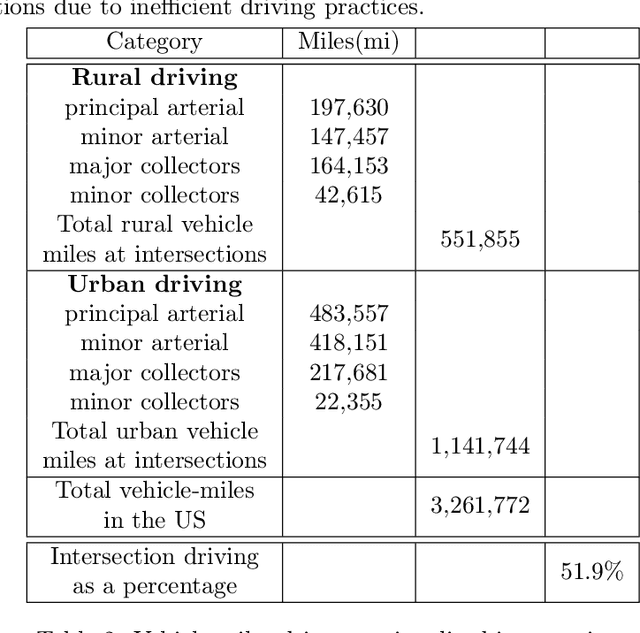
The sheer scale and diversity of transportation make it a formidable sector to decarbonize. Here, we consider an emerging opportunity to reduce carbon emissions: the growing adoption of semi-autonomous vehicles, which can be programmed to mitigate stop-and-go traffic through intelligent speed commands and, thus, reduce emissions. But would such dynamic eco-driving move the needle on climate change? A comprehensive impact analysis has been out of reach due to the vast array of traffic scenarios and the complexity of vehicle emissions. We address this challenge with large-scale scenario modeling efforts and by using multi-task deep reinforcement learning with a carefully designed network decomposition strategy. We perform an in-depth prospective impact assessment of dynamic eco-driving at 6,011 signalized intersections across three major US metropolitan cities, simulating a million traffic scenarios. Overall, we find that vehicle trajectories optimized for emissions can cut city-wide intersection carbon emissions by 11-22%, without harming throughput or safety, and with reasonable assumptions, equivalent to the national emissions of Israel and Nigeria, respectively. We find that 10% eco-driving adoption yields 25%-50% of the total reduction, and nearly 70% of the benefits come from 20% of intersections, suggesting near-term implementation pathways. However, the composition of this high-impact subset of intersections varies considerably across different adoption levels, with minimal overlap, calling for careful strategic planning for eco-driving deployments. Moreover, the impact of eco-driving, when considered jointly with projections of vehicle electrification and hybrid vehicle adoption remains significant. More broadly, this work paves the way for large-scale analysis of traffic externalities, such as time, safety, and air quality, and the potential impact of solution strategies.
Model-Based Transfer Learning for Contextual Reinforcement Learning
Aug 08, 2024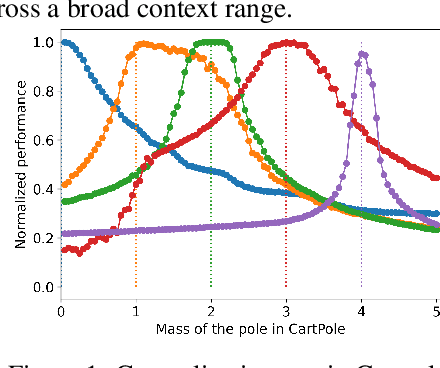
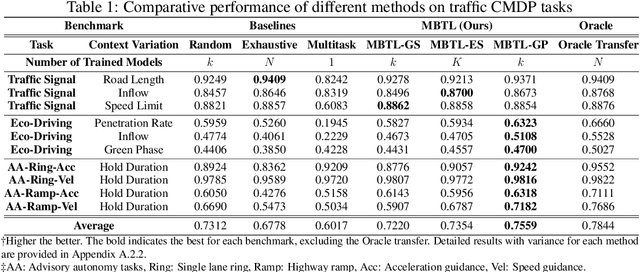
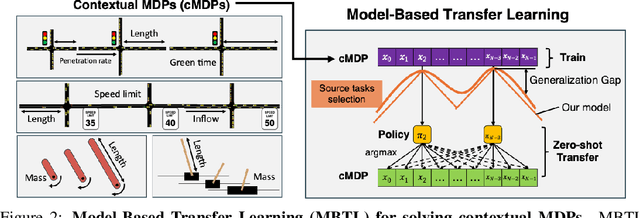
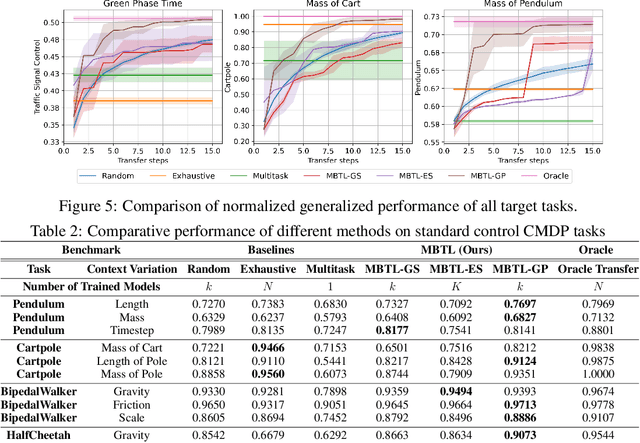
Deep reinforcement learning is a powerful approach to complex decision making. However, one issue that limits its practical application is its brittleness, sometimes failing to train in the presence of small changes in the environment. This work is motivated by the empirical observation that directly applying an already trained model to a related task often works remarkably well, also called zero-shot transfer. We take this practical trick one step further to consider how to systematically select good tasks to train, maximizing overall performance across a range of tasks. Given the high cost of training, it is critical to choose a small set of training tasks. The key idea behind our approach is to explicitly model the performance loss (generalization gap) incurred by transferring a trained model. We hence introduce Model-Based Transfer Learning (MBTL) for solving contextual RL problems. In this work, we model the performance loss as a simple linear function of task context similarity. Furthermore, we leverage Bayesian optimization techniques to efficiently model and estimate the unknown training performance of the task space. We theoretically show that the method exhibits regret that is sublinear in the number of training tasks and discuss conditions to further tighten regret bounds. We experimentally validate our methods using urban traffic and standard control benchmarks. Despite the conceptual simplicity, the experimental results suggest that MBTL can achieve greater performance than strong baselines, including exhaustive training on all tasks, multi-task training, and random selection of training tasks. This work lays the foundations for investigating explicit modeling of generalization, thereby enabling principled yet effective methods for contextual RL.
Generalizing Cooperative Eco-driving via Multi-residual Task Learning
Mar 07, 2024
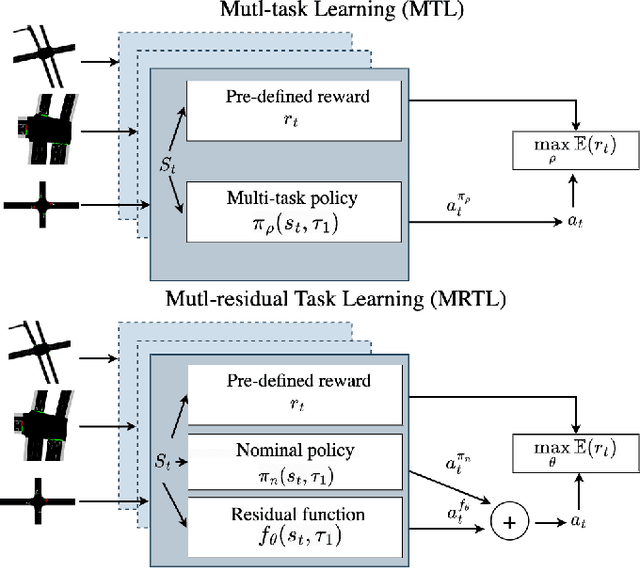
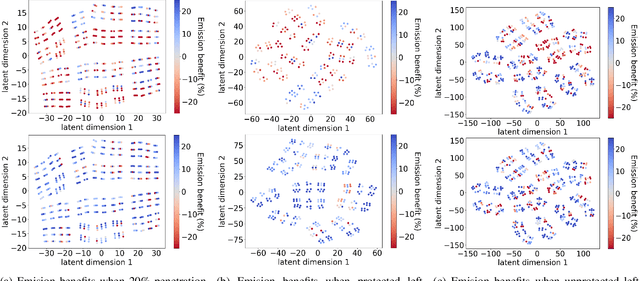
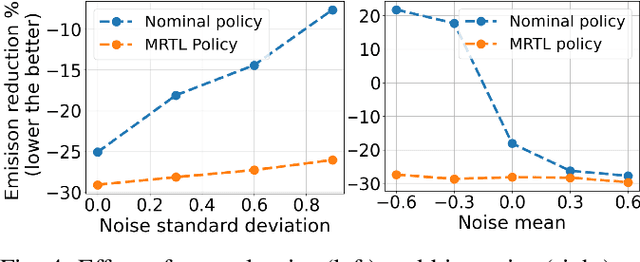
Conventional control, such as model-based control, is commonly utilized in autonomous driving due to its efficiency and reliability. However, real-world autonomous driving contends with a multitude of diverse traffic scenarios that are challenging for these planning algorithms. Model-free Deep Reinforcement Learning (DRL) presents a promising avenue in this direction, but learning DRL control policies that generalize to multiple traffic scenarios is still a challenge. To address this, we introduce Multi-residual Task Learning (MRTL), a generic learning framework based on multi-task learning that, for a set of task scenarios, decomposes the control into nominal components that are effectively solved by conventional control methods and residual terms which are solved using learning. We employ MRTL for fleet-level emission reduction in mixed traffic using autonomous vehicles as a means of system control. By analyzing the performance of MRTL across nearly 600 signalized intersections and 1200 traffic scenarios, we demonstrate that it emerges as a promising approach to synergize the strengths of DRL and conventional methods in generalizable control.
Model-free Learning of Corridor Clearance: A Near-term Deployment Perspective
Dec 16, 2023An emerging public health application of connected and automated vehicle (CAV) technologies is to reduce response times of emergency medical service (EMS) by indirectly coordinating traffic. Therefore, in this work we study the CAV-assisted corridor clearance for EMS vehicles from a short term deployment perspective. Existing research on this topic often overlooks the impact of EMS vehicle disruptions on regular traffic, assumes 100% CAV penetration, relies on real-time traffic signal timing data and queue lengths at intersections, and makes various assumptions about traffic settings when deriving optimal model-based CAV control strategies. However, these assumptions pose significant challenges for near-term deployment and limit the real-world applicability of such methods. To overcome these challenges and enhance real-world applicability in near-term, we propose a model-free approach employing deep reinforcement learning (DRL) for designing CAV control strategies, showing its reduced overhead in designing and greater scalability and performance compared to model-based methods. Our qualitative analysis highlights the complexities of designing scalable EMS corridor clearance controllers for diverse traffic settings in which DRL controller provides ease of design compared to the model-based methods. In numerical evaluations, the model-free DRL controller outperforms the model-based counterpart by improving traffic flow and even improving EMS travel times in scenarios when a single CAV is present. Across 19 considered settings, the learned DRL controller excels by 25% in reducing the travel time in six instances, achieving an average improvement of 9%. These findings underscore the potential and promise of model-free DRL strategies in advancing EMS response and traffic flow coordination, with a focus on practical near-term deployment.
The Impact of Task Underspecification in Evaluating Deep Reinforcement Learning
Oct 16, 2022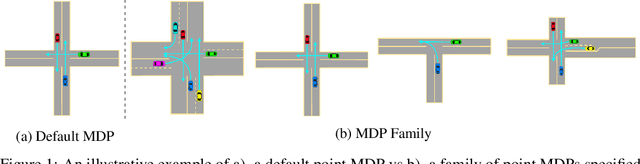

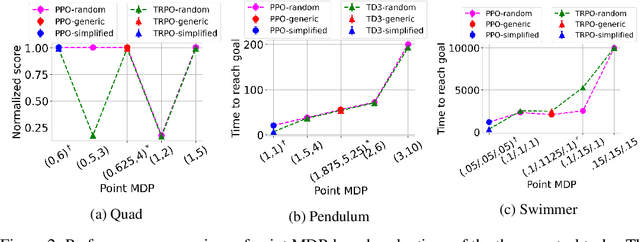
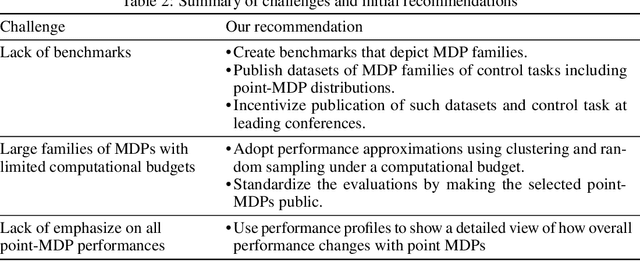
Evaluations of Deep Reinforcement Learning (DRL) methods are an integral part of scientific progress of the field. Beyond designing DRL methods for general intelligence, designing task-specific methods is becoming increasingly prominent for real-world applications. In these settings, the standard evaluation practice involves using a few instances of Markov Decision Processes (MDPs) to represent the task. However, many tasks induce a large family of MDPs owing to variations in the underlying environment, particularly in real-world contexts. For example, in traffic signal control, variations may stem from intersection geometries and traffic flow levels. The select MDP instances may thus inadvertently cause overfitting, lacking the statistical power to draw conclusions about the method's true performance across the family. In this article, we augment DRL evaluations to consider parameterized families of MDPs. We show that in comparison to evaluating DRL methods on select MDP instances, evaluating the MDP family often yields a substantially different relative ranking of methods, casting doubt on what methods should be considered state-of-the-art. We validate this phenomenon in standard control benchmarks and the real-world application of traffic signal control. At the same time, we show that accurately evaluating on an MDP family is nontrivial. Overall, this work identifies new challenges for empirical rigor in reinforcement learning, especially as the outcomes of DRL trickle into downstream decision-making.
Learning Eco-Driving Strategies at Signalized Intersections
Apr 26, 2022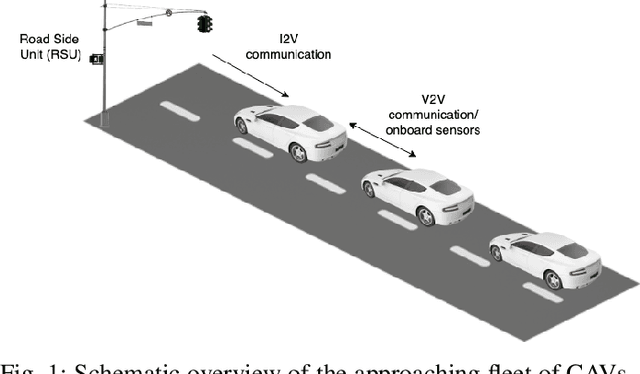
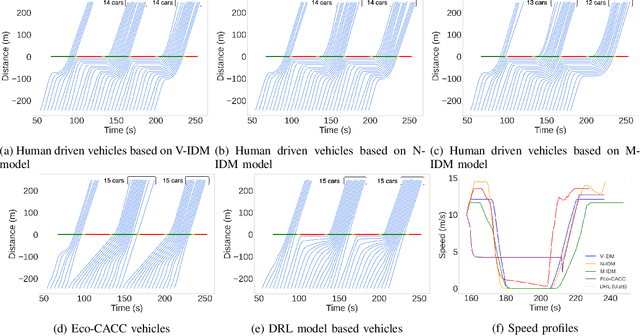
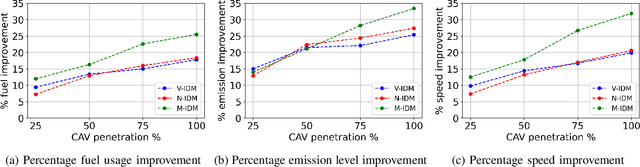
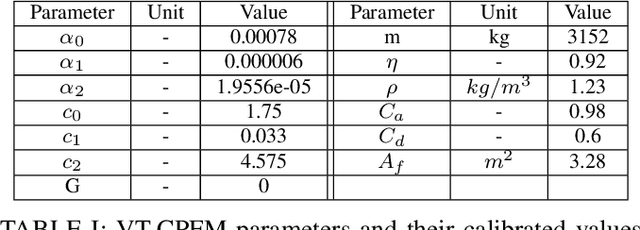
Signalized intersections in arterial roads result in persistent vehicle idling and excess accelerations, contributing to fuel consumption and CO2 emissions. There has thus been a line of work studying eco-driving control strategies to reduce fuel consumption and emission levels at intersections. However, methods to devise effective control strategies across a variety of traffic settings remain elusive. In this paper, we propose a reinforcement learning (RL) approach to learn effective eco-driving control strategies. We analyze the potential impact of a learned strategy on fuel consumption, CO2 emission, and travel time and compare with naturalistic driving and model-based baselines. We further demonstrate the generalizability of the learned policies under mixed traffic scenarios. Simulation results indicate that scenarios with 100% penetration of connected autonomous vehicles (CAV) may yield as high as 18% reduction in fuel consumption and 25% reduction in CO2 emission levels while even improving travel speed by 20%. Furthermore, results indicate that even 25% CAV penetration can bring at least 50% of the total fuel and emission reduction benefits.